 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHateRephrase: Zero- and Few-Shot Reduction of Hate Intensity in Online Posts using Large Language Models
Paper and Code
Oct 21, 2023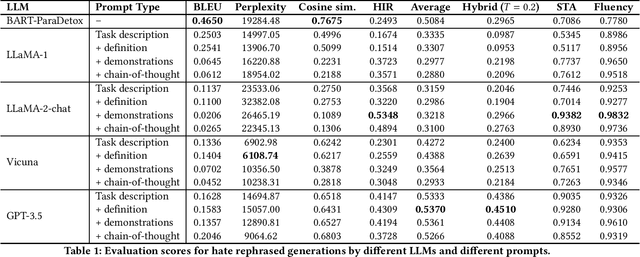
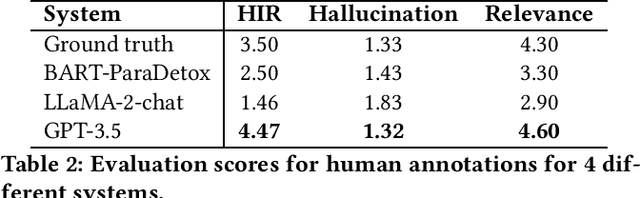


Hate speech has become pervasive in today's digital age. Although there has been considerable research to detect hate speech or generate counter speech to combat hateful views, these approaches still cannot completely eliminate the potential harmful societal consequences of hate speech -- hate speech, even when detected, can often not be taken down or is often not taken down enough; and hate speech unfortunately spreads quickly, often much faster than any generated counter speech. This paper investigates a relatively new yet simple and effective approach of suggesting a rephrasing of potential hate speech content even before the post is made. We show that Large Language Models (LLMs) perform well on this task, outperforming state-of-the-art baselines such as BART-Detox. We develop 4 different prompts based on task description, hate definition, few-shot demonstrations and chain-of-thoughts for comprehensive experiments and conduct experiments on open-source LLMs such as LLaMA-1, LLaMA-2 chat, Vicuna as well as OpenAI's GPT-3.5. We propose various evaluation metrics to measure the efficacy of the generated text and ensure the generated text has reduced hate intensity without drastically changing the semantic meaning of the original text. We find that LLMs with a few-shot demonstrations prompt work the best in generating acceptable hate-rephrased text with semantic meaning similar to the original text. Overall, we find that GPT-3.5 outperforms the baseline and open-source models for all the different kinds of prompts. We also perform human evaluations and interestingly, find that the rephrasings generated by GPT-3.5 outperform even the human-generated ground-truth rephrasings in the dataset. We also conduct detailed ablation studies to investigate why LLMs work satisfactorily on this task and conduct a failure analysis to understand the gaps.