 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Fraud Detection on Non-attributed Graph
Paper and Code
Oct 04, 2021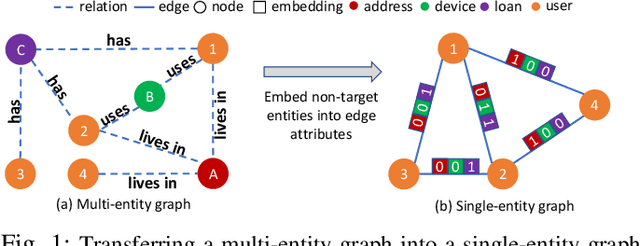
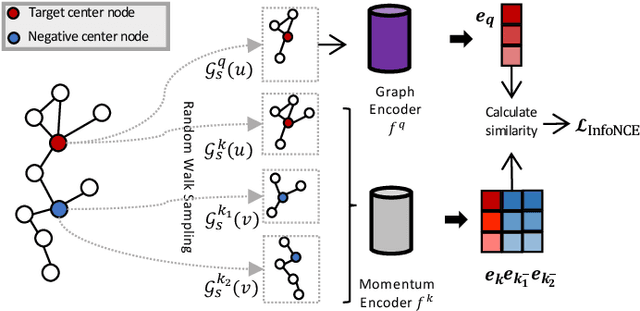
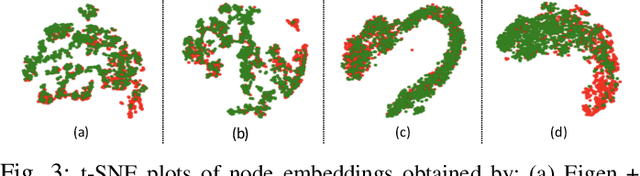

Fraud detection problems are usually formulated as a machine learning problem on a graph. Recently, Graph Neural Networks (GNNs) have shown solid performance on fraud detection. The successes of most previous methods heavily rely on rich node features and high-fidelity labels. However, labeled data is scarce in large-scale industrial problems, especially for fraud detection where new patterns emerge from time to time. Meanwhile, node features are also limited due to privacy and other constraints. In this paper, two improvements are proposed: 1) We design a graph transformation method capturing the structural information to facilitate GNNs on non-attributed fraud graphs. 2) We propose a novel graph pre-training strategy to leverage more unlabeled data via contrastive learning. Experiments on a large-scale industrial dataset demonstrate the effectiveness of the proposed framework for fraud detection.