 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDualRAG: A Dual-Process Approach to Integrate Reasoning and Retrieval for Multi-Hop Question Answering
Apr 25, 2025Multi-Hop Question Answering (MHQA) tasks permeate real-world applications, posing challenges in orchestrating multi-step reasoning across diverse knowledge domains. While existing approaches have been improved with iterative retrieval, they still struggle to identify and organize dynamic knowledge. To address this, we propose DualRAG, a synergistic dual-process framework that seamlessly integrates reasoning and retrieval. DualRAG operates through two tightly coupled processes: Reasoning-augmented Querying (RaQ) and progressive Knowledge Aggregation (pKA). They work in concert: as RaQ navigates the reasoning path and generates targeted queries, pKA ensures that newly acquired knowledge is systematically integrated to support coherent reasoning. This creates a virtuous cycle of knowledge enrichment and reasoning refinement. Through targeted fine-tuning, DualRAG preserves its sophisticated reasoning and retrieval capabilities even in smaller-scale models, demonstrating its versatility and core advantages across different scales. Extensive experiments demonstrate that this dual-process approach substantially improves answer accuracy and coherence, approaching, and in some cases surpassing, the performance achieved with oracle knowledge access. These results establish DualRAG as a robust and efficient solution for complex multi-hop reasoning tasks.
What About Taking Policy as Input of Value Function: Policy-extended Value Function Approximator
Oct 19, 2020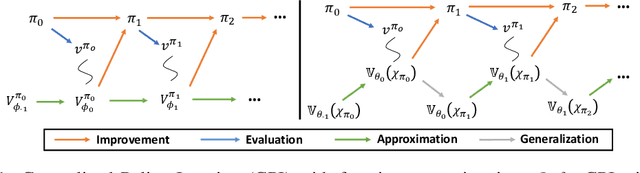

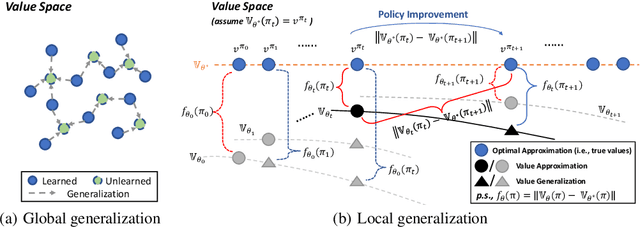
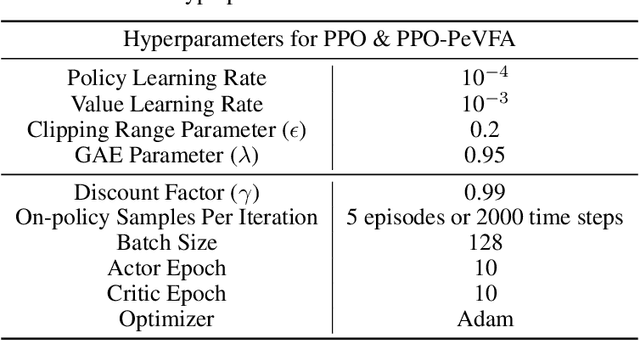
The value function lies in the heart of Reinforcement Learning (RL), which defines the long-term evaluation of a policy in a given state. In this paper, we propose Policy-extended Value Function Approximator (PeVFA) which extends the conventional value to be not only a function of state but also an explicit policy representation. Such an extension enables PeVFA to preserve values of multiple policies in contrast to a conventional one with limited capacity for only one policy, inducing the new characteristic of \emph{value generalization among policies}. From both the theoretical and empirical lens, we study value generalization along the policy improvement path (called local generalization), from which we derive a new form of Generalized Policy Iteration with PeVFA to improve the conventional learning process. Besides, we propose a framework to learn the representation of an RL policy, studying several different approaches to learn an effective policy representation from policy network parameters and state-action pairs through contrastive learning and action prediction. In our experiments, Proximal Policy Optimization (PPO) with PeVFA significantly outperforms its vanilla counterpart in MuJoCo continuous control tasks, demonstrating the effectiveness of value generalization offered by PeVFA and policy representation learning.