 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMFE-ETP: A Comprehensive Evaluation Benchmark for Multi-modal Foundation Models on Embodied Task Planning
Jul 06, 2024In recent years, Multi-modal Foundation Models (MFMs) and Embodied Artificial Intelligence (EAI) have been advancing side by side at an unprecedented pace. The integration of the two has garnered significant attention from the AI research community. In this work, we attempt to provide an in-depth and comprehensive evaluation of the performance of MFM s on embodied task planning, aiming to shed light on their capabilities and limitations in this domain. To this end, based on the characteristics of embodied task planning, we first develop a systematic evaluation framework, which encapsulates four crucial capabilities of MFMs: object understanding, spatio-temporal perception, task understanding, and embodied reasoning. Following this, we propose a new benchmark, named MFE-ETP, characterized its complex and variable task scenarios, typical yet diverse task types, task instances of varying difficulties, and rich test case types ranging from multiple embodied question answering to embodied task reasoning. Finally, we offer a simple and easy-to-use automatic evaluation platform that enables the automated testing of multiple MFMs on the proposed benchmark. Using the benchmark and evaluation platform, we evaluated several state-of-the-art MFMs and found that they significantly lag behind human-level performance. The MFE-ETP is a high-quality, large-scale, and challenging benchmark relevant to real-world tasks.
Bridging Evolutionary Algorithms and Reinforcement Learning: A Comprehensive Survey
Jan 22, 2024Evolutionary Reinforcement Learning (ERL), which integrates Evolutionary Algorithms (EAs) and Reinforcement Learning (RL) for optimization, has demonstrated remarkable performance advancements. By fusing the strengths of both approaches, ERL has emerged as a promising research direction. This survey offers a comprehensive overview of the diverse research branches in ERL. Specifically, we systematically summarize recent advancements in relevant algorithms and identify three primary research directions: EA-assisted optimization of RL, RL-assisted optimization of EA, and synergistic optimization of EA and RL. Following that, we conduct an in-depth analysis of each research direction, organizing multiple research branches. We elucidate the problems that each branch aims to tackle and how the integration of EA and RL addresses these challenges. In conclusion, we discuss potential challenges and prospective future research directions across various research directions.
ERL-Re$^2$: Efficient Evolutionary Reinforcement Learning with Shared State Representation and Individual Policy Representation
Oct 26, 2022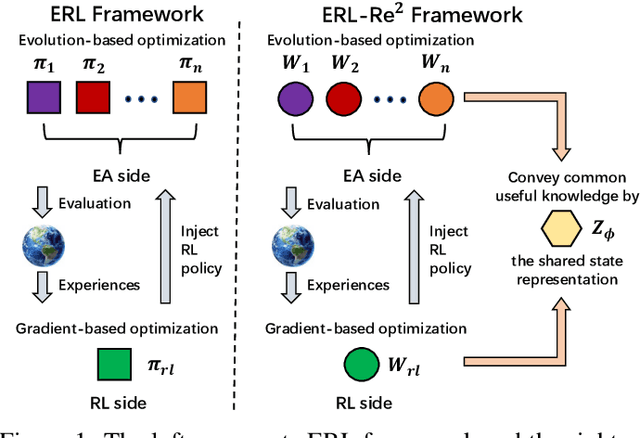
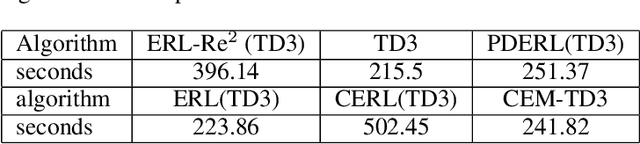
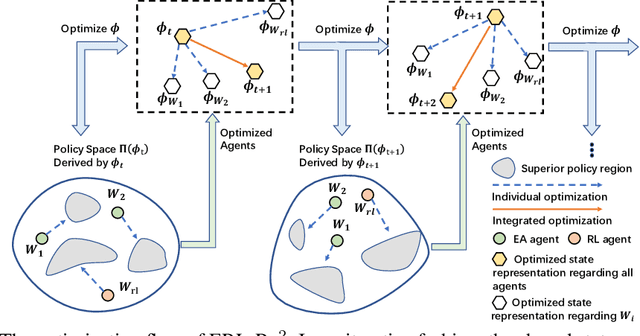
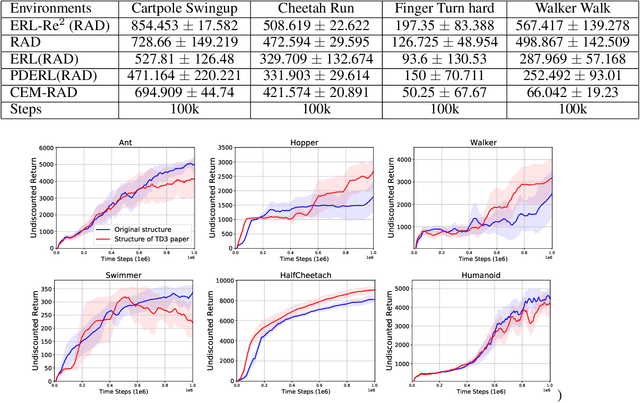
Deep Reinforcement Learning (Deep RL) and Evolutionary Algorithm (EA) are two major paradigms of policy optimization with distinct learning principles, i.e., gradient-based v.s. gradient free. An appealing research direction is integrating Deep RL and EA to devise new methods by fusing their complementary advantages. However, existing works on combining Deep RL and EA have two common drawbacks: 1) the RL agent and EA agents learn their policies individually, neglecting efficient sharing of useful common knowledge; 2) parameter-level policy optimization guarantees no semantic level of behavior evolution for the EA side. In this paper, we propose Evolutionary Reinforcement Learning with Two-scale State Representation and Policy Representation (ERL-Re2), a novel solution to the aforementioned two drawbacks. The key idea of ERL-Re2 is two-scale representation: all EA and RL policies share the same nonlinear state representation while maintaining individual linear policy representations. The state representation conveys expressive common features of the environment learned by all the agents collectively; the linear policy representation provides a favorable space for efficient policy optimization, where novel behavior-level crossover and mutation operations can be performed. Moreover, the linear policy representation allows convenient generalization of policy fitness with the help of Policy-extended Value Function Approximator (PeVFA), further improving the sample efficiency of fitness estimation. The experiments on a range of continuous control tasks show that ERL-Re2 consistently outperforms strong baselines and achieves significant improvement over both its Deep RL and EA components.