 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAPI: Boosting Multi-Agent Reinforcement Learning via Agent-Permutation-Invariant Networks
Paper and Code
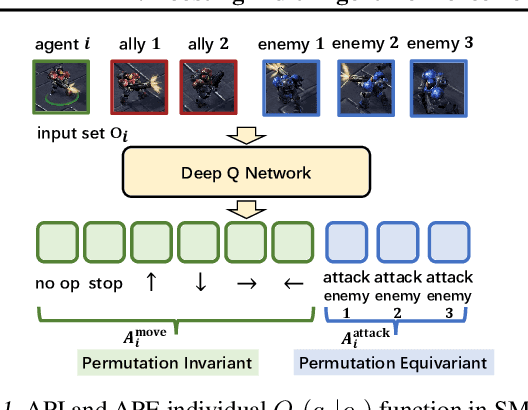
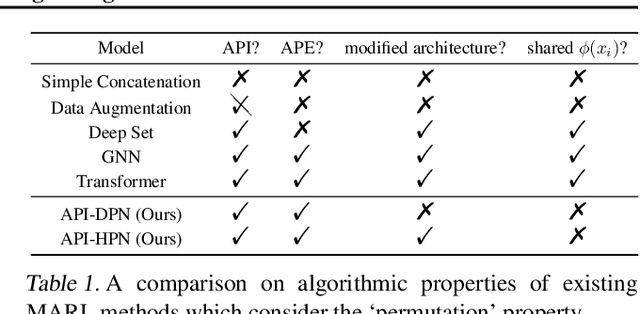
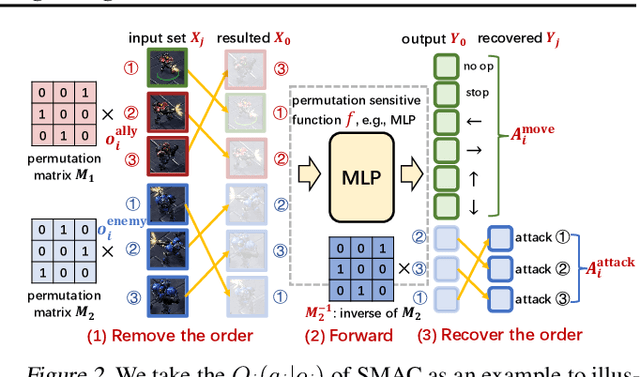
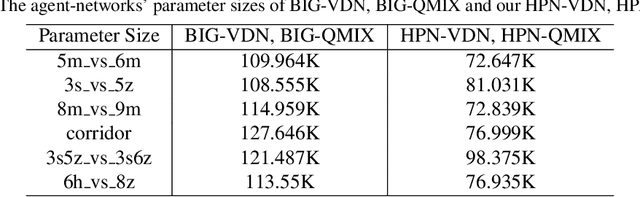
Multi-agent reinforcement learning suffers from poor sample efficiency due to the exponential growth of the state-action space. Considering a homogeneous multiagent system, a global state consisting of $m$ homogeneous components has $m!$ differently ordered representations, thus designing functions satisfying permutation invariant (PI) can reduce the state space by a factor of $\frac{1}{m!}$. However, mainstream MARL algorithms ignore this property and learn over the original state space. To achieve PI, previous works including data augmentation based methods and embedding-sharing architecture based methods, suffer from training instability and limited model capacity. In this work, we propose two novel designs to achieve PI, while avoiding the above limitations. The first design permutes the same but differently ordered inputs back to the same order and the downstream networks only need to learn function mapping over fixed-ordering inputs instead of all permutations, which is much easier to train. The second design applies a hypernetwork to generate customized embedding for each component, which has higher representational capacity than the previous embedding-sharing method. Empirical results on the SMAC benchmark show that the proposed method achieves 100% win-rates in almost all hard and super-hard scenarios (never achieved before), and superior sample-efficiency than the state-of-the-art baselines by up to 400%.