 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDomain Generalization via Discrete Codebook Learning
Apr 09, 2025Domain generalization (DG) strives to address distribution shifts across diverse environments to enhance model's generalizability. Current DG approaches are confined to acquiring robust representations with continuous features, specifically training at the pixel level. However, this DG paradigm may struggle to mitigate distribution gaps in dealing with a large space of continuous features, rendering it susceptible to pixel details that exhibit spurious correlations or noise. In this paper, we first theoretically demonstrate that the domain gaps in continuous representation learning can be reduced by the discretization process. Based on this inspiring finding, we introduce a novel learning paradigm for DG, termed Discrete Domain Generalization (DDG). DDG proposes to use a codebook to quantize the feature map into discrete codewords, aligning semantic-equivalent information in a shared discrete representation space that prioritizes semantic-level information over pixel-level intricacies. By learning at the semantic level, DDG diminishes the number of latent features, optimizing the utilization of the representation space and alleviating the risks associated with the wide-ranging space of continuous features. Extensive experiments across widely employed benchmarks in DG demonstrate DDG's superior performance compared to state-of-the-art approaches, underscoring its potential to reduce the distribution gaps and enhance the model's generalizability.
Generative Classifier for Domain Generalization
Apr 03, 2025Domain generalization (DG) aims to improve the generalizability of computer vision models toward distribution shifts. The mainstream DG methods focus on learning domain invariance, however, such methods overlook the potential inherent in domain-specific information. While the prevailing practice of discriminative linear classifier has been tailored to domain-invariant features, it struggles when confronted with diverse domain-specific information, e.g., intra-class shifts, that exhibits multi-modality. To address these issues, we explore the theoretical implications of relying on domain invariance, revealing the crucial role of domain-specific information in mitigating the target risk for DG. Drawing from these insights, we propose Generative Classifier-driven Domain Generalization (GCDG), introducing a generative paradigm for the DG classifier based on Gaussian Mixture Models (GMMs) for each class across domains. GCDG consists of three key modules: Heterogeneity Learning Classifier~(HLC), Spurious Correlation Blocking~(SCB), and Diverse Component Balancing~(DCB). Concretely, HLC attempts to model the feature distributions and thereby capture valuable domain-specific information via GMMs. SCB identifies the neural units containing spurious correlations and perturbs them, mitigating the risk of HLC learning spurious patterns. Meanwhile, DCB ensures a balanced contribution of components in HLC, preventing the underestimation or neglect of critical components. In this way, GCDG excels in capturing the nuances of domain-specific information characterized by diverse distributions. GCDG demonstrates the potential to reduce the target risk and encourage flat minima, improving the generalizability. Extensive experiments show GCDG's comparable performance on five DG benchmarks and one face anti-spoofing dataset, seamlessly integrating into existing DG methods with consistent improvements.
Privacy-Preserving UCB Decision Process Verification via zk-SNARKs
Apr 18, 2024With the increasingly widespread application of machine learning, how to strike a balance between protecting the privacy of data and algorithm parameters and ensuring the verifiability of machine learning has always been a challenge. This study explores the intersection of reinforcement learning and data privacy, specifically addressing the Multi-Armed Bandit (MAB) problem with the Upper Confidence Bound (UCB) algorithm. We introduce zkUCB, an innovative algorithm that employs the Zero-Knowledge Succinct Non-Interactive Argument of Knowledge (zk-SNARKs) to enhance UCB. zkUCB is carefully designed to safeguard the confidentiality of training data and algorithmic parameters, ensuring transparent UCB decision-making. Experiments highlight zkUCB's superior performance, attributing its enhanced reward to judicious quantization bit usage that reduces information entropy in the decision-making process. zkUCB's proof size and verification time scale linearly with the execution steps of zkUCB. This showcases zkUCB's adept balance between data security and operational efficiency. This approach contributes significantly to the ongoing discourse on reinforcing data privacy in complex decision-making processes, offering a promising solution for privacy-sensitive applications.
DGMamba: Domain Generalization via Generalized State Space Model
Apr 11, 2024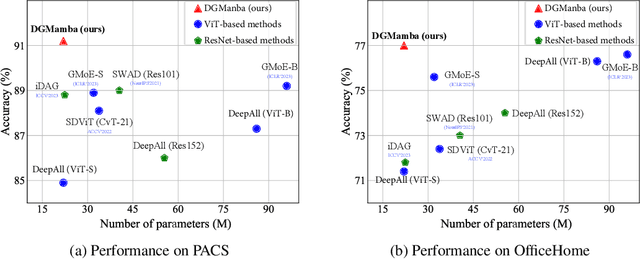
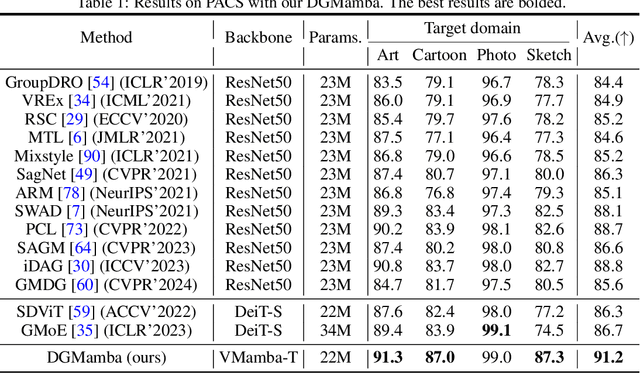
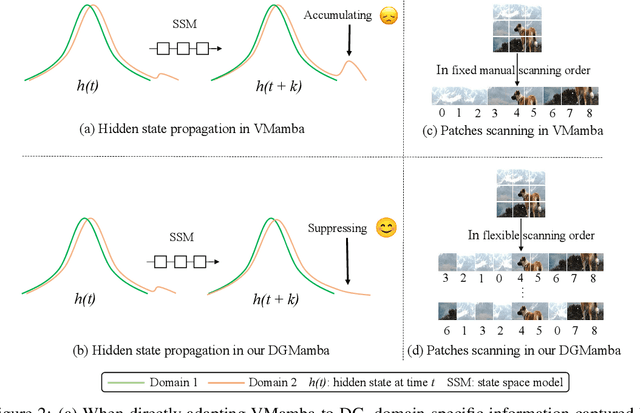

Domain generalization~(DG) aims at solving distribution shift problems in various scenes. Existing approaches are based on Convolution Neural Networks (CNNs) or Vision Transformers (ViTs), which suffer from limited receptive fields or quadratic complexities issues. Mamba, as an emerging state space model (SSM), possesses superior linear complexity and global receptive fields. Despite this, it can hardly be applied to DG to address distribution shifts, due to the hidden state issues and inappropriate scan mechanisms. In this paper, we propose a novel framework for DG, named DGMamba, that excels in strong generalizability toward unseen domains and meanwhile has the advantages of global receptive fields, and efficient linear complexity. Our DGMamba compromises two core components: Hidden State Suppressing~(HSS) and Semantic-aware Patch refining~(SPR). In particular, HSS is introduced to mitigate the influence of hidden states associated with domain-specific features during output prediction. SPR strives to encourage the model to concentrate more on objects rather than context, consisting of two designs: Prior-Free Scanning~(PFS), and Domain Context Interchange~(DCI). Concretely, PFS aims to shuffle the non-semantic patches within images, creating more flexible and effective sequences from images, and DCI is designed to regularize Mamba with the combination of mismatched non-semantic and semantic information by fusing patches among domains. Extensive experiments on four commonly used DG benchmarks demonstrate that the proposed DGMamba achieves remarkably superior results to state-of-the-art models. The code will be made publicly available.
Rethinking Domain Generalization: Discriminability and Generalizability
Sep 28, 2023Domain generalization (DG) endeavors to develop robust models that possess strong generalizability while preserving excellent discriminability. Nonetheless, pivotal DG techniques tend to improve the feature generalizability by learning domain-invariant representations, inadvertently overlooking the feature discriminability. On the one hand, the simultaneous attainment of generalizability and discriminability of features presents a complex challenge, often entailing inherent contradictions. This challenge becomes particularly pronounced when domain-invariant features manifest reduced discriminability owing to the inclusion of unstable factors, \emph{i.e.,} spurious correlations. On the other hand, prevailing domain-invariant methods can be categorized as category-level alignment, susceptible to discarding indispensable features possessing substantial generalizability and narrowing intra-class variations. To surmount these obstacles, we rethink DG from a new perspective that concurrently imbues features with formidable discriminability and robust generalizability, and present a novel framework, namely, Discriminative Microscopic Distribution Alignment (DMDA). DMDA incorporates two core components: Selective Channel Pruning~(SCP) and Micro-level Distribution Alignment (MDA). Concretely, SCP attempts to curtail redundancy within neural networks, prioritizing stable attributes conducive to accurate classification. This approach alleviates the adverse effect of spurious domain invariance and amplifies the feature discriminability. Besides, MDA accentuates micro-level alignment within each class, going beyond mere category-level alignment. This strategy accommodates sufficient generalizable features and facilitates within-class variations. Extensive experiments on four benchmark datasets corroborate the efficacy of our method.
Diverse Target and Contribution Scheduling for Domain Generalization
Sep 28, 2023Generalization under the distribution shift has been a great challenge in computer vision. The prevailing practice of directly employing the one-hot labels as the training targets in domain generalization~(DG) can lead to gradient conflicts, making it insufficient for capturing the intrinsic class characteristics and hard to increase the intra-class variation. Besides, existing methods in DG mostly overlook the distinct contributions of source (seen) domains, resulting in uneven learning from these domains. To address these issues, we firstly present a theoretical and empirical analysis of the existence of gradient conflicts in DG, unveiling the previously unexplored relationship between distribution shifts and gradient conflicts during the optimization process. In this paper, we present a novel perspective of DG from the empirical source domain's risk and propose a new paradigm for DG called Diverse Target and Contribution Scheduling (DTCS). DTCS comprises two innovative modules: Diverse Target Supervision (DTS) and Diverse Contribution Balance (DCB), with the aim of addressing the limitations associated with the common utilization of one-hot labels and equal contributions for source domains in DG. In specific, DTS employs distinct soft labels as training targets to account for various feature distributions across domains and thereby mitigates the gradient conflicts, and DCB dynamically balances the contributions of source domains by ensuring a fair decline in losses of different source domains. Extensive experiments with analysis on four benchmark datasets show that the proposed method achieves a competitive performance in comparison with the state-of-the-art approaches, demonstrating the effectiveness and advantages of the proposed DTCS.