 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePose-based Modular Network for Human-Object Interaction Detection
Aug 05, 2020
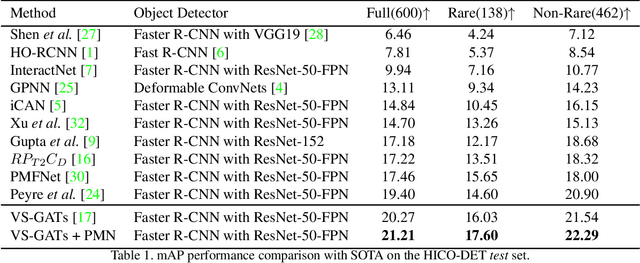
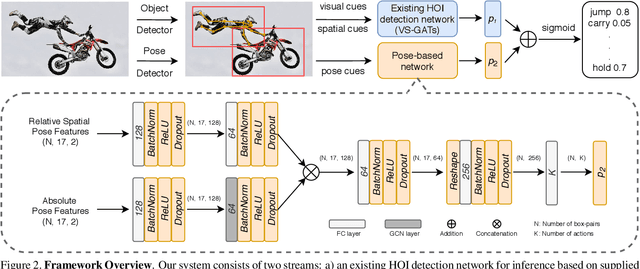
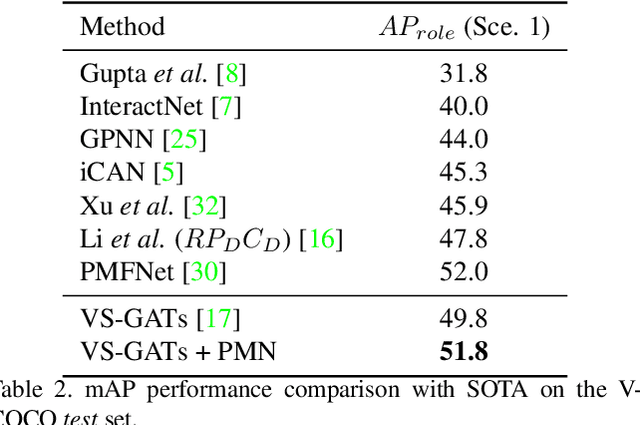
Human-object interaction(HOI) detection is a critical task in scene understanding. The goal is to infer the triplet <subject, predicate, object> in a scene. In this work, we note that the human pose itself as well as the relative spatial information of the human pose with respect to the target object can provide informative cues for HOI detection. We contribute a Pose-based Modular Network (PMN) which explores the absolute pose features and relative spatial pose features to improve HOI detection and is fully compatible with existing networks. Our module consists of a branch that first processes the relative spatial pose features of each joint independently. Another branch updates the absolute pose features via fully connected graph structures. The processed pose features are then fed into an action classifier. To evaluate our proposed method, we combine the module with the state-of-the-art model named VS-GATs and obtain significant improvement on two public benchmarks: V-COCO and HICO-DET, which shows its efficacy and flexibility. Code is available at \url{https://github.com/birlrobotics/PMN}.
GAST-Net: Graph Attention Spatio-temporal Convolutional Networks for 3D Human Pose Estimation in Video
Mar 11, 2020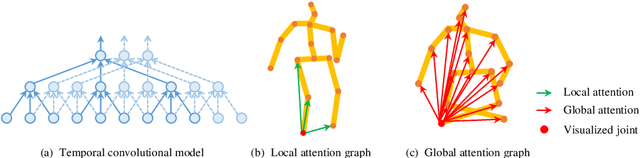
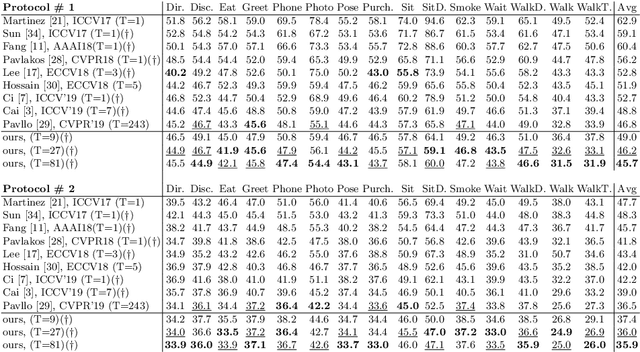
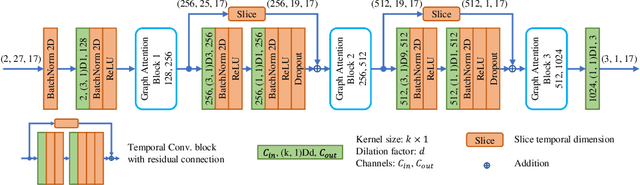

3D pose estimation in video can benefit greatly from both temporal and spatial information. Occlusions and depth ambiguities remain outstanding problems. In this work, we study how to learn the kinematic constraints of the human skeleton by modeling additional spatial information through attention and interleaving it in a synergistic way with temporal models. We contribute a graph attention spatio-temporal convolutional network (GAST-Net) that makes full use of spatio-temporal information and mitigates the problems of occlusion and depth ambiguities. We also contribute attention mechanisms that learn inter-joint relations that are easily visualizable. GAST-Net comprises of interleaved temporal convolutional and graph attention blocks. We use dilated temporal convolution networks (TCNs) to model long-term patterns. More critically, graph attention blocks encode local and global representations through novel convolutional kernels that express human skeletal symmetrical structure and adaptively extract global semantics over time. GAST-Net outperforms SOTA by approximately 10\% for mean per-joint position error for ground-truth labels on Human3.6M and achieves competitive results on HumanEva-I.
Large-scale Multi-modal Person Identification in Real Unconstrained Environments
Dec 17, 2019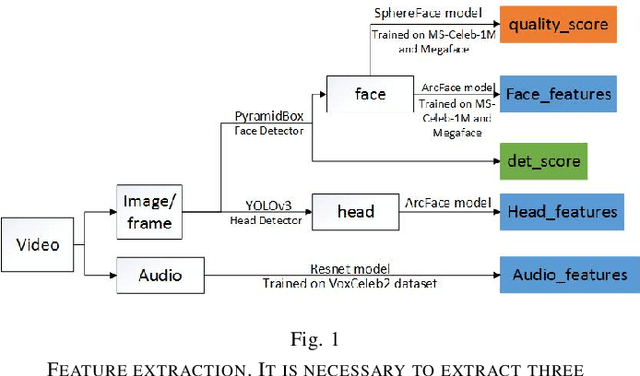
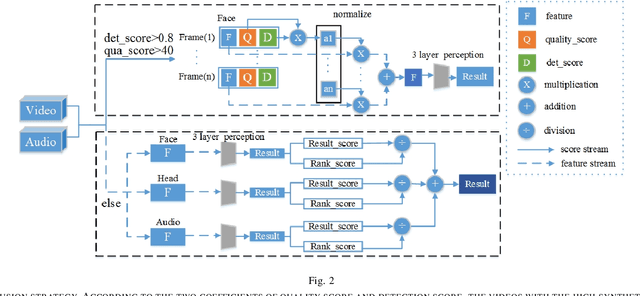

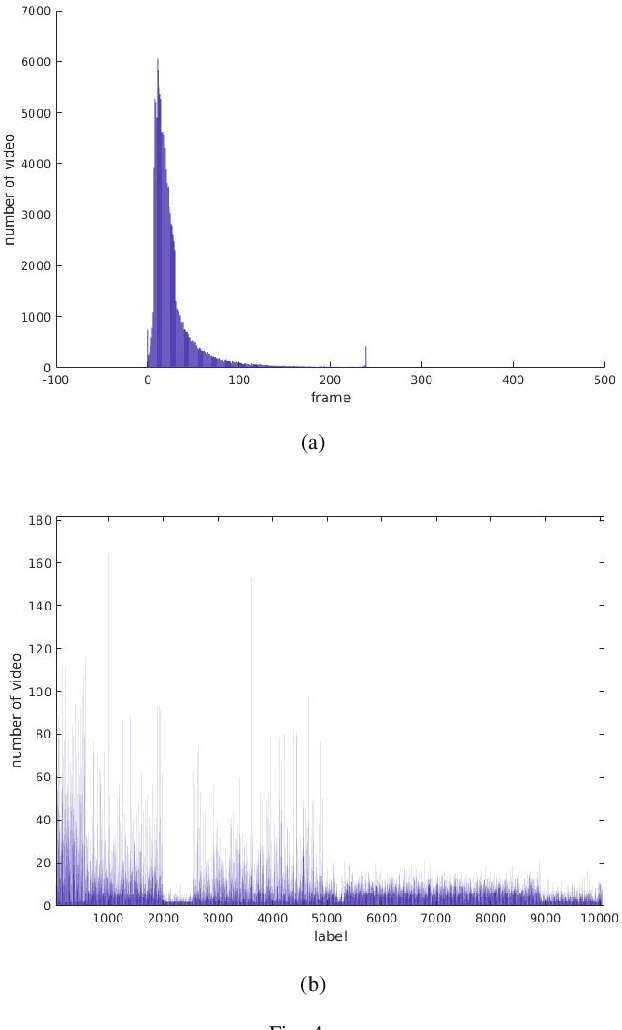
Person identification (P-ID) under real unconstrained noisy environments is a huge challenge. In multiple-feature learning with Deep Convolutional Neural Networks (DCNNs) or Machine Learning method for large-scale person identification in the wild, the key is to design an appropriate strategy for decision layer fusion or feature layer fusion which can enhance discriminative power. It is necessary to extract different types of valid features and establish a reasonable framework to fuse different types of information. In traditional methods, different persons are identified based on single modal features to identify, such as face feature, audio feature, and head feature. These traditional methods cannot realize a highly accurate level of person identification in real unconstrained environments. The study aims to propose a fusion module to fuse multi-modal features for person identification in real unconstrained environments.