 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGAST-Net: Graph Attention Spatio-temporal Convolutional Networks for 3D Human Pose Estimation in Video
Paper and Code
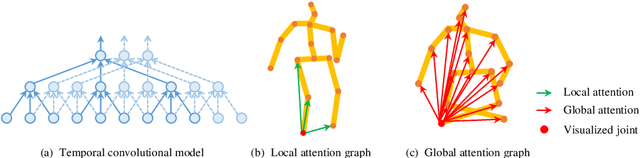
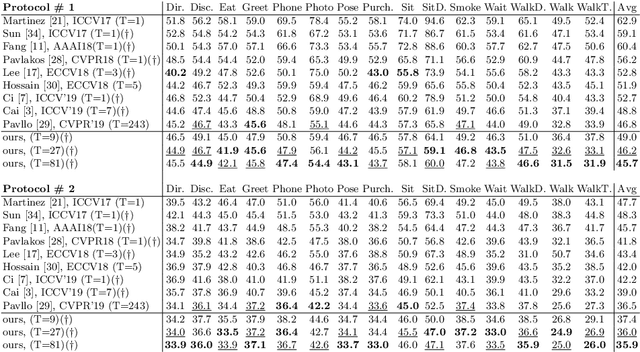
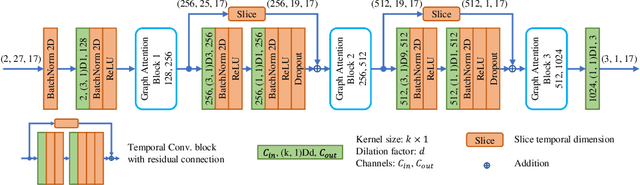

3D pose estimation in video can benefit greatly from both temporal and spatial information. Occlusions and depth ambiguities remain outstanding problems. In this work, we study how to learn the kinematic constraints of the human skeleton by modeling additional spatial information through attention and interleaving it in a synergistic way with temporal models. We contribute a graph attention spatio-temporal convolutional network (GAST-Net) that makes full use of spatio-temporal information and mitigates the problems of occlusion and depth ambiguities. We also contribute attention mechanisms that learn inter-joint relations that are easily visualizable. GAST-Net comprises of interleaved temporal convolutional and graph attention blocks. We use dilated temporal convolution networks (TCNs) to model long-term patterns. More critically, graph attention blocks encode local and global representations through novel convolutional kernels that express human skeletal symmetrical structure and adaptively extract global semantics over time. GAST-Net outperforms SOTA by approximately 10\% for mean per-joint position error for ground-truth labels on Human3.6M and achieves competitive results on HumanEva-I.