 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLarge-scale Multi-modal Person Identification in Real Unconstrained Environments
Paper and Code
Dec 17, 2019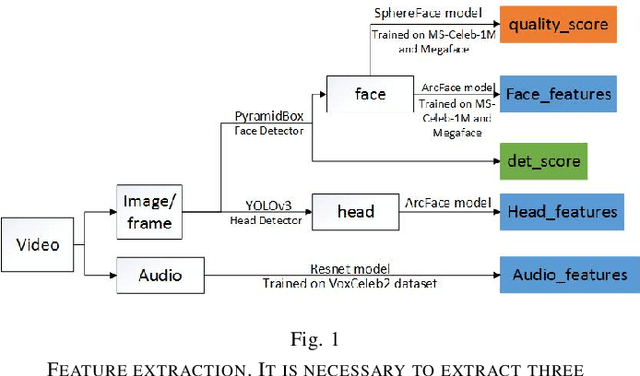
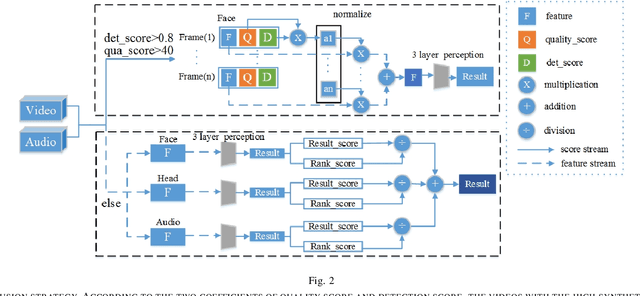

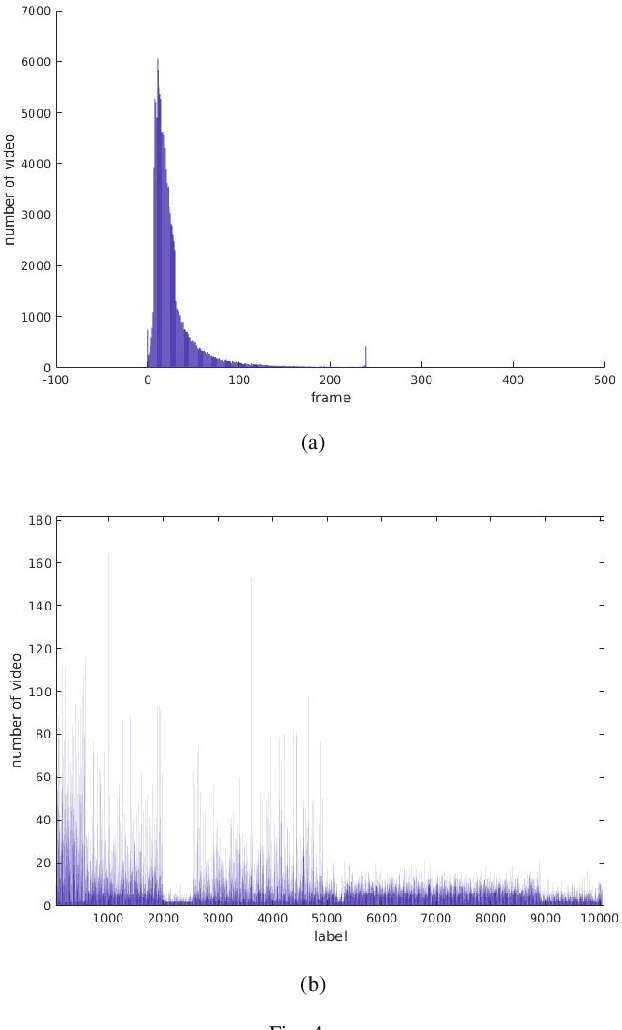
Person identification (P-ID) under real unconstrained noisy environments is a huge challenge. In multiple-feature learning with Deep Convolutional Neural Networks (DCNNs) or Machine Learning method for large-scale person identification in the wild, the key is to design an appropriate strategy for decision layer fusion or feature layer fusion which can enhance discriminative power. It is necessary to extract different types of valid features and establish a reasonable framework to fuse different types of information. In traditional methods, different persons are identified based on single modal features to identify, such as face feature, audio feature, and head feature. These traditional methods cannot realize a highly accurate level of person identification in real unconstrained environments. The study aims to propose a fusion module to fuse multi-modal features for person identification in real unconstrained environments.