 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUniBiDex: A Unified Teleoperation Framework for Robotic Bimanual Dexterous Manipulation
Jan 08, 2026We present UniBiDex a unified teleoperation framework for robotic bimanual dexterous manipulation that supports both VRbased and leaderfollower input modalities UniBiDex enables realtime contactrich dualarm teleoperation by integrating heterogeneous input devices into a shared control stack with consistent kinematic treatment and safety guarantees The framework employs nullspace control to optimize bimanual configurations ensuring smooth collisionfree and singularityaware motion across tasks We validate UniBiDex on a longhorizon kitchentidying task involving five sequential manipulation subtasks demonstrating higher task success rates smoother trajectories and improved robustness compared to strong baselines By releasing all hardware and software components as opensource we aim to lower the barrier to collecting largescale highquality human demonstration datasets and accelerate progress in robot learning.
BagIt! An Adaptive Dual-Arm Manipulation of Fabric Bags for Object Bagging
Sep 11, 2025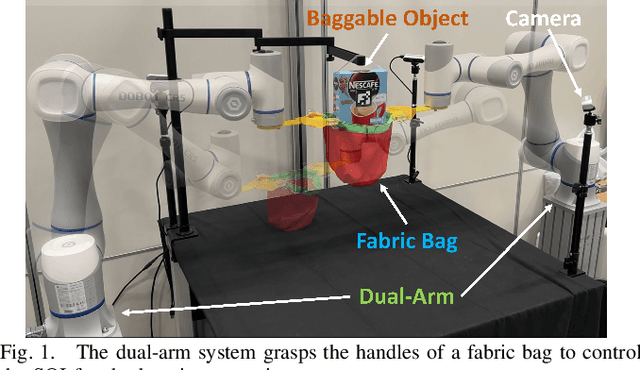
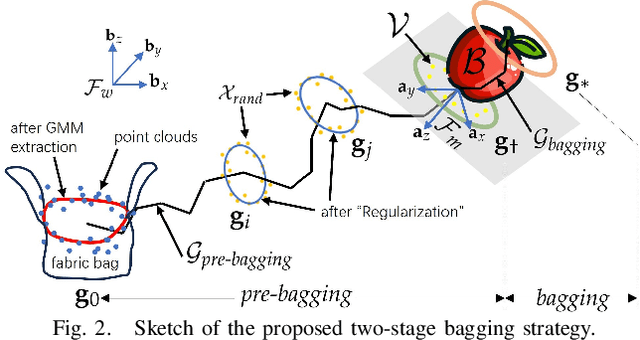
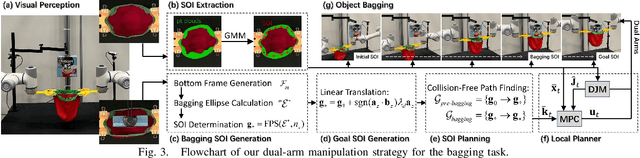
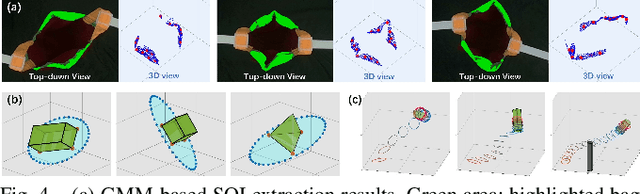
Bagging tasks, commonly found in industrial scenarios, are challenging considering deformable bags' complicated and unpredictable nature. This paper presents an automated bagging system from the proposed adaptive Structure-of-Interest (SOI) manipulation strategy for dual robot arms. The system dynamically adjusts its actions based on real-time visual feedback, removing the need for pre-existing knowledge of bag properties. Our framework incorporates Gaussian Mixture Models (GMM) for estimating SOI states, optimization techniques for SOI generation, motion planning via Constrained Bidirectional Rapidly-exploring Random Tree (CBiRRT), and dual-arm coordination using Model Predictive Control (MPC). Extensive experiments validate the capability of our system to perform precise and robust bagging across various objects, showcasing its adaptability. This work offers a new solution for robotic deformable object manipulation (DOM), particularly in automated bagging tasks. Video of this work is available at https://youtu.be/6JWjCOeTGiQ.
Revolutionizing Packaging: A Robotic Bagging Pipeline with Constraint-aware Structure-of-Interest Planning
Mar 15, 2024



Bagging operations, common in packaging and assisted living applications, are challenging due to a bag's complex deformable properties. To address this, we develop a robotic system for automated bagging tasks using an adaptive structure-of-interest (SOI) manipulation approach. Our method relies on real-time visual feedback to dynamically adjust manipulation without requiring prior knowledge of bag materials or dynamics. We present a robust pipeline featuring state estimation for SOIs using Gaussian Mixture Models (GMM), SOI generation via optimization-based bagging techniques, SOI motion planning with Constrained Bidirectional Rapidly-exploring Random Trees (CBiRRT), and dual-arm manipulation coordinated by Model Predictive Control (MPC). Experiments demonstrate the system's ability to achieve precise, stable bagging of various objects using adaptive coordination of the manipulators. The proposed framework advances the capability of dual-arm robots to perform more sophisticated automation of common tasks involving interactions with deformable objects.
Hyperparameter Auto-tuning in Self-Supervised Robotic Learning
Oct 19, 2020


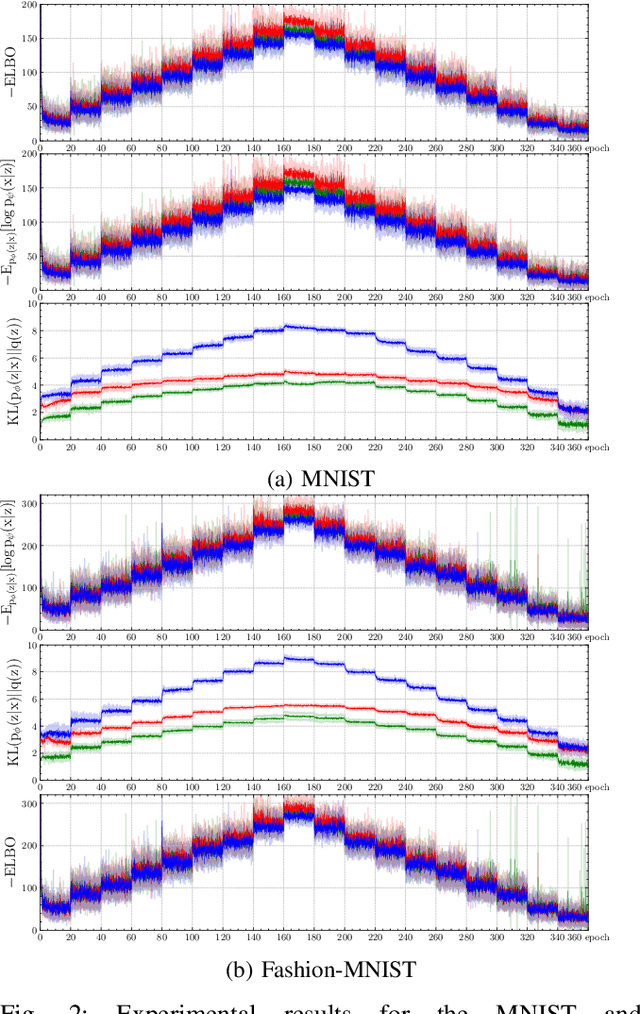
Policy optimization in reinforcement learning requires the selection of numerous hyperparameters across different environments. Fixing them incorrectly may negatively impact optimization performance leading notably to insufficient or redundant learning. Insufficient learning (due to convergence to local optima) results in under-performing policies whilst redundant learning wastes time and resources. The effects are further exacerbated when using single policies to solve multi-task learning problems. In this paper, we study how the Evidence Lower Bound (ELBO) used in Variational Auto-Encoders (VAEs) is affected by the diversity of image samples. Different tasks or setups in visual reinforcement learning incur varying diversity. We exploit the ELBO to create an auto-tuning technique in self-supervised reinforcement learning. Our approach can auto-tune three hyperparameters: the replay buffer size, the number of policy gradient updates during each epoch, and the number of exploration steps during each epoch. We use the state-of-the-art self-supervised robotic learning framework (Reinforcement Learning with Imagined Goals (RIG) using Soft Actor-Critic) as baseline for experimental verification. Experiments show that our method can auto-tune online and yields the best performance at a fraction of the time and computational resources. Code, video, and appendix for simulated and real-robot experiments can be found at http://www.JuanRojas.net/autotune.
Dynamic Interaction Probabilistic Movement Primitives
Jan 30, 2019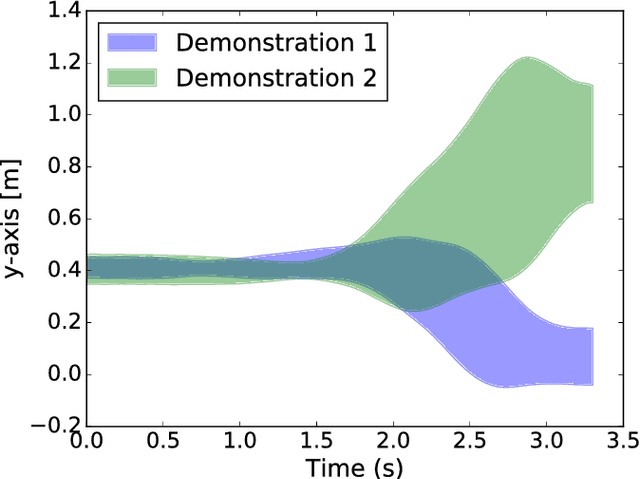
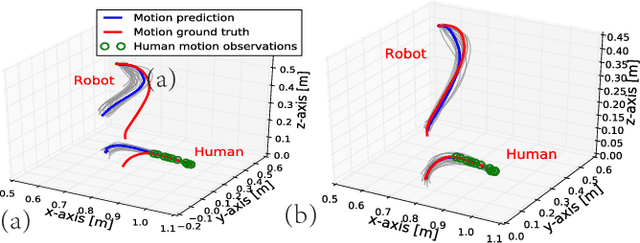
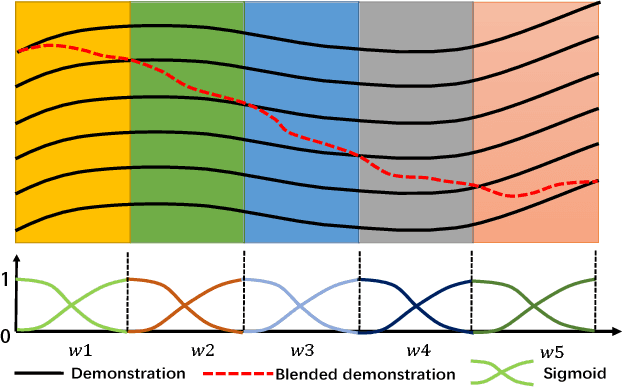
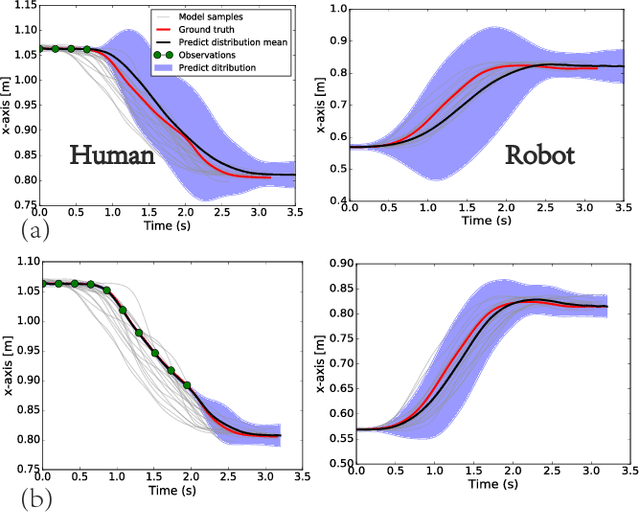
Human-robot collaboration is on the rise. Robots need to increasingly improve the efficiency and smoothness with which they assist humans by properly anticipating a human's intention. To do so, prediction models need to increase their accuracy and responsiveness. This work builds on top of Interaction Movement Primitives with phase estimation and re-formulates the framework to use dynamic human-motion observations which constantly update anticipatory motions. The original framework only considers a single fixed-duration static human observation which is used to perform only one anticipatory motion. Dynamic observations, with built-in phase estimation, yield a series of updated robot motion distributions. Co-activation is performed between the existing and newest most probably robot motion distribution. This results in smooth anticipatory robot motions that are highly accurate and with enhanced responsiveness.
Endowing Robots with Longer-term Autonomy by Recovering from External Disturbances in Manipulation through Grounded Anomaly Classification and Recovery Policies
Sep 11, 2018
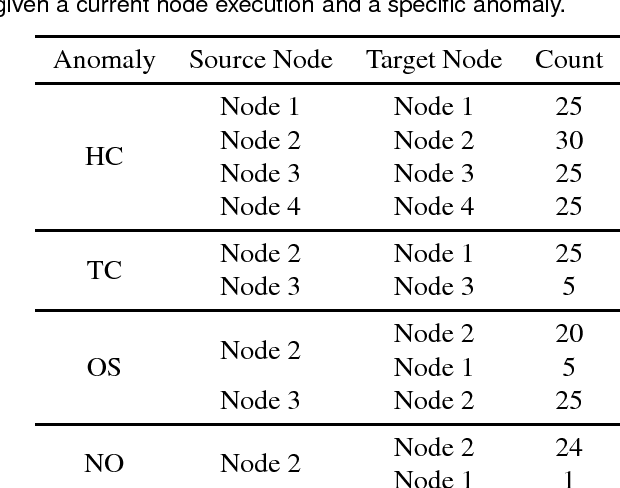
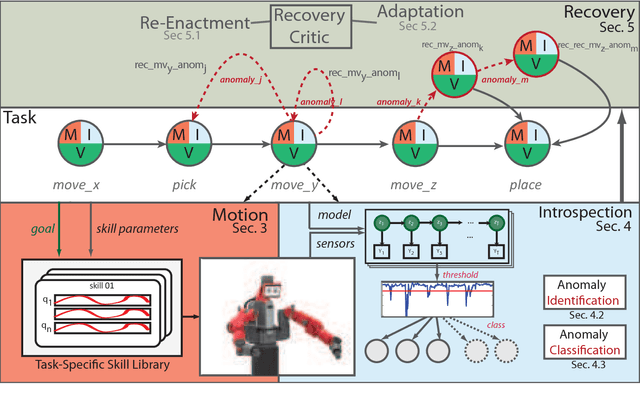

Robot manipulation is increasingly poised to interact with humans in co-shared workspaces. Despite increasingly robust manipulation and control algorithms, failure modes continue to exist whenever models do not capture the dynamics of the unstructured environment. To obtain longer-term horizons in robot automation, robots must develop introspection and recovery abilities. We contribute a set of recovery policies to deal with anomalies produced by external disturbances as well as anomaly classification through the use of non-parametric statistics with memoized variational inference with scalable adaptation. A recovery critic stands atop of a tightly-integrated, graph-based online motion-generation and introspection system that resolves a wide range of anomalous situations. Policies, skills, and introspection models are learned incrementally and contextually in a task. Two task-level recovery policies: re-enactment and adaptation resolve accidental and persistent anomalies respectively. The introspection system uses non-parametric priors along with Markov jump linear systems and memoized variational inference with scalable adaptation to learn a model from the data. Extensive real-robot experimentation with various strenuous anomalous conditions is induced and resolved at different phases of a task and in different combinations. The system executes around-the-clock introspection and recovery and even elicited self-recovery when misclassifications occurred.
Fast, Robust, and Versatile Event Detection through HMM Belief State Gradient Measures
Jun 20, 2018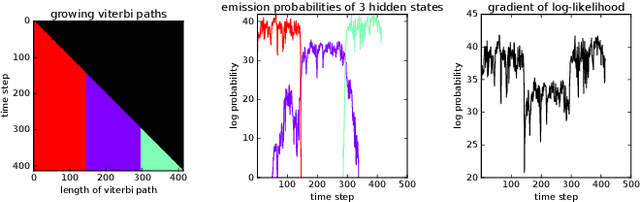
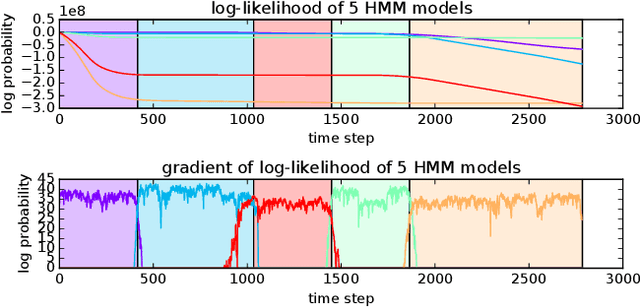

Event detection is a critical feature in data-driven systems as it assists with the identification of nominal and anomalous behavior. Event detection is increasingly relevant in robotics as robots operate with greater autonomy in increasingly unstructured environments. In this work, we present an accurate, robust, fast, and versatile measure for skill and anomaly identification. A theoretical proof establishes the link between the derivative of the log-likelihood of the HMM filtered belief state and the latest emission probabilities. The key insight is the inverse relationship in which gradient analysis is used for skill and anomaly identification. Our measure showed better performance across all metrics than related state-of-the art works. The result is broadly applicable to domains that use HMMs for event detection.
Recovering from External Disturbances in Online Manipulation through State-Dependent Revertive Recovery Policies
Apr 02, 2018
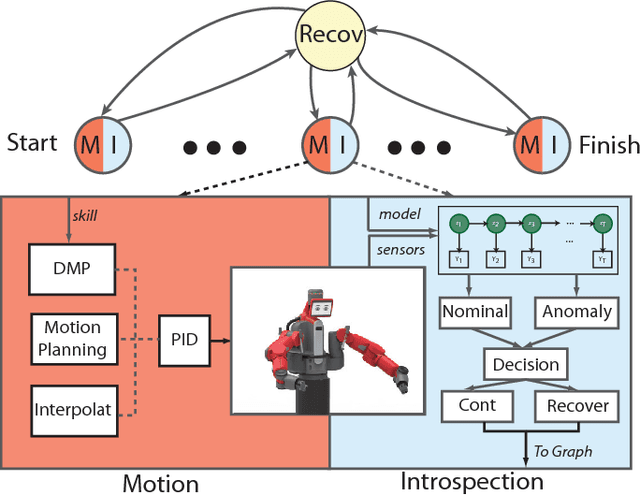
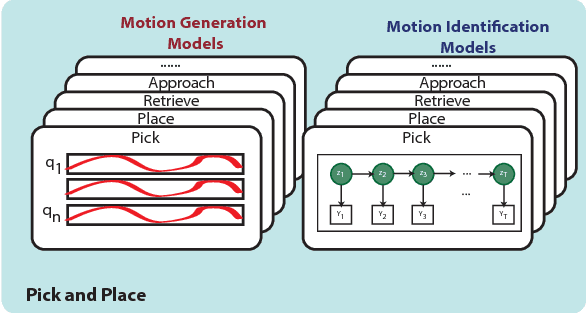
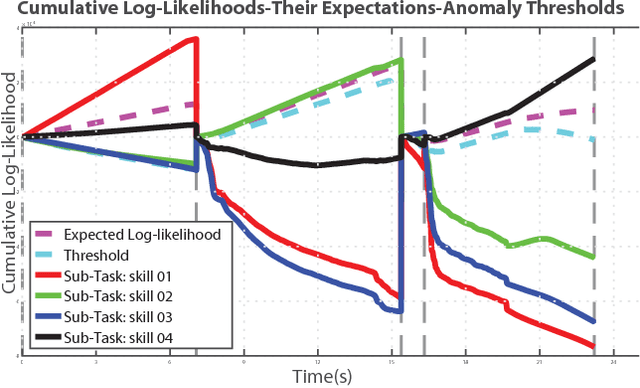
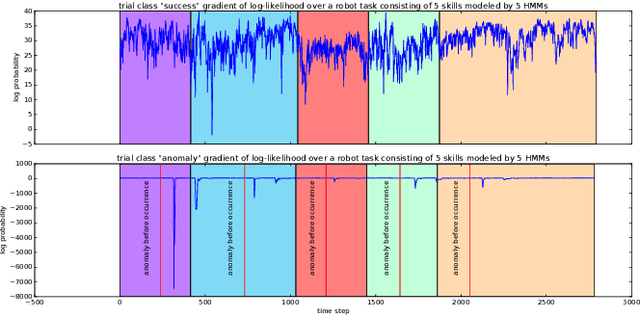
Robots are increasingly entering uncertain and unstructured environments. Within these, robots are bound to face unexpected external disturbances like accidental human or tool collisions. Robots must develop the capacity to respond to unexpected events. That is not only identifying the sudden anomaly, but also deciding how to handle it. In this work, we contribute a recovery policy that allows a robot to recovery from various anomalous scenarios across different tasks and conditions in a consistent and robust fashion. The system organizes tasks as a sequence of nodes composed of internal modules such as motion generation and introspection. When an introspection module flags an anomaly, the recovery strategy is triggered and reverts the task execution by selecting a target node as a function of a state dependency chart. The new skill allows the robot to overcome the effects of the external disturbance and conclude the task. Our system recovers from accidental human and tool collisions in a number of tasks. Of particular importance is the fact that we test the robustness of the recovery system by triggering anomalies at each node in the task graph showing robust recovery everywhere in the task. We also trigger multiple and repeated anomalies at each of the nodes of the task showing that the recovery system can consistently recover anywhere in the presence of strong and pervasive anomalous conditions. Robust recovery systems will be key enablers for long-term autonomy in robot systems. Supplemental info including code, data, graphs, and result analysis can be found at [1].
Robot Introspection with Bayesian Nonparametric Vector Autoregressive Hidden Markov Models
Jan 22, 2018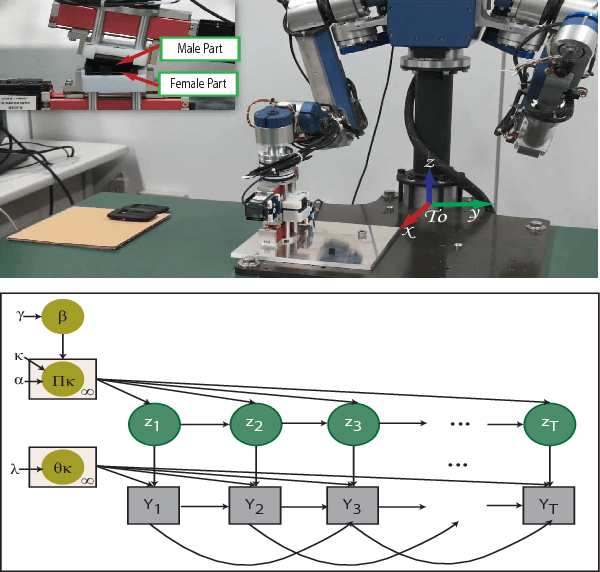
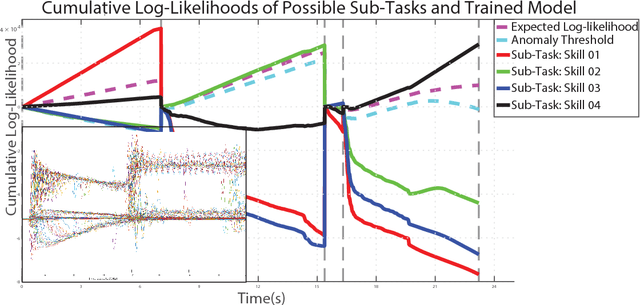
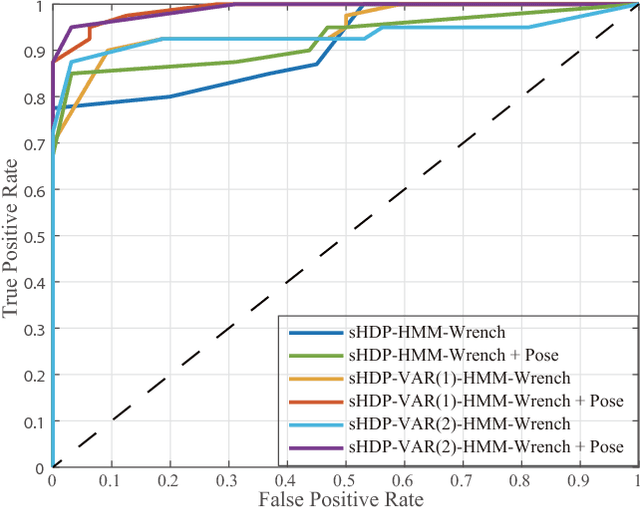
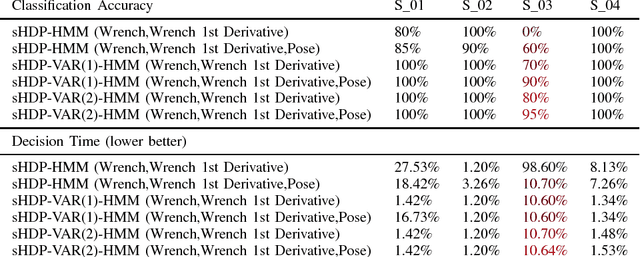
Robot introspection, as opposed to anomaly detection typical in process monitoring, helps a robot understand what it is doing at all times. A robot should be able to identify its actions not only when failure or novelty occurs, but also as it executes any number of sub-tasks. As robots continue their quest of functioning in unstructured environments, it is imperative they understand what is it that they are actually doing to render them more robust. This work investigates the modeling ability of Bayesian nonparametric techniques on Markov Switching Process to learn complex dynamics typical in robot contact tasks. We study whether the Markov switching process, together with Bayesian priors can outperform the modeling ability of its counterparts: an HMM with Bayesian priors and without. The work was tested in a snap assembly task characterized by high elastic forces. The task consists of an insertion subtask with very complex dynamics. Our approach showed a stronger ability to generalize and was able to better model the subtask with complex dynamics in a computationally efficient way. The modeling technique is also used to learn a growing library of robot skills, one that when integrated with low-level control allows for robot online decision making.