 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVisual-Semantic Graph Attention Network for Human-Object Interaction Detection
Paper and Code

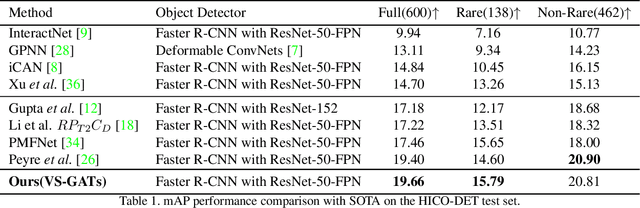
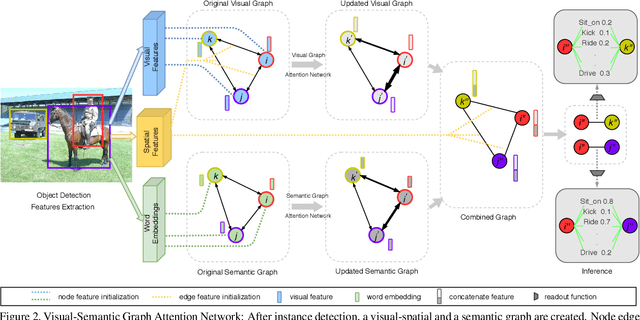
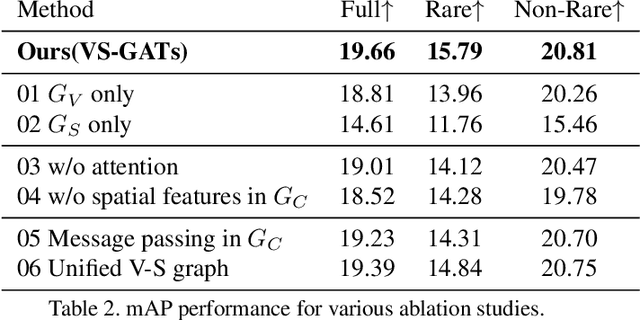
In scene understanding, machines benefit from not only detecting individual scene instances but also from learning their possible interactions. Human-Object Interaction (HOI) Detection tries to infer the predicate on a <subject,predicate,object> triplet. Contextual information has been found critical in inferring interactions. However, most works use features from single object instances that have a direct relation with the subject. Few works have studied the disambiguating contribution of subsidiary relations in addition to how attention might leverage them for inference. We contribute a dual-graph attention network that aggregates contextual visual, spatial, and semantic information dynamically for primary subject-object relations as well as subsidiary relations. Graph attention networks dynamically leverage node neighborhood information. Our network uses attention to first leverage visual-spatial and semantic cues from primary and subsidiary relations independently and then combines them before a final readout step. Our network learns to use primary and subsidiary relations to improve inference: encouraging the right interpretations and discouraging incorrect ones. We call our model: Visual-Semantic Graph Attention Networks (VS-GATs). We surpass state-of-the-art HOI detection mAPs in the challenging HICO-DET dataset, including in long-tail cases that are harder to interpret. Code, video, and supplementary information is available at http://www.juanrojas.net/VSGAT.