 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHAMLET-FFD: Hierarchical Adaptive Multi-modal Learning Embeddings Transformation for Face Forgery Detection
Jul 28, 2025The rapid evolution of face manipulation techniques poses a critical challenge for face forgery detection: cross-domain generalization. Conventional methods, which rely on simple classification objectives, often fail to learn domain-invariant representations. We propose HAMLET-FFD, a cognitively inspired Hierarchical Adaptive Multi-modal Learning framework that tackles this challenge via bidirectional cross-modal reasoning. Building on contrastive vision-language models such as CLIP, HAMLET-FFD introduces a knowledge refinement loop that iteratively assesses authenticity by integrating visual evidence with conceptual cues, emulating expert forensic analysis. A key innovation is a bidirectional fusion mechanism in which textual authenticity embeddings guide the aggregation of hierarchical visual features, while modulated visual features refine text embeddings to generate image-adaptive prompts. This closed-loop process progressively aligns visual observations with semantic priors to enhance authenticity assessment. By design, HAMLET-FFD freezes all pretrained parameters, serving as an external plugin that preserves CLIP's original capabilities. Extensive experiments demonstrate its superior generalization to unseen manipulations across multiple benchmarks, and visual analyses reveal a division of labor among embeddings, with distinct representations specializing in fine-grained artifact recognition.
Every FLOP Counts: Scaling a 300B Mixture-of-Experts LING LLM without Premium GPUs
Mar 07, 2025



In this technical report, we tackle the challenges of training large-scale Mixture of Experts (MoE) models, focusing on overcoming cost inefficiency and resource limitations prevalent in such systems. To address these issues, we present two differently sized MoE large language models (LLMs), namely Ling-Lite and Ling-Plus (referred to as "Bailing" in Chinese, spelled B\v{a}il\'ing in Pinyin). Ling-Lite contains 16.8 billion parameters with 2.75 billion activated parameters, while Ling-Plus boasts 290 billion parameters with 28.8 billion activated parameters. Both models exhibit comparable performance to leading industry benchmarks. This report offers actionable insights to improve the efficiency and accessibility of AI development in resource-constrained settings, promoting more scalable and sustainable technologies. Specifically, to reduce training costs for large-scale MoE models, we propose innovative methods for (1) optimization of model architecture and training processes, (2) refinement of training anomaly handling, and (3) enhancement of model evaluation efficiency. Additionally, leveraging high-quality data generated from knowledge graphs, our models demonstrate superior capabilities in tool use compared to other models. Ultimately, our experimental findings demonstrate that a 300B MoE LLM can be effectively trained on lower-performance devices while achieving comparable performance to models of a similar scale, including dense and MoE models. Compared to high-performance devices, utilizing a lower-specification hardware system during the pre-training phase demonstrates significant cost savings, reducing computing costs by approximately 20%. The models can be accessed at https://huggingface.co/inclusionAI.
Modelling prospective memory and resilient situated communications via Wizard of Oz
Nov 09, 2023This abstract presents a scenario for human-robot action in a home setting involving an older adult and a robot. The scenario is designed to explore the envisioned modelling of memory for communication with a socially assistive robots (SAR). The scenario will enable the gathering of data on failures of speech technology and human-robot communication involving shared memory that may occur during daily activities such as a music-listening activity.
Adversarial Sub-sequence for Text Generation
May 30, 2019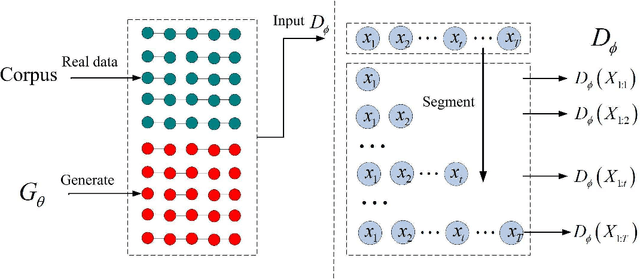

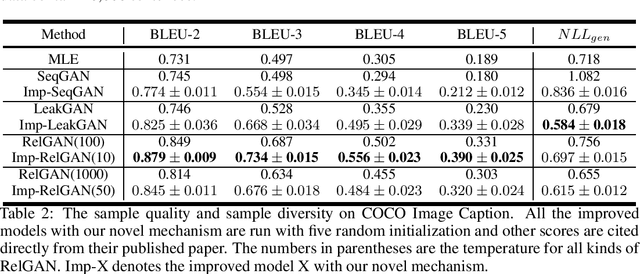
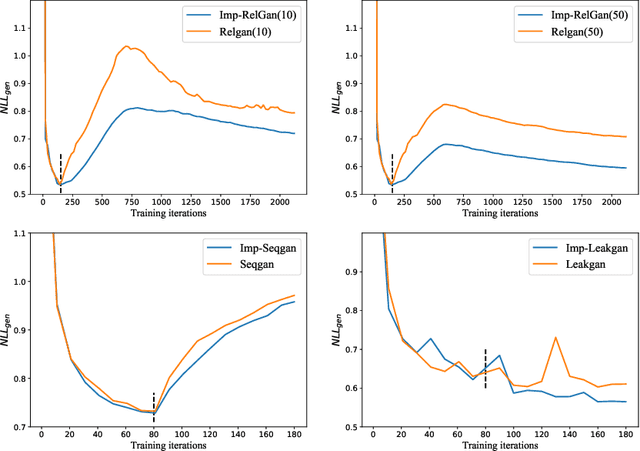
Generative adversarial nets (GAN) has been successfully introduced for generating text to alleviate the exposure bias. However, discriminators in these models only evaluate the entire sequence, which causes feedback sparsity and mode collapse. To tackle these problems, we propose a novel mechanism. It first segments the entire sequence into several sub-sequences. Then these sub-sequences, together with the entire sequence, are evaluated individually by the discriminator. At last these feedback signals are all used to guide the learning of GAN. This mechanism learns the generation of both the entire sequence and the sub-sequences simultaneously. Learning to generate sub-sequences is easy and is helpful in generating an entire sequence. It is easy to improve the existing GAN-based models with this mechanism. We rebuild three previous well-designed models with our mechanism, and the experimental results on benchmark data show these models are improved significantly, the best one outperforms the state-of-the-art model.\footnote[1]{All code and data are available at https://github.com/liyzcj/seggan.git