 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDistributional Discrepancy: A Metric for Unconditional Text Generation
Paper and Code
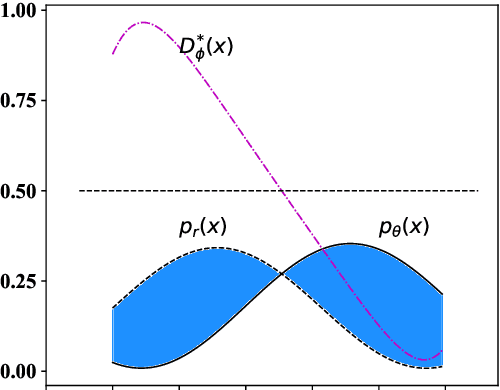
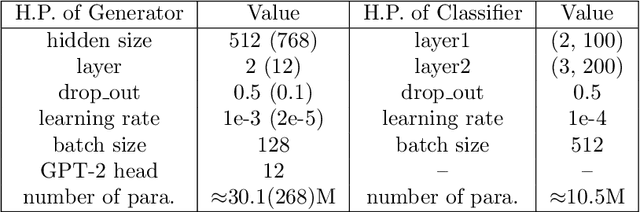

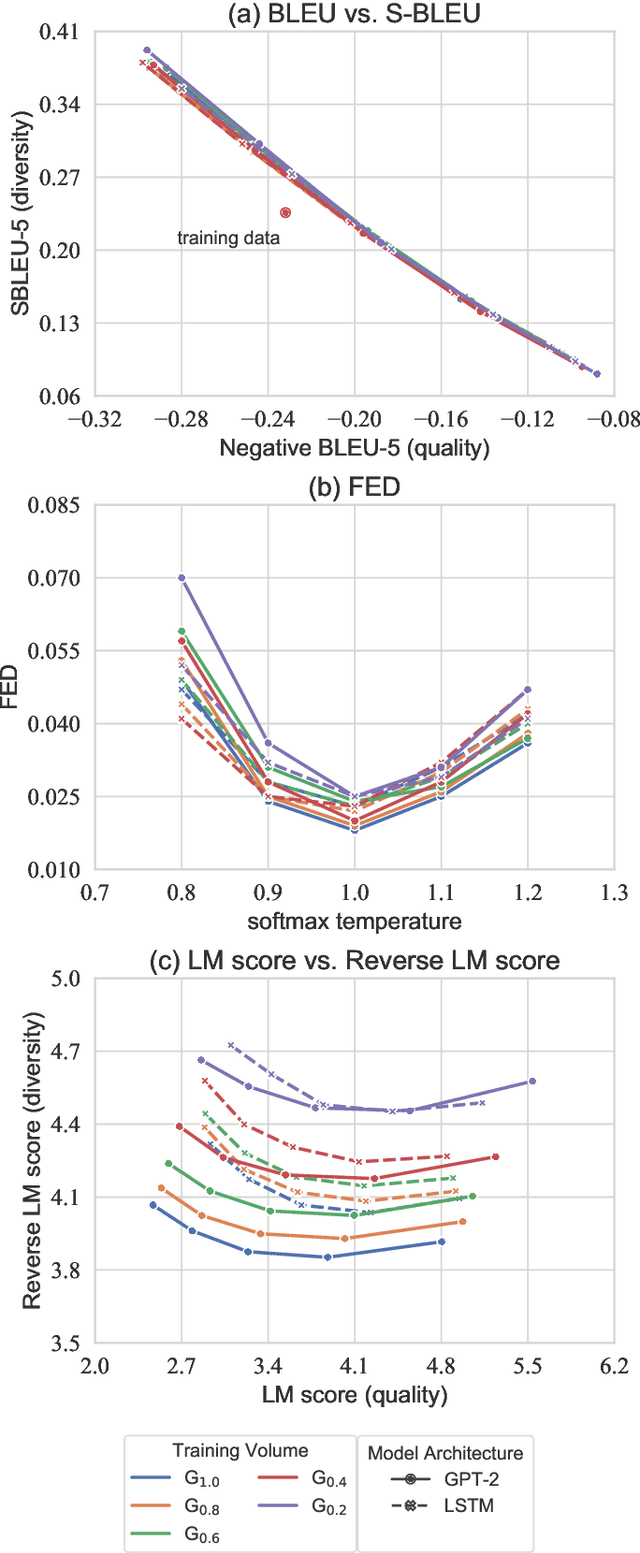
The goal of unconditional text generation is training a model with real sentences, to generate novel sentences which should be the same quality and diversity as the training data. However, when different metrics are used for comparing these methods, the contradictory conclusions are drawn. The difficulty is that both the sample diversity and the sample quality should be taken into account simultaneously, when a generative model is evaluated. To solve this issue, a novel metric of distributional discrepancy (DD) is designed to evaluate generators according to the discrepancy between the generated sentences and the real training sentences. But, a challenge is that it can't compute DD directly because the distribution of real sentences is unavailable. Thus, we propose a method to estimate DD by training a neural-network-based text classifier. For comparison, three existing metrics, Bilingual Evaluation Understudy (BLEU) verse self-BLEU, language model score verse reverse language model score, Fr'chet Embedding Distance (FED), together with the proposed DD, are used to evaluate two popular generative models of LSTM and GPT-2 on both syntactic and real data. Experimental results show DD is much better than the three existing metrics in ranking these generative models.