 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDistributional Discrepancy: A Metric for Unconditional Text Generation
May 04, 2020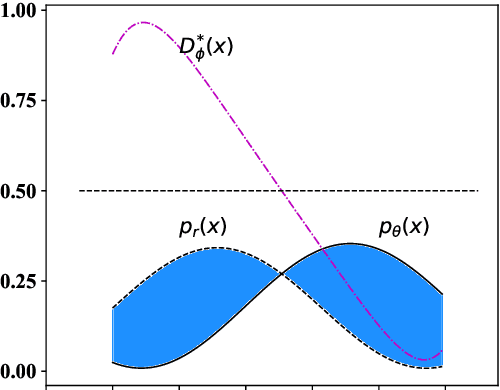
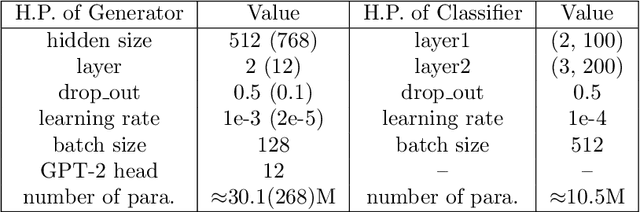

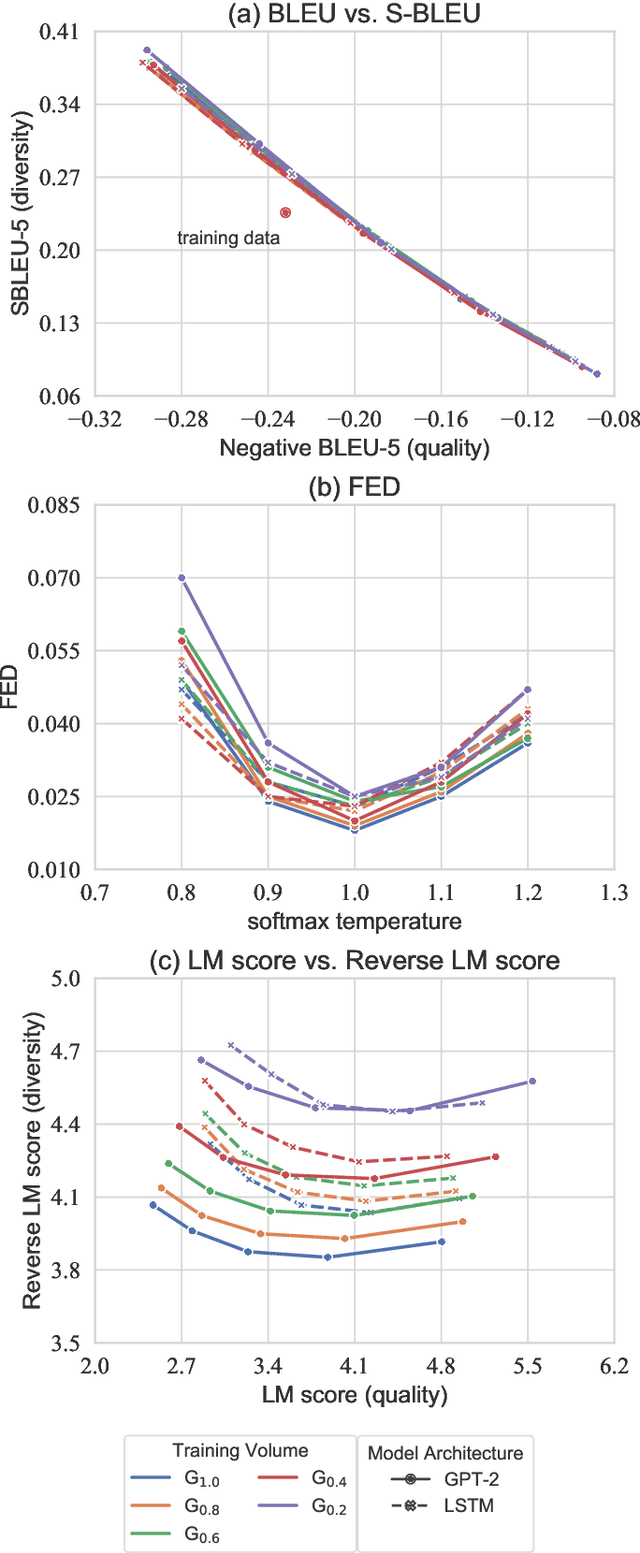
The goal of unconditional text generation is training a model with real sentences, to generate novel sentences which should be the same quality and diversity as the training data. However, when different metrics are used for comparing these methods, the contradictory conclusions are drawn. The difficulty is that both the sample diversity and the sample quality should be taken into account simultaneously, when a generative model is evaluated. To solve this issue, a novel metric of distributional discrepancy (DD) is designed to evaluate generators according to the discrepancy between the generated sentences and the real training sentences. But, a challenge is that it can't compute DD directly because the distribution of real sentences is unavailable. Thus, we propose a method to estimate DD by training a neural-network-based text classifier. For comparison, three existing metrics, Bilingual Evaluation Understudy (BLEU) verse self-BLEU, language model score verse reverse language model score, Fr'chet Embedding Distance (FED), together with the proposed DD, are used to evaluate two popular generative models of LSTM and GPT-2 on both syntactic and real data. Experimental results show DD is much better than the three existing metrics in ranking these generative models.
A Discriminator Improves Unconditional Text Generation without Updating the Generator
Apr 09, 2020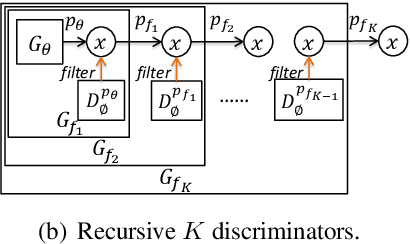
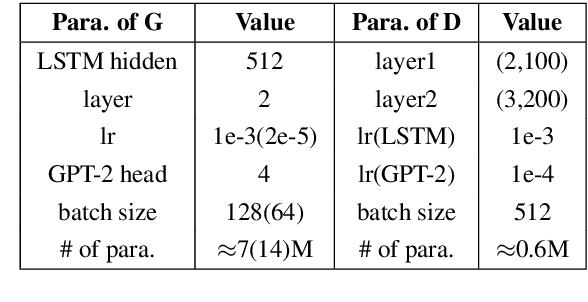
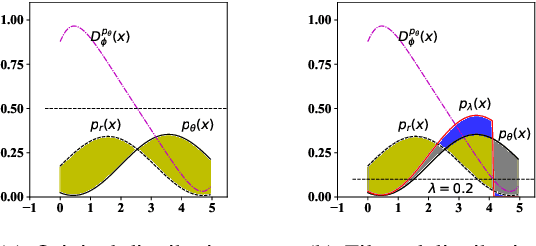
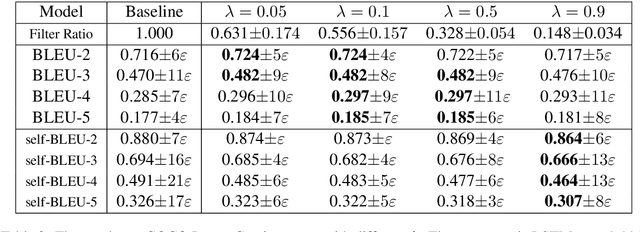
We propose a novel mechanism to improve an unconditional text generator with a discriminator, which is trained to estimate the probability that a sample comes from real or generated data. In contrast to recent discrete language generative adversarial networks (GAN) which update the parameters of the generator directly, our method only retains generated samples which are determined to come from real data with relatively high probability by the discriminator. This not only detects valuable information, but also avoids the mode collapse introduced by GAN. To the best of our knowledge, this is the first method which improves the neural language models (LM) trained with maximum likelihood estimation (MLE) by using a discriminator as a filter. Experimental results show that our mechanism improves both RNN-based and Transformer-based LMs when measuring in sample quality and sample diversity simultaneously at different softmax temperatures (a previously noted deficit of language GANs). Further, by recursively adding more discriminators, more powerful generators are created.
The Detection of Distributional Discrepancy for Text Generation
Sep 28, 2019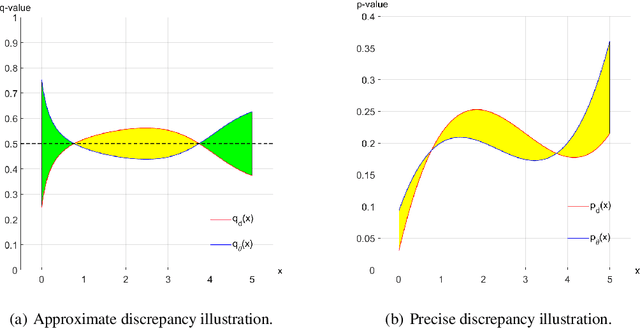


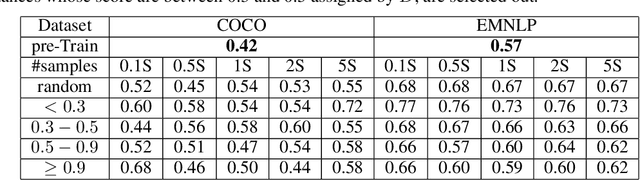
The text generated by neural language models is not as good as the real text. This means that their distributions are different. Generative Adversarial Nets (GAN) are used to alleviate it. However, some researchers argue that GAN variants do not work at all. When both sample quality (such as Bleu) and sample diversity (such as self-Bleu) are taken into account, the GAN variants even are worse than a well-adjusted language model. But, Bleu and self-Bleu can not precisely measure this distributional discrepancy. In fact, how to measure the distributional discrepancy between real text and generated text is still an open problem. In this paper, we theoretically propose two metric functions to measure the distributional difference between real text and generated text. Besides that, a method is put forward to estimate them. First, we evaluate language model with these two functions and find the difference is huge. Then, we try several methods to use the detected discrepancy signal to improve the generator. However the difference becomes even bigger than before. Experimenting on two existing language GANs, the distributional discrepancy between real text and generated text increases with more adversarial learning rounds. It demonstrates both of these language GANs fail.