 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMacro-Action-Based Multi-Agent/Robot Deep Reinforcement Learning under Partial Observability
Paper and Code
Oct 11, 2022
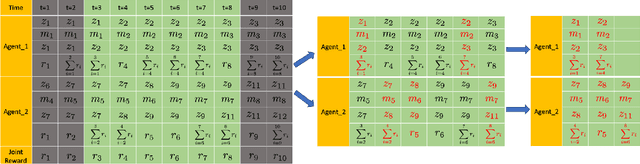
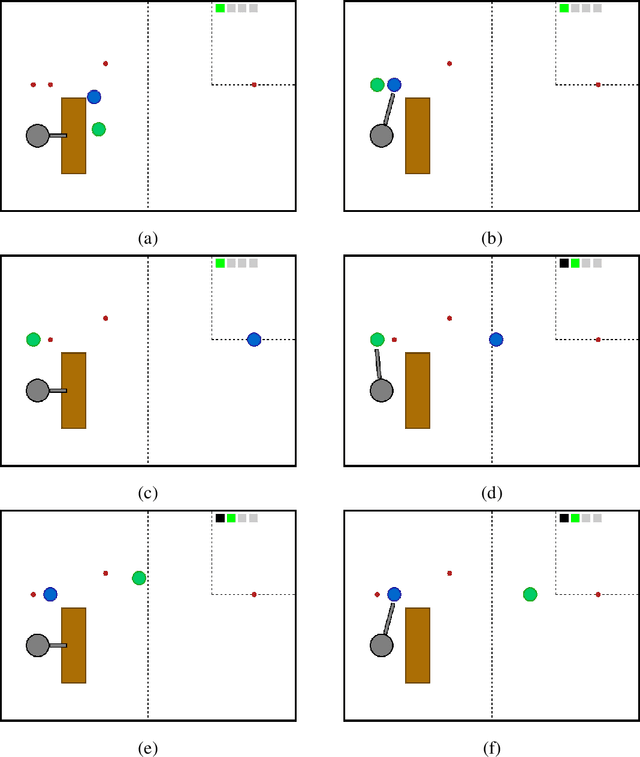
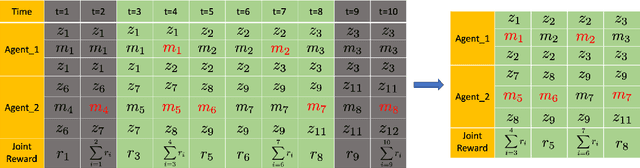
The state-of-the-art multi-agent reinforcement learning (MARL) methods have provided promising solutions to a variety of complex problems. Yet, these methods all assume that agents perform synchronized primitive-action executions so that they are not genuinely scalable to long-horizon real-world multi-agent/robot tasks that inherently require agents/robots to asynchronously reason about high-level action selection at varying time durations. The Macro-Action Decentralized Partially Observable Markov Decision Process (MacDec-POMDP) is a general formalization for asynchronous decision-making under uncertainty in fully cooperative multi-agent tasks. In this thesis, we first propose a group of value-based RL approaches for MacDec-POMDPs, where agents are allowed to perform asynchronous learning and decision-making with macro-action-value functions in three paradigms: decentralized learning and control, centralized learning and control, and centralized training for decentralized execution (CTDE). Building on the above work, we formulate a set of macro-action-based policy gradient algorithms under the three training paradigms, where agents are allowed to directly optimize their parameterized policies in an asynchronous manner. We evaluate our methods both in simulation and on real robots over a variety of realistic domains. Empirical results demonstrate the superiority of our approaches in large multi-agent problems and validate the effectiveness of our algorithms for learning high-quality and asynchronous solutions with macro-actions.