 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-motion as a structural prior for coherent and robust formation of cognitive maps
Dec 23, 2025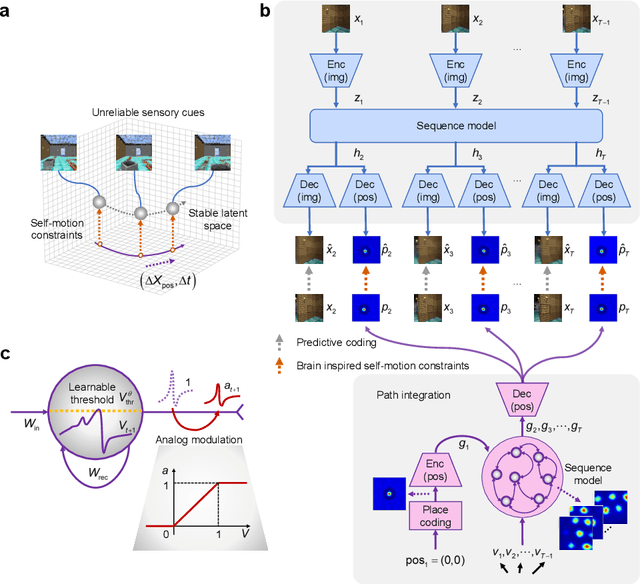
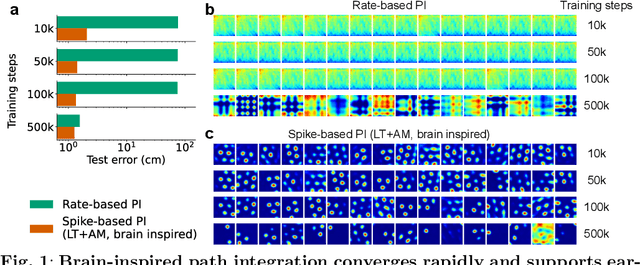
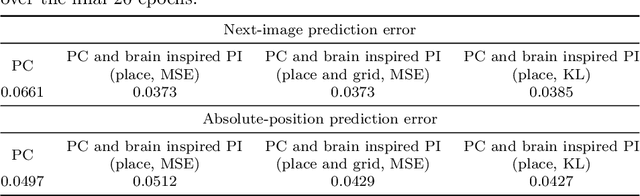
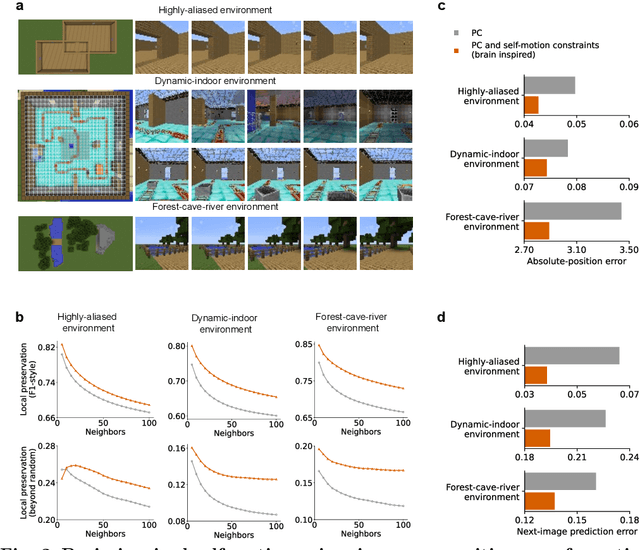
Most computational accounts of cognitive maps assume that stability is achieved primarily through sensory anchoring, with self-motion contributing to incremental positional updates only. However, biological spatial representations often remain coherent even when sensory cues degrade or conflict, suggesting that self-motion may play a deeper organizational role. Here, we show that self-motion can act as a structural prior that actively organizes the geometry of learned cognitive maps. We embed a path-integration-based motion prior in a predictive-coding framework, implemented using a capacity-efficient, brain-inspired recurrent mechanism combining spiking dynamics, analog modulation and adaptive thresholds. Across highly aliased, dynamically changing and naturalistic environments, this structural prior consistently stabilizes map formation, improving local topological fidelity, global positional accuracy and next-step prediction under sensory ambiguity. Mechanistic analyses reveal that the motion prior itself encodes geometrically precise trajectories under tight constraints of internal states and generalizes zero-shot to unseen environments, outperforming simpler motion-based constraints. Finally, deployment on a quadrupedal robot demonstrates that motion-derived structural priors enhance online landmark-based navigation under real-world sensory variability. Together, these results reframe self-motion as an organizing scaffold for coherent spatial representations, showing how brain-inspired principles can systematically strengthen spatial intelligence in embodied artificial agents.
OutSafe-Bench: A Benchmark for Multimodal Offensive Content Detection in Large Language Models
Nov 13, 2025



Since Multimodal Large Language Models (MLLMs) are increasingly being integrated into everyday tools and intelligent agents, growing concerns have arisen regarding their possible output of unsafe contents, ranging from toxic language and biased imagery to privacy violations and harmful misinformation. Current safety benchmarks remain highly limited in both modality coverage and performance evaluations, often neglecting the extensive landscape of content safety. In this work, we introduce OutSafe-Bench, the first most comprehensive content safety evaluation test suite designed for the multimodal era. OutSafe-Bench includes a large-scale dataset that spans four modalities, featuring over 18,000 bilingual (Chinese and English) text prompts, 4,500 images, 450 audio clips and 450 videos, all systematically annotated across nine critical content risk categories. In addition to the dataset, we introduce a Multidimensional Cross Risk Score (MCRS), a novel metric designed to model and assess overlapping and correlated content risks across different categories. To ensure fair and robust evaluation, we propose FairScore, an explainable automated multi-reviewer weighted aggregation framework. FairScore selects top-performing models as adaptive juries, thereby mitigating biases from single-model judgments and enhancing overall evaluation reliability. Our evaluation of nine state-of-the-art MLLMs reveals persistent and substantial safety vulnerabilities, underscoring the pressing need for robust safeguards in MLLMs.
SpiLiFormer: Enhancing Spiking Transformers with Lateral Inhibition
Mar 20, 2025Spiking Neural Networks (SNNs) based on Transformers have garnered significant attention due to their superior performance and high energy efficiency. However, the spiking attention modules of most existing Transformer-based SNNs are adapted from those of analog Transformers, failing to fully address the issue of over-allocating attention to irrelevant contexts. To fix this fundamental yet overlooked issue, we propose a Lateral Inhibition-inspired Spiking Transformer (SpiLiFormer). It emulates the brain's lateral inhibition mechanism, guiding the model to enhance attention to relevant tokens while suppressing attention to irrelevant ones. Our model achieves state-of-the-art (SOTA) performance across multiple datasets, including CIFAR-10 (+0.45%), CIFAR-100 (+0.48%), CIFAR10-DVS (+2.70%), N-Caltech101 (+1.94%), and ImageNet-1K (+1.6%). Notably, on the ImageNet-1K dataset, SpiLiFormer (69.9M parameters, 4 time steps, 384 resolution) outperforms E-SpikeFormer (173.0M parameters, 8 time steps, 384 resolution), a SOTA spiking Transformer, by 0.46% using only 39% of the parameters and half the time steps. Our code and training checkpoints will be released upon acceptance.
A Recurrent Spiking Network with Hierarchical Intrinsic Excitability Modulation for Schema Learning
Jan 24, 2025Schema, a form of structured knowledge that promotes transfer learning, is attracting growing attention in both neuroscience and artificial intelligence (AI). Current schema research in neural computation is largely constrained to a single behavioral paradigm and relies heavily on recurrent neural networks (RNNs) which lack the neural plausibility and biological interpretability. To address these limitations, this work first constructs a generalized behavioral paradigm framework for schema learning and introduces three novel cognitive tasks, thus supporting a comprehensive schema exploration. Second, we propose a new model using recurrent spiking neural networks with hierarchical intrinsic excitability modulation (HM-RSNNs). The top level of the model selects excitability properties for task-specific demands, while the bottom level fine-tunes these properties for intra-task problems. Finally, extensive visualization analyses of HM-RSNNs are conducted to showcase their computational advantages, track the intrinsic excitability evolution during schema learning, and examine neural coordination differences across tasks. Biologically inspired lesion studies further uncover task-specific distributions of intrinsic excitability within schemas. Experimental results show that HM-RSNNs significantly outperform RSNN baselines across all tasks and exceed RNNs in three novel cognitive tasks. Additionally, HM-RSNNs offer deeper insights into neural dynamics underlying schema learning.
Heterogeneous Federated Learning with Convolutional and Spiking Neural Networks
Jun 14, 2024Federated learning (FL) has emerged as a promising paradigm for training models on decentralized data while safeguarding data privacy. Most existing FL systems, however, assume that all machine learning models are of the same type, although it becomes more likely that different edge devices adopt different types of AI models, including both conventional analogue artificial neural networks (ANNs) and biologically more plausible spiking neural networks (SNNs). This diversity empowers the efficient handling of specific tasks and requirements, showcasing the adaptability and versatility of edge computing platforms. One main challenge of such heterogeneous FL system lies in effectively aggregating models from the local devices in a privacy-preserving manner. To address the above issue, this work benchmarks FL systems containing both convoluntional neural networks (CNNs) and SNNs by comparing various aggregation approaches, including federated CNNs, federated SNNs, federated CNNs for SNNs, federated SNNs for CNNs, and federated CNNs with SNN fusion. Experimental results demonstrate that the CNN-SNN fusion framework exhibits the best performance among the above settings on the MNIST dataset. Additionally, intriguing phenomena of competitive suppression are noted during the convergence process of multi-model FL.