 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLocal Advantage Actor-Critic for Robust Multi-Agent Deep Reinforcement Learning
Paper and Code
Nov 02, 2021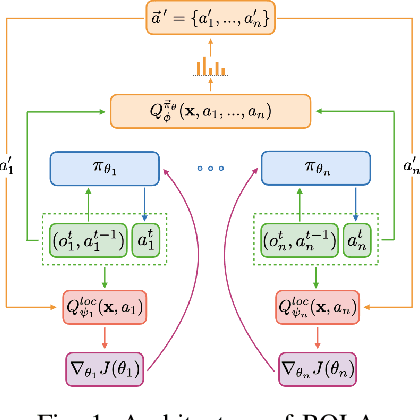
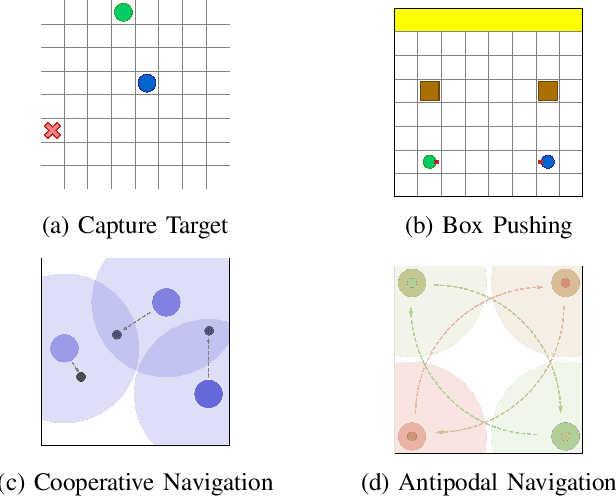
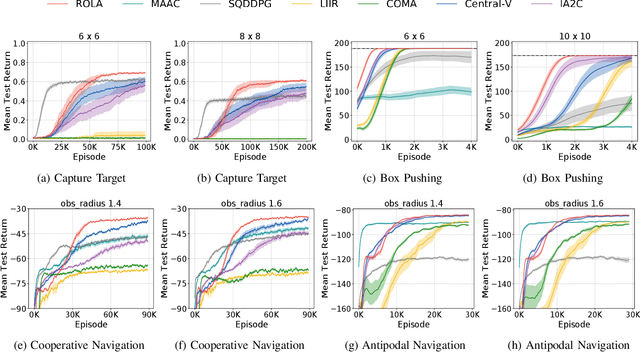
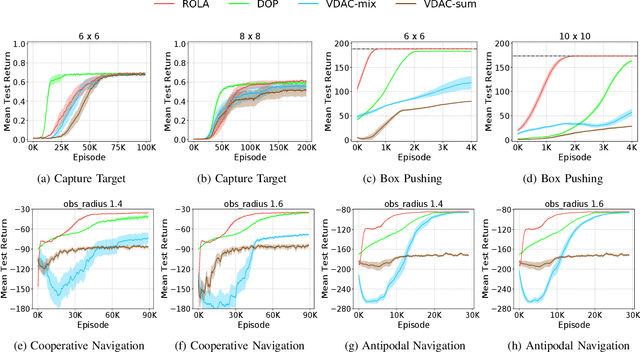
Policy gradient methods have become popular in multi-agent reinforcement learning, but they suffer from high variance due to the presence of environmental stochasticity and exploring agents (i.e., non-stationarity), which is potentially worsened by the difficulty in credit assignment. As a result, there is a need for a method that is not only capable of efficiently solving the above two problems but also robust enough to solve a variety of tasks. To this end, we propose a new multi-agent policy gradient method, called Robust Local Advantage (ROLA) Actor-Critic. ROLA allows each agent to learn an individual action-value function as a local critic as well as ameliorating environment non-stationarity via a novel centralized training approach based on a centralized critic. By using this local critic, each agent calculates a baseline to reduce variance on its policy gradient estimation, which results in an expected advantage action-value over other agents' choices that implicitly improves credit assignment. We evaluate ROLA across diverse benchmarks and show its robustness and effectiveness over a number of state-of-the-art multi-agent policy gradient algorithms.