 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUser Localization Based on Call Detail Records
Aug 20, 2021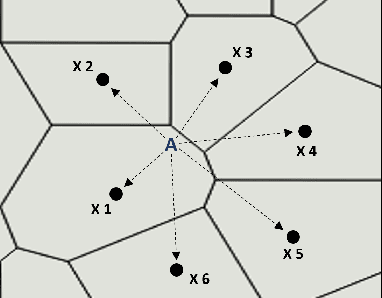

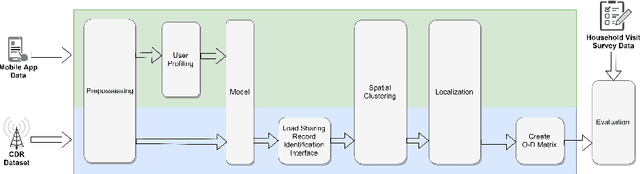

Understanding human mobility is essential for many fields, including transportation planning. Currently, surveys are the primary source for such analysis. However, in the recent past, many researchers have focused on Call Detail Records (CDR) for identifying travel patterns. CDRs have shown correlation to human mobility behavior. However, one of the main issues in using CDR data is that it is difficult to identify the precise location of the user due to the low spacial resolution of the data and other artifacts such as the load sharing effect. Existing approaches have certain limitations. Previous studies using CDRs do not consider the transmit power of cell towers when localizing the users and use an oversimplified approach to identify load sharing effects. Furthermore, they consider the entire population of users as one group neglecting the differences in mobility patterns of different segments of users. This research introduces a novel methodology to user position localization from CDRs through improved detection of load sharing effects, by taking the transmit power into account, and segmenting the users into distinct groups for the purpose of learning any parameters of the model. Moreover, this research uses several methods to address the existing limitations and validate the generated results using nearly 4 billion CDR data points with travel survey data and voluntarily collected mobile data.
Semi-Supervised Instance Population of an Ontology using Word Vector Embeddings
Sep 09, 2017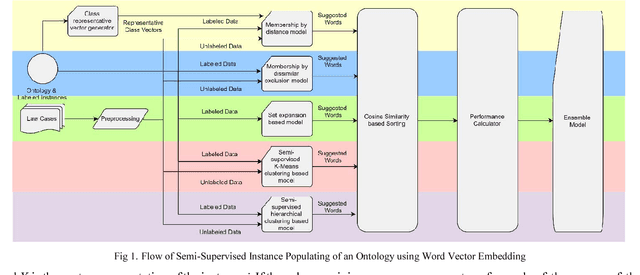
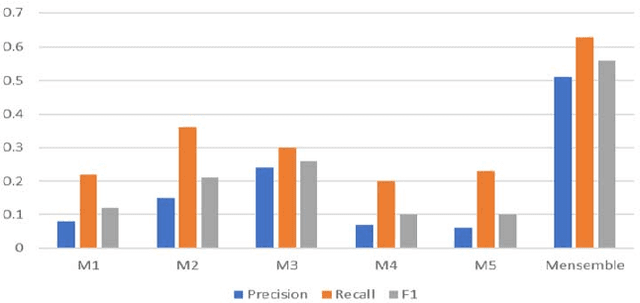
In many modern day systems such as information extraction and knowledge management agents, ontologies play a vital role in maintaining the concept hierarchies of the selected domain. However, ontology population has become a problematic process due to its nature of heavy coupling with manual human intervention. With the use of word embeddings in the field of natural language processing, it became a popular topic due to its ability to cope up with semantic sensitivity. Hence, in this study, we propose a novel way of semi-supervised ontology population through word embeddings as the basis. We built several models including traditional benchmark models and new types of models which are based on word embeddings. Finally, we ensemble them together to come up with a synergistic model with better accuracy. We demonstrate that our ensemble model can outperform the individual models.
Synergistic Union of Word2Vec and Lexicon for Domain Specific Semantic Similarity
Jun 09, 2017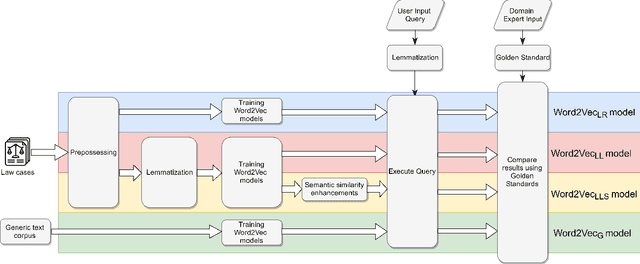
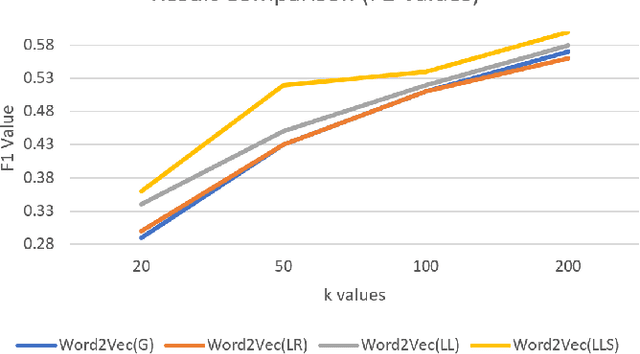
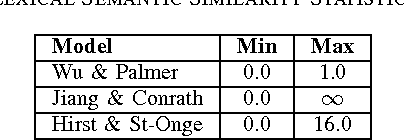
Semantic similarity measures are an important part in Natural Language Processing tasks. However Semantic similarity measures built for general use do not perform well within specific domains. Therefore in this study we introduce a domain specific semantic similarity measure that was created by the synergistic union of word2vec, a word embedding method that is used for semantic similarity calculation and lexicon based (lexical) semantic similarity methods. We prove that this proposed methodology out performs word embedding methods trained on generic corpus and methods trained on domain specific corpus but do not use lexical semantic similarity methods to augment the results. Further, we prove that text lemmatization can improve the performance of word embedding methods.
Deriving a Representative Vector for Ontology Classes with Instance Word Vector Embeddings
Jun 08, 2017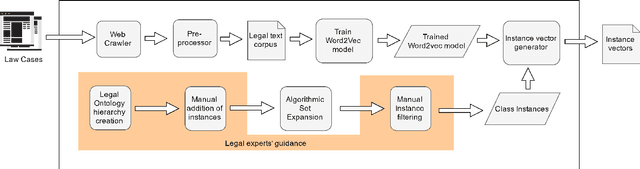
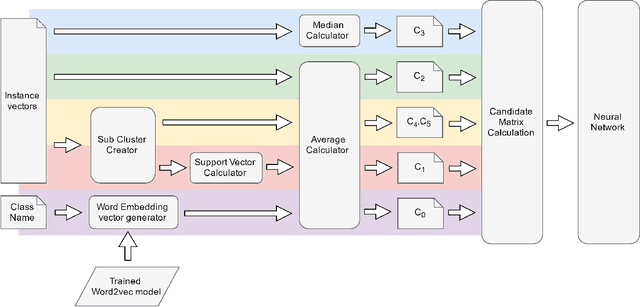
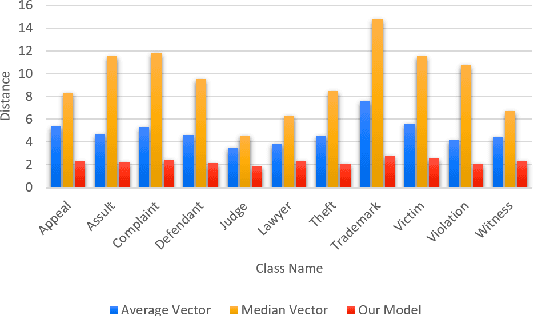
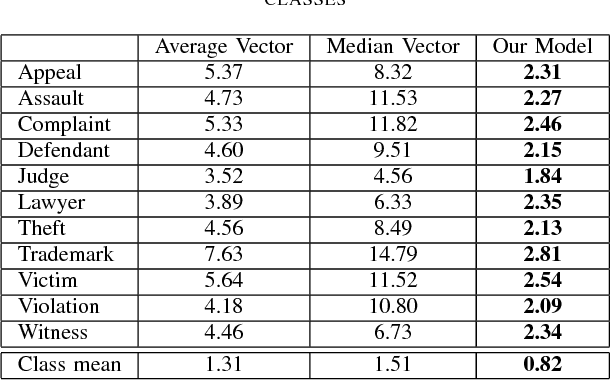
Selecting a representative vector for a set of vectors is a very common requirement in many algorithmic tasks. Traditionally, the mean or median vector is selected. Ontology classes are sets of homogeneous instance objects that can be converted to a vector space by word vector embeddings. This study proposes a methodology to derive a representative vector for ontology classes whose instances were converted to the vector space. We start by deriving five candidate vectors which are then used to train a machine learning model that would calculate a representative vector for the class. We show that our methodology out-performs the traditional mean and median vector representations.