 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCritical Sentence Identification in Legal Cases Using Multi-Class Classification
Nov 14, 2021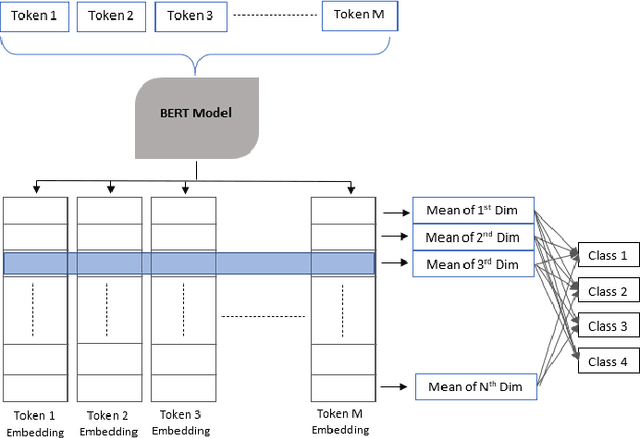
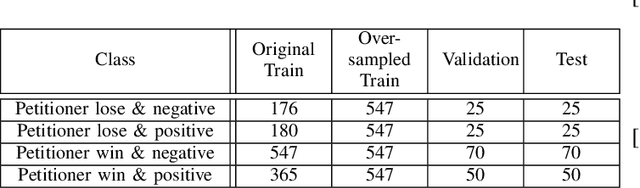
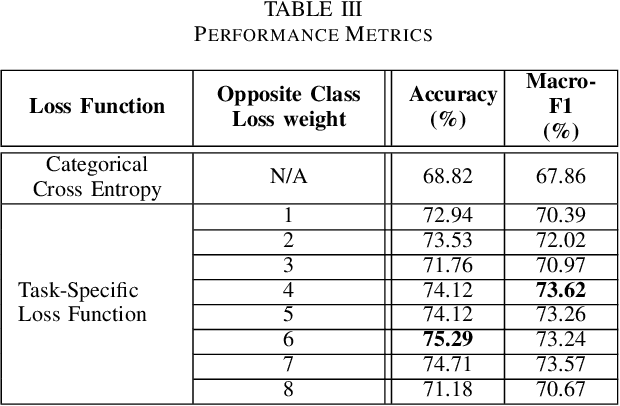
Inherently, the legal domain contains a vast amount of data in text format. Therefore it requires the application of Natural Language Processing (NLP) to cater to the analytically demanding needs of the domain. The advancement of NLP is spreading through various domains, such as the legal domain, in forms of practical applications and academic research. Identifying critical sentences, facts and arguments in a legal case is a tedious task for legal professionals. In this research we explore the usage of sentence embeddings for multi-class classification to identify critical sentences in a legal case, in the perspective of the main parties present in the case. In addition, a task-specific loss function is defined in order to improve the accuracy restricted by the straightforward use of categorical cross entropy loss.
User Localization Based on Call Detail Records
Aug 20, 2021

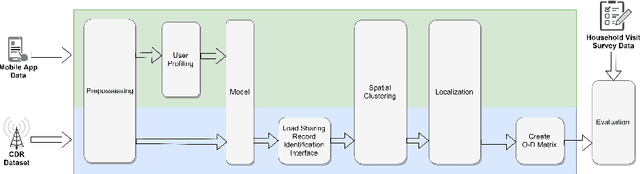

Understanding human mobility is essential for many fields, including transportation planning. Currently, surveys are the primary source for such analysis. However, in the recent past, many researchers have focused on Call Detail Records (CDR) for identifying travel patterns. CDRs have shown correlation to human mobility behavior. However, one of the main issues in using CDR data is that it is difficult to identify the precise location of the user due to the low spacial resolution of the data and other artifacts such as the load sharing effect. Existing approaches have certain limitations. Previous studies using CDRs do not consider the transmit power of cell towers when localizing the users and use an oversimplified approach to identify load sharing effects. Furthermore, they consider the entire population of users as one group neglecting the differences in mobility patterns of different segments of users. This research introduces a novel methodology to user position localization from CDRs through improved detection of load sharing effects, by taking the transmit power into account, and segmenting the users into distinct groups for the purpose of learning any parameters of the model. Moreover, this research uses several methods to address the existing limitations and validate the generated results using nearly 4 billion CDR data points with travel survey data and voluntarily collected mobile data.
Rule-Based Approach for Party-Based Sentiment Analysis in Legal Opinion Texts
Nov 13, 2020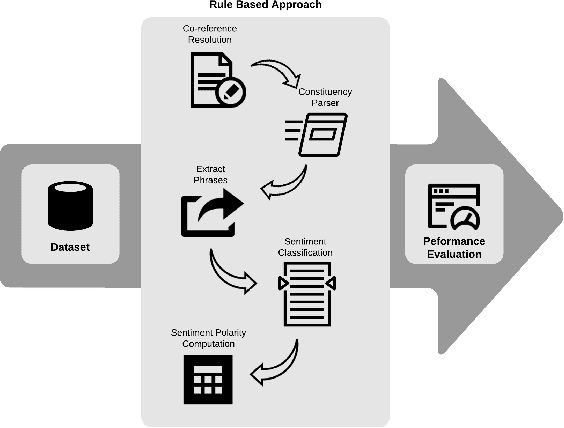
A document which elaborates opinions and arguments related to the previous court cases is known as a legal opinion text. Lawyers and legal officials have to spend considerable effort and time to obtain the required information manually from those documents when dealing with new legal cases. Hence, it provides much convenience to those individuals if there is a way to automate the process of extracting information from legal opinion texts. Party-based sentiment analysis will play a key role in the automation system by identifying opinion values with respect to each legal parties in legal texts.
SigmaLaw-ABSA: Dataset for Aspect-Based Sentiment Analysis in Legal Opinion Texts
Nov 12, 2020
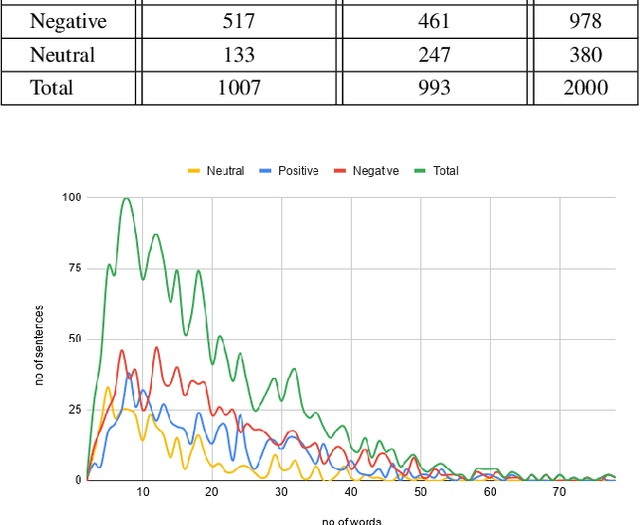
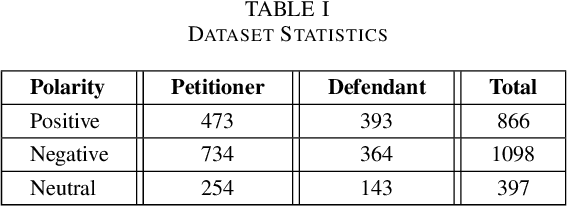
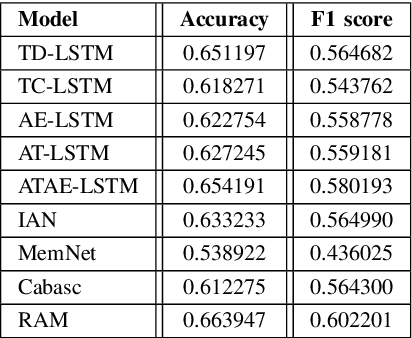
Aspect-Based Sentiment Analysis (ABSA) has been prominent and ongoing research over many different domains, but it is not widely discussed in the legal domain. A number of publicly available datasets for a wide range of domains usually fulfill the needs of researchers to perform their studies in the field of ABSA. To the best of our knowledge, there is no publicly available dataset for the Aspect (Party) Based Sentiment Analysis for legal opinion texts. Therefore, creating a publicly available dataset for the research of ABSA for the legal domain can be considered as a task with significant importance. In this study, we introduce a manually annotated legal opinion text dataset (SigmaLaw-ABSA) intended towards facilitating researchers for ABSA tasks in the legal domain. SigmaLaw-ABSA consists of legal opinion texts in the English language which have been annotated by human judges. This study discusses the sub-tasks of ABSA relevant to the legal domain and how to use the dataset to perform them. This paper also describes the statistics of the dataset and as a baseline, we present some results on the performance of some existing deep learning based systems on the SigmaLaw-ABSA dataset.
Effective Approach to Develop a Sentiment Annotator For Legal Domain in a Low Resource Setting
Oct 31, 2020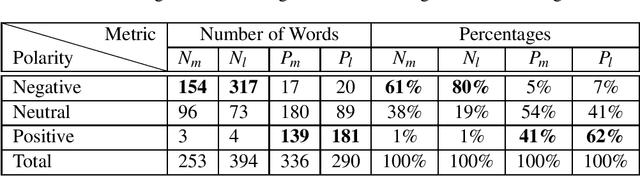
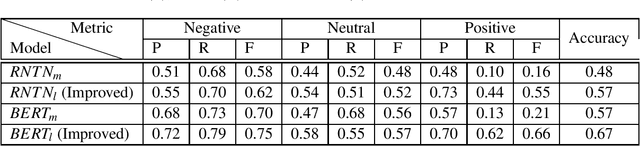
Analyzing the sentiments of legal opinions available in Legal Opinion Texts can facilitate several use cases such as legal judgement prediction, contradictory statements identification and party-based sentiment analysis. However, the task of developing a legal domain specific sentiment annotator is challenging due to resource constraints such as lack of domain specific labelled data and domain expertise. In this study, we propose novel techniques that can be used to develop a sentiment annotator for the legal domain while minimizing the need for manual annotations of data.
Shift-of-Perspective Identification Within Legal Cases
Jul 17, 2019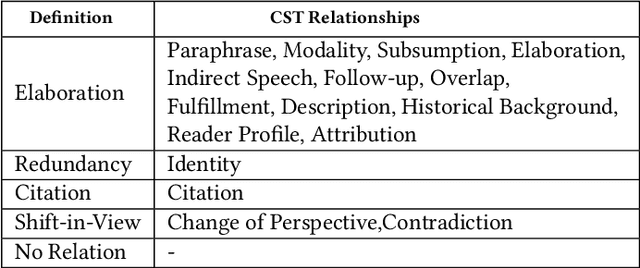
Arguments, counter-arguments, facts, and evidence obtained via documents related to previous court cases are of essential need for legal professionals. Therefore, the process of automatic information extraction from documents containing legal opinions related to court cases can be considered to be of significant importance. This study is focused on the identification of sentences in legal opinion texts which convey different perspectives on a certain topic or entity. We combined several approaches based on semantic analysis, open information extraction, and sentiment analysis to achieve our objective. Then, our methodology was evaluated with the help of human judges. The outcomes of the evaluation demonstrate that our system is successful in detecting situations where two sentences deliver different opinions on the same topic or entity. The proposed methodology can be used to facilitate other information extraction tasks related to the legal domain. One such task is the automated detection of counter arguments for a given argument. Another is the identification of opponent parties in a court case.
Fast Approach to Build an Automatic Sentiment Annotator for Legal Domain using Transfer Learning
Oct 03, 2018
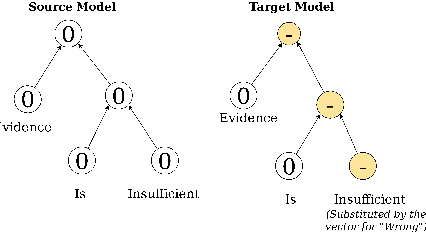

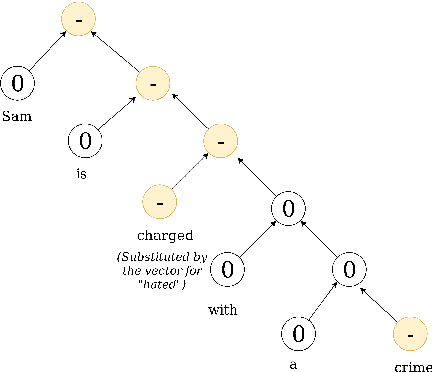
This study proposes a novel way of identifying the sentiment of the phrases used in the legal domain. The added complexity of the language used in law, and the inability of the existing systems to accurately predict the sentiments of words in law are the main motivations behind this study. This is a transfer learning approach, which can be used for other domain adaptation tasks as well. The proposed methodology achieves an improvement of over 6\% compared to the source model's accuracy in the legal domain.
Identifying Relationships Among Sentences in Court Case Transcripts Using Discourse Relations
Sep 15, 2018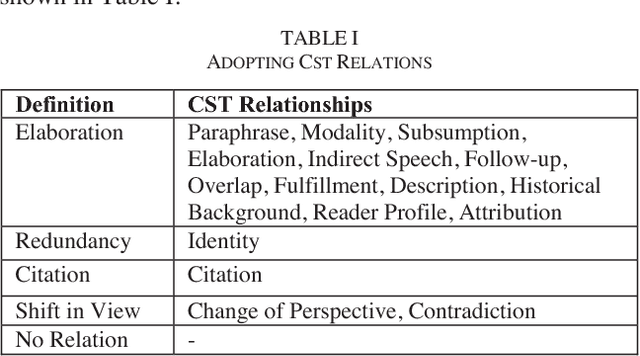
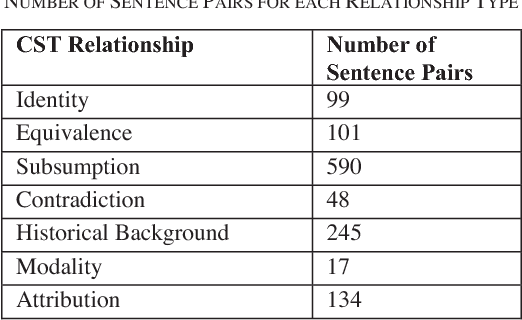
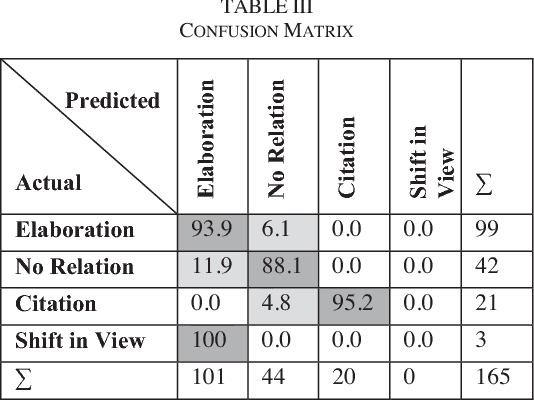
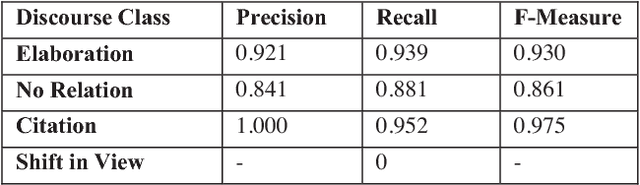
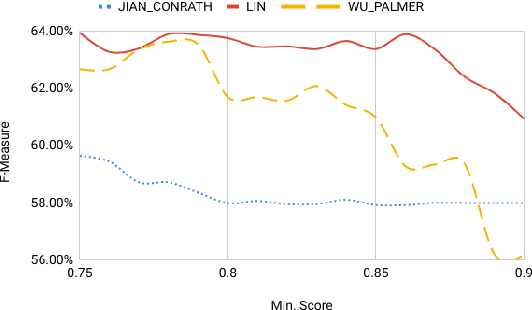
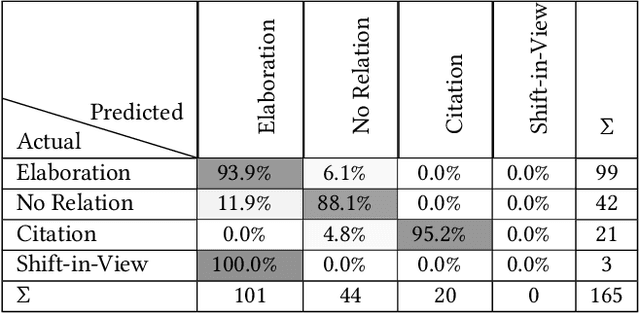
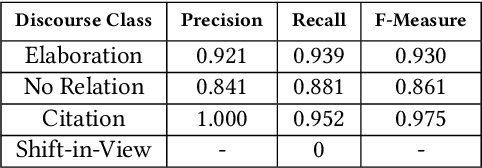
Case Law has a significant impact on the proceedings of legal cases. Therefore, the information that can be obtained from previous court cases is valuable to lawyers and other legal officials when performing their duties. This paper describes a methodology of applying discourse relations between sentences when processing text documents related to the legal domain. In this study, we developed a mechanism to classify the relationships that can be observed among sentences in transcripts of United States court cases. First, we defined relationship types that can be observed between sentences in court case transcripts. Then we classified pairs of sentences according to the relationship type by combining a machine learning model and a rule-based approach. The results obtained through our system were evaluated using human judges. To the best of our knowledge, this is the first study where discourse relationships between sentences have been used to determine relationships among sentences in legal court case transcripts.
Semi-Supervised Instance Population of an Ontology using Word Vector Embeddings
Sep 09, 2017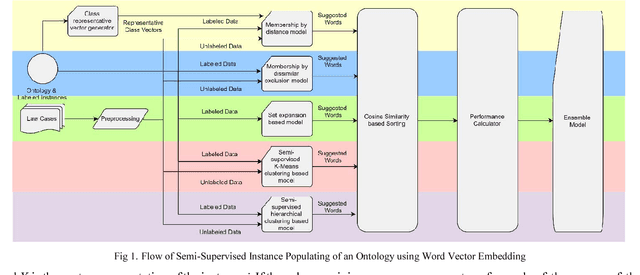
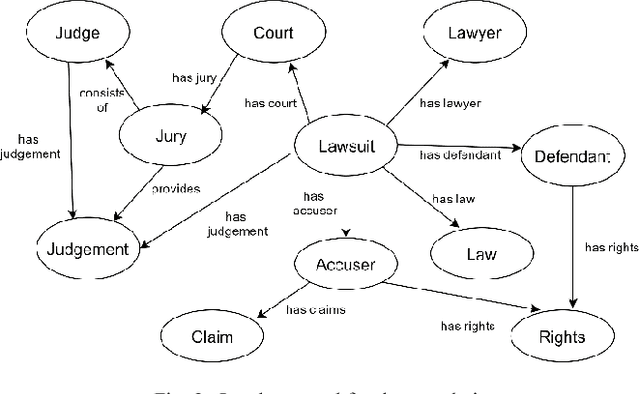
In many modern day systems such as information extraction and knowledge management agents, ontologies play a vital role in maintaining the concept hierarchies of the selected domain. However, ontology population has become a problematic process due to its nature of heavy coupling with manual human intervention. With the use of word embeddings in the field of natural language processing, it became a popular topic due to its ability to cope up with semantic sensitivity. Hence, in this study, we propose a novel way of semi-supervised ontology population through word embeddings as the basis. We built several models including traditional benchmark models and new types of models which are based on word embeddings. Finally, we ensemble them together to come up with a synergistic model with better accuracy. We demonstrate that our ensemble model can outperform the individual models.
Synergistic Union of Word2Vec and Lexicon for Domain Specific Semantic Similarity
Jun 09, 2017
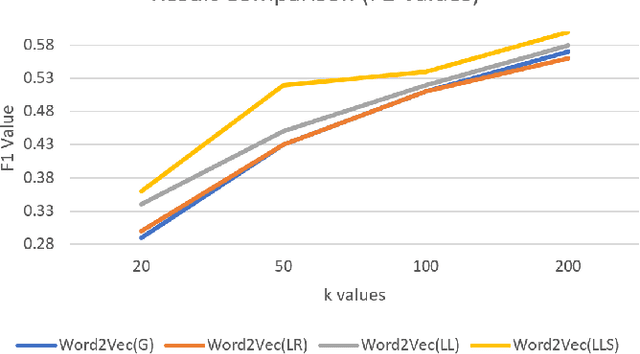
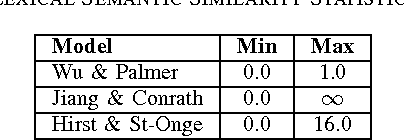
Semantic similarity measures are an important part in Natural Language Processing tasks. However Semantic similarity measures built for general use do not perform well within specific domains. Therefore in this study we introduce a domain specific semantic similarity measure that was created by the synergistic union of word2vec, a word embedding method that is used for semantic similarity calculation and lexicon based (lexical) semantic similarity methods. We prove that this proposed methodology out performs word embedding methods trained on generic corpus and methods trained on domain specific corpus but do not use lexical semantic similarity methods to augment the results. Further, we prove that text lemmatization can improve the performance of word embedding methods.