 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIdentifying Relationships Among Sentences in Court Case Transcripts Using Discourse Relations
Paper and Code
Sep 15, 2018
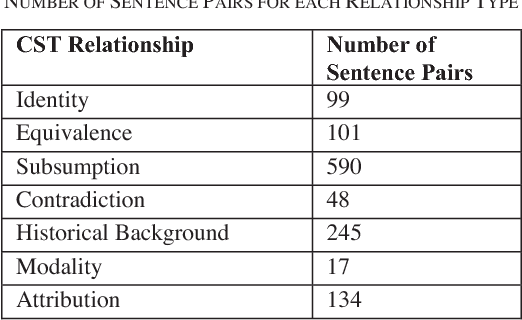
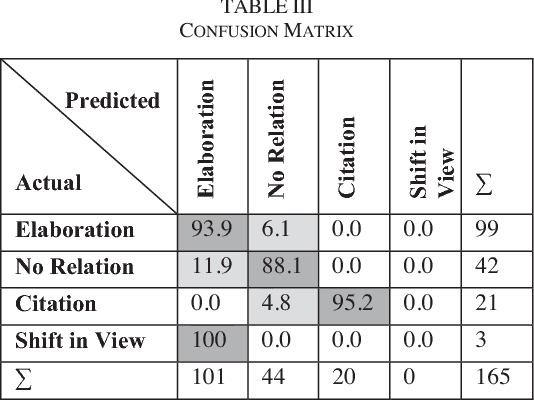
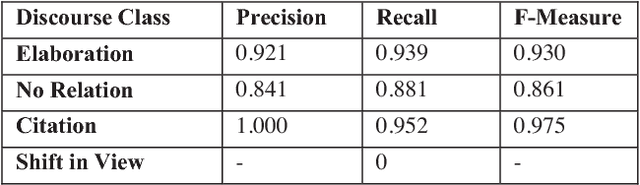
Case Law has a significant impact on the proceedings of legal cases. Therefore, the information that can be obtained from previous court cases is valuable to lawyers and other legal officials when performing their duties. This paper describes a methodology of applying discourse relations between sentences when processing text documents related to the legal domain. In this study, we developed a mechanism to classify the relationships that can be observed among sentences in transcripts of United States court cases. First, we defined relationship types that can be observed between sentences in court case transcripts. Then we classified pairs of sentences according to the relationship type by combining a machine learning model and a rule-based approach. The results obtained through our system were evaluated using human judges. To the best of our knowledge, this is the first study where discourse relationships between sentences have been used to determine relationships among sentences in legal court case transcripts.