 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFast Approach to Build an Automatic Sentiment Annotator for Legal Domain using Transfer Learning
Oct 03, 2018
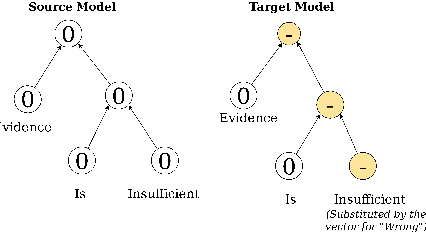

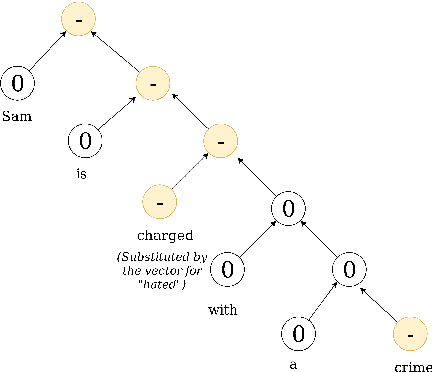
This study proposes a novel way of identifying the sentiment of the phrases used in the legal domain. The added complexity of the language used in law, and the inability of the existing systems to accurately predict the sentiments of words in law are the main motivations behind this study. This is a transfer learning approach, which can be used for other domain adaptation tasks as well. The proposed methodology achieves an improvement of over 6\% compared to the source model's accuracy in the legal domain.
Identifying Relationships Among Sentences in Court Case Transcripts Using Discourse Relations
Sep 15, 2018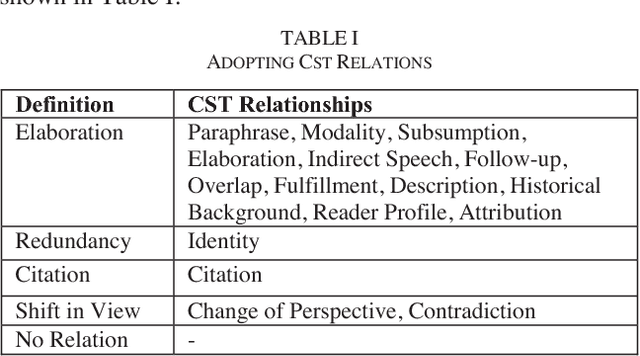
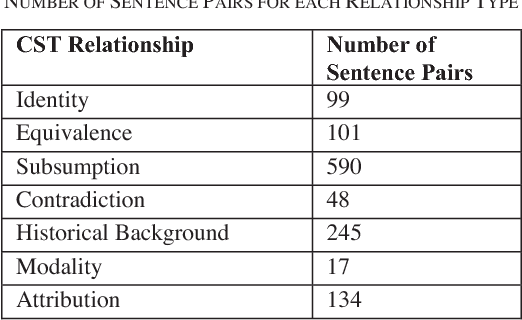
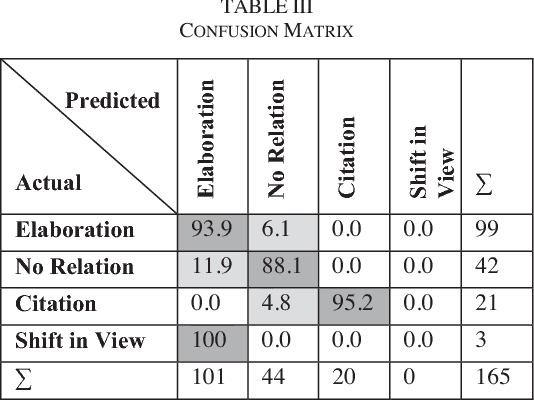
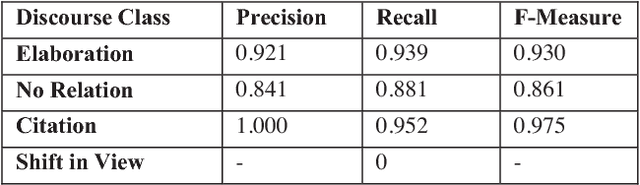
Case Law has a significant impact on the proceedings of legal cases. Therefore, the information that can be obtained from previous court cases is valuable to lawyers and other legal officials when performing their duties. This paper describes a methodology of applying discourse relations between sentences when processing text documents related to the legal domain. In this study, we developed a mechanism to classify the relationships that can be observed among sentences in transcripts of United States court cases. First, we defined relationship types that can be observed between sentences in court case transcripts. Then we classified pairs of sentences according to the relationship type by combining a machine learning model and a rule-based approach. The results obtained through our system were evaluated using human judges. To the best of our knowledge, this is the first study where discourse relationships between sentences have been used to determine relationships among sentences in legal court case transcripts.