Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFast Approach to Build an Automatic Sentiment Annotator for Legal Domain using Transfer Learning
Paper and Code
Oct 03, 2018
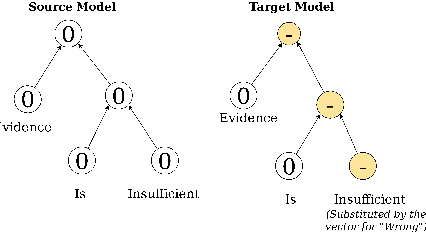

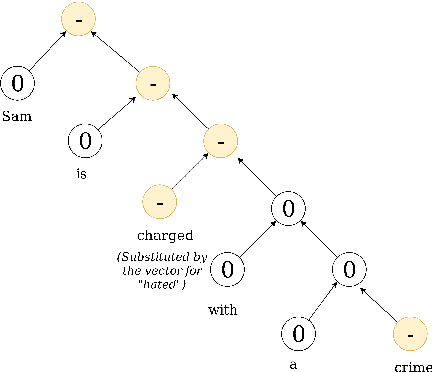
This study proposes a novel way of identifying the sentiment of the phrases used in the legal domain. The added complexity of the language used in law, and the inability of the existing systems to accurately predict the sentiments of words in law are the main motivations behind this study. This is a transfer learning approach, which can be used for other domain adaptation tasks as well. The proposed methodology achieves an improvement of over 6\% compared to the source model's accuracy in the legal domain.
* 9 pages, 3 figures
View paper on