 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemi-Supervised Instance Population of an Ontology using Word Vector Embeddings
Paper and Code
Sep 09, 2017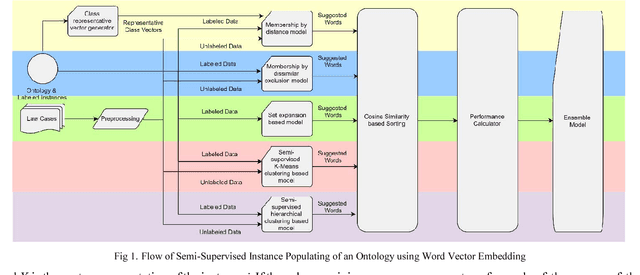
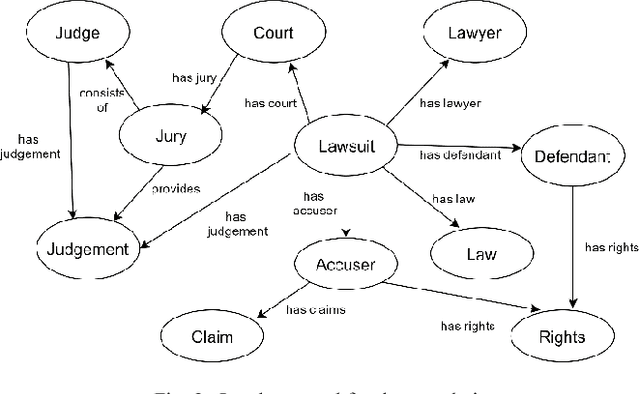
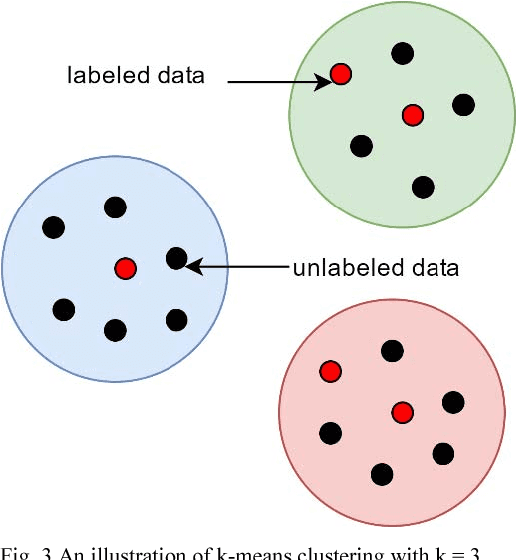
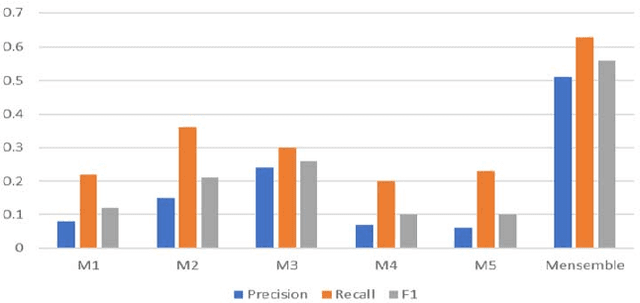
In many modern day systems such as information extraction and knowledge management agents, ontologies play a vital role in maintaining the concept hierarchies of the selected domain. However, ontology population has become a problematic process due to its nature of heavy coupling with manual human intervention. With the use of word embeddings in the field of natural language processing, it became a popular topic due to its ability to cope up with semantic sensitivity. Hence, in this study, we propose a novel way of semi-supervised ontology population through word embeddings as the basis. We built several models including traditional benchmark models and new types of models which are based on word embeddings. Finally, we ensemble them together to come up with a synergistic model with better accuracy. We demonstrate that our ensemble model can outperform the individual models.