 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRule-Based Approach for Party-Based Sentiment Analysis in Legal Opinion Texts
Nov 13, 2020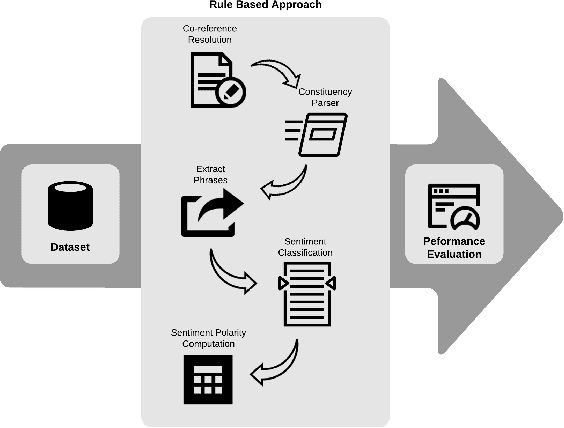
A document which elaborates opinions and arguments related to the previous court cases is known as a legal opinion text. Lawyers and legal officials have to spend considerable effort and time to obtain the required information manually from those documents when dealing with new legal cases. Hence, it provides much convenience to those individuals if there is a way to automate the process of extracting information from legal opinion texts. Party-based sentiment analysis will play a key role in the automation system by identifying opinion values with respect to each legal parties in legal texts.
SigmaLaw-ABSA: Dataset for Aspect-Based Sentiment Analysis in Legal Opinion Texts
Nov 12, 2020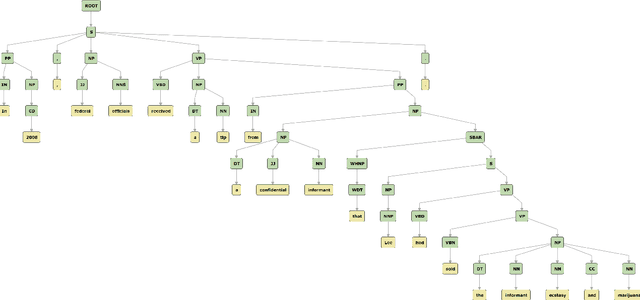
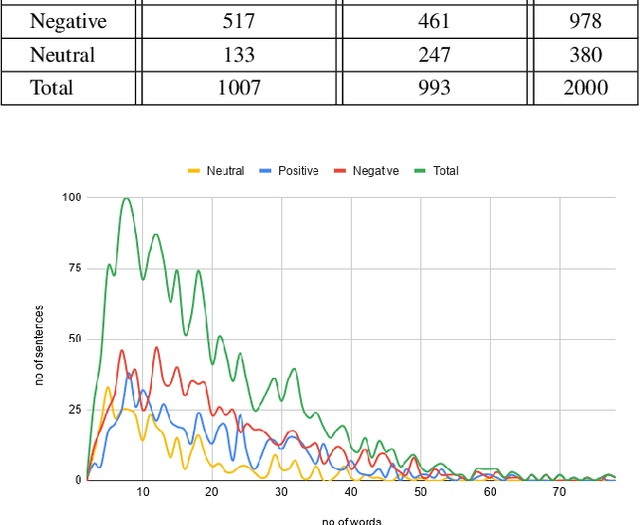
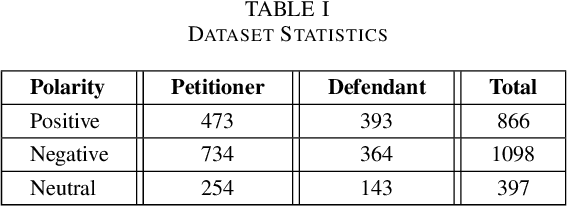
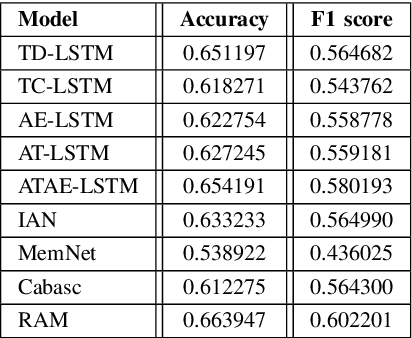
Aspect-Based Sentiment Analysis (ABSA) has been prominent and ongoing research over many different domains, but it is not widely discussed in the legal domain. A number of publicly available datasets for a wide range of domains usually fulfill the needs of researchers to perform their studies in the field of ABSA. To the best of our knowledge, there is no publicly available dataset for the Aspect (Party) Based Sentiment Analysis for legal opinion texts. Therefore, creating a publicly available dataset for the research of ABSA for the legal domain can be considered as a task with significant importance. In this study, we introduce a manually annotated legal opinion text dataset (SigmaLaw-ABSA) intended towards facilitating researchers for ABSA tasks in the legal domain. SigmaLaw-ABSA consists of legal opinion texts in the English language which have been annotated by human judges. This study discusses the sub-tasks of ABSA relevant to the legal domain and how to use the dataset to perform them. This paper also describes the statistics of the dataset and as a baseline, we present some results on the performance of some existing deep learning based systems on the SigmaLaw-ABSA dataset.