 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnalysis of the MICCAI Brain Tumor Segmentation -- Metastases (BraTS-METS) 2025 Lighthouse Challenge: Brain Metastasis Segmentation on Pre- and Post-treatment MRI
Apr 16, 2025Despite continuous advancements in cancer treatment, brain metastatic disease remains a significant complication of primary cancer and is associated with an unfavorable prognosis. One approach for improving diagnosis, management, and outcomes is to implement algorithms based on artificial intelligence for the automated segmentation of both pre- and post-treatment MRI brain images. Such algorithms rely on volumetric criteria for lesion identification and treatment response assessment, which are still not available in clinical practice. Therefore, it is critical to establish tools for rapid volumetric segmentations methods that can be translated to clinical practice and that are trained on high quality annotated data. The BraTS-METS 2025 Lighthouse Challenge aims to address this critical need by establishing inter-rater and intra-rater variability in dataset annotation by generating high quality annotated datasets from four individual instances of segmentation by neuroradiologists while being recorded on video (two instances doing "from scratch" and two instances after AI pre-segmentation). This high-quality annotated dataset will be used for testing phase in 2025 Lighthouse challenge and will be publicly released at the completion of the challenge. The 2025 Lighthouse challenge will also release the 2023 and 2024 segmented datasets that were annotated using an established pipeline of pre-segmentation, student annotation, two neuroradiologists checking, and one neuroradiologist finalizing the process. It builds upon its previous edition by including post-treatment cases in the dataset. Using these high-quality annotated datasets, the 2025 Lighthouse challenge plans to test benchmark algorithms for automated segmentation of pre-and post-treatment brain metastases (BM), trained on diverse and multi-institutional datasets of MRI images obtained from patients with brain metastases.
SMILES-Mamba: Chemical Mamba Foundation Models for Drug ADMET Prediction
Aug 11, 2024
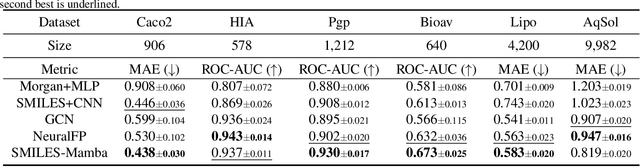


In drug discovery, predicting the absorption, distribution, metabolism, excretion, and toxicity (ADMET) properties of small-molecule drugs is critical for ensuring safety and efficacy. However, the process of accurately predicting these properties is often resource-intensive and requires extensive experimental data. To address this challenge, we propose SMILES-Mamba, a two-stage model that leverages both unlabeled and labeled data through a combination of self-supervised pretraining and fine-tuning strategies. The model first pre-trains on a large corpus of unlabeled SMILES strings to capture the underlying chemical structure and relationships, before being fine-tuned on smaller, labeled datasets specific to ADMET tasks. Our results demonstrate that SMILES-Mamba exhibits competitive performance across 22 ADMET datasets, achieving the highest score in 14 tasks, highlighting the potential of self-supervised learning in improving molecular property prediction. This approach not only enhances prediction accuracy but also reduces the dependence on large, labeled datasets, offering a promising direction for future research in drug discovery.