 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSMILES-Mamba: Chemical Mamba Foundation Models for Drug ADMET Prediction
Aug 11, 2024
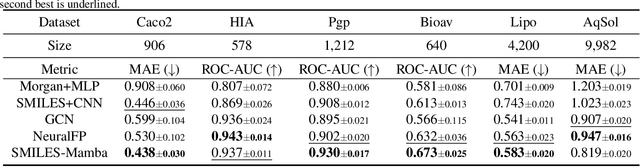


In drug discovery, predicting the absorption, distribution, metabolism, excretion, and toxicity (ADMET) properties of small-molecule drugs is critical for ensuring safety and efficacy. However, the process of accurately predicting these properties is often resource-intensive and requires extensive experimental data. To address this challenge, we propose SMILES-Mamba, a two-stage model that leverages both unlabeled and labeled data through a combination of self-supervised pretraining and fine-tuning strategies. The model first pre-trains on a large corpus of unlabeled SMILES strings to capture the underlying chemical structure and relationships, before being fine-tuned on smaller, labeled datasets specific to ADMET tasks. Our results demonstrate that SMILES-Mamba exhibits competitive performance across 22 ADMET datasets, achieving the highest score in 14 tasks, highlighting the potential of self-supervised learning in improving molecular property prediction. This approach not only enhances prediction accuracy but also reduces the dependence on large, labeled datasets, offering a promising direction for future research in drug discovery.
Uncertainty Quantification on Clinical Trial Outcome Prediction
Jan 07, 2024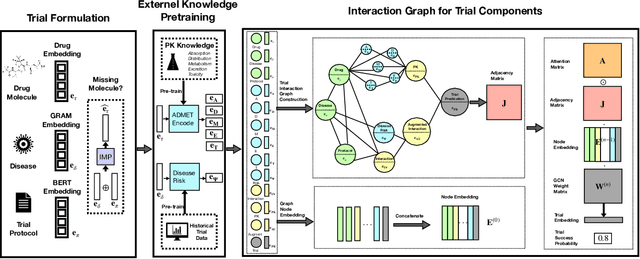
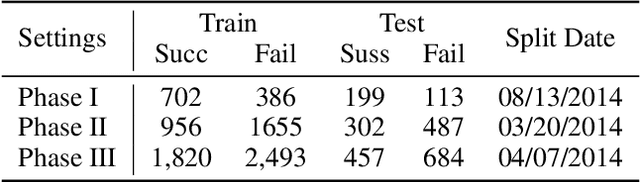
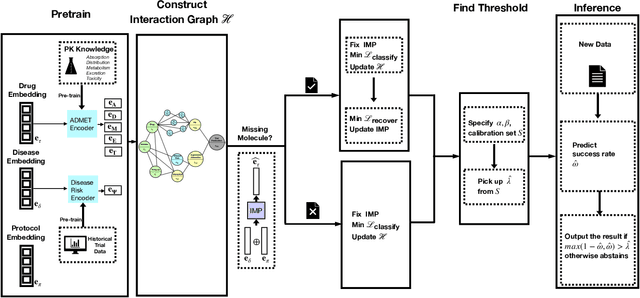

The importance of uncertainty quantification is increasingly recognized in the diverse field of machine learning. Accurately assessing model prediction uncertainty can help provide deeper understanding and confidence for researchers and practitioners. This is especially critical in medical diagnosis and drug discovery areas, where reliable predictions directly impact research quality and patient health. In this paper, we proposed incorporating uncertainty quantification into clinical trial outcome predictions. Our main goal is to enhance the model's ability to discern nuanced differences, thereby significantly improving its overall performance. We have adopted a selective classification approach to fulfill our objective, integrating it seamlessly with the Hierarchical Interaction Network (HINT), which is at the forefront of clinical trial prediction modeling. Selective classification, encompassing a spectrum of methods for uncertainty quantification, empowers the model to withhold decision-making in the face of samples marked by ambiguity or low confidence, thereby amplifying the accuracy of predictions for the instances it chooses to classify. A series of comprehensive experiments demonstrate that incorporating selective classification into clinical trial predictions markedly enhances the model's performance, as evidenced by significant upticks in pivotal metrics such as PR-AUC, F1, ROC-AUC, and overall accuracy. Specifically, the proposed method achieved 32.37\%, 21.43\%, and 13.27\% relative improvement on PR-AUC over the base model (HINT) in phase I, II, and III trial outcome prediction, respectively. When predicting phase III, our method reaches 0.9022 PR-AUC scores. These findings illustrate the robustness and prospective utility of this strategy within the area of clinical trial predictions, potentially setting a new benchmark in the field.