 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDual-Attention Heterogeneous GNN for Multi-robot Collaborative Area Search via Deep Reinforcement Learning
Jan 07, 2026In multi-robot collaborative area search, a key challenge is to dynamically balance the two objectives of exploring unknown areas and covering specific targets to be rescued. Existing methods are often constrained by homogeneous graph representations, thus failing to model and balance these distinct tasks. To address this problem, we propose a Dual-Attention Heterogeneous Graph Neural Network (DA-HGNN) trained using deep reinforcement learning. Our method constructs a heterogeneous graph that incorporates three entity types: robot nodes, frontier nodes, and interesting nodes, as well as their historical states. The dual-attention mechanism comprises the relational-aware attention and type-aware attention operations. The relational-aware attention captures the complex spatio-temporal relationships among robots and candidate goals. Building on this relational-aware heterogeneous graph, the type-aware attention separately computes the relevance between robots and each goal type (frontiers vs. points of interest), thereby decoupling the exploration and coverage from the unified tasks. Extensive experiments conducted in interactive 3D scenarios within the iGibson simulator, leveraging the Gibson and MatterPort3D datasets, validate the superior scalability and generalization capability of the proposed approach.
Autonomous and Adaptive Role Selection for Multi-robot Collaborative Area Search Based on Deep Reinforcement Learning
Dec 04, 2023

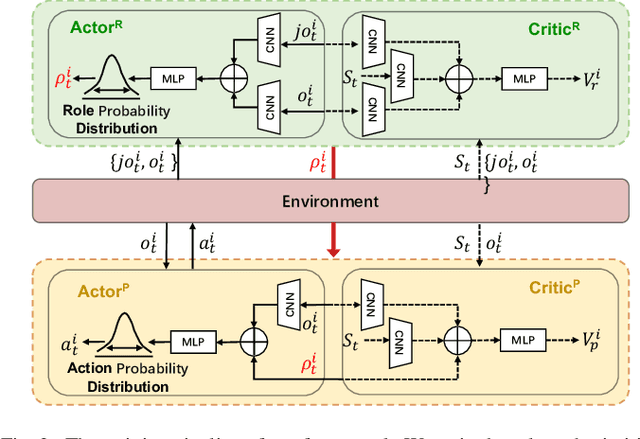

In the tasks of multi-robot collaborative area search, we propose the unified approach for simultaneous mapping for sensing more targets (exploration) while searching and locating the targets (coverage). Specifically, we implement a hierarchical multi-agent reinforcement learning algorithm to decouple task planning from task execution. The role concept is integrated into the upper-level task planning for role selection, which enables robots to learn the role based on the state status from the upper-view. Besides, an intelligent role switching mechanism enables the role selection module to function between two timesteps, promoting both exploration and coverage interchangeably. Then the primitive policy learns how to plan based on their assigned roles and local observation for sub-task execution. The well-designed experiments show the scalability and generalization of our method compared with state-of-the-art approaches in the scenes with varying complexity and number of robots.
Dual Clustering Co-teaching with Consistent Sample Mining for Unsupervised Person Re-Identification
Oct 07, 2022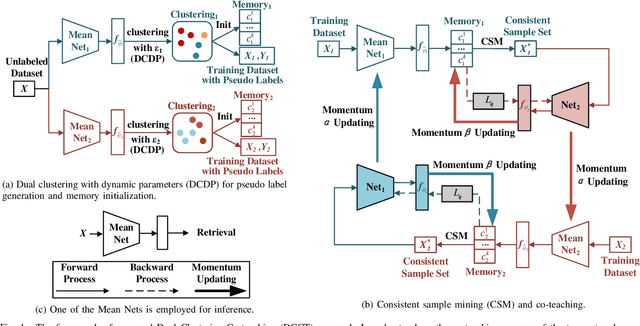
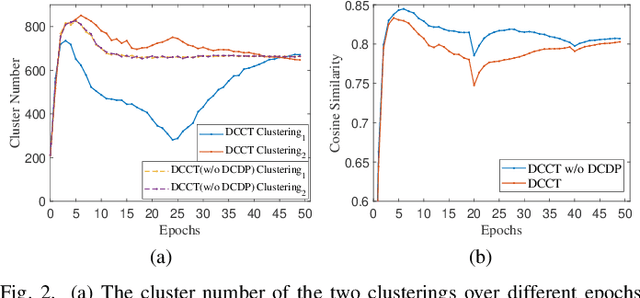
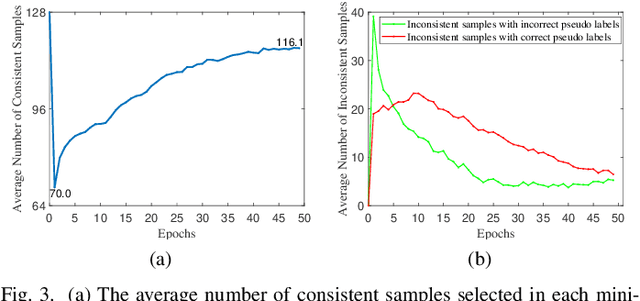

In unsupervised person Re-ID, peer-teaching strategy leveraging two networks to facilitate training has been proven to be an effective method to deal with the pseudo label noise. However, training two networks with a set of noisy pseudo labels reduces the complementarity of the two networks and results in label noise accumulation. To handle this issue, this paper proposes a novel Dual Clustering Co-teaching (DCCT) approach. DCCT mainly exploits the features extracted by two networks to generate two sets of pseudo labels separately by clustering with different parameters. Each network is trained with the pseudo labels generated by its peer network, which can increase the complementarity of the two networks to reduce the impact of noises. Furthermore, we propose dual clustering with dynamic parameters (DCDP) to make the network adaptive and robust to dynamically changing clustering parameters. Moreover, Consistent Sample Mining (CSM) is proposed to find the samples with unchanged pseudo labels during training for potential noisy sample removal. Extensive experiments demonstrate the effectiveness of the proposed method, which outperforms the state-of-the-art unsupervised person Re-ID methods by a considerable margin and surpasses most methods utilizing camera information.
GeneAnnotator: A Semi-automatic Annotation Tool for Visual Scene Graph
Sep 06, 2021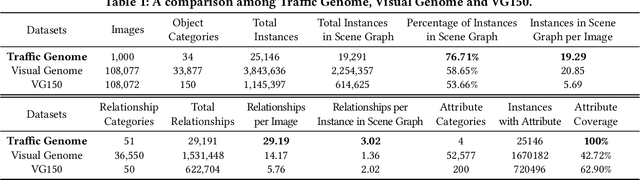
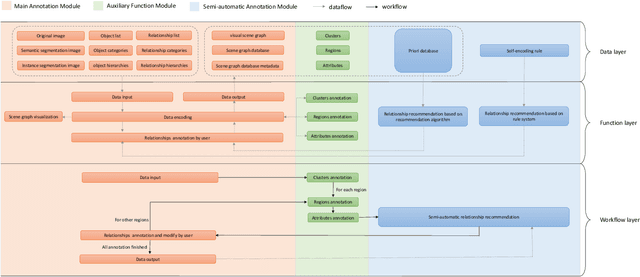
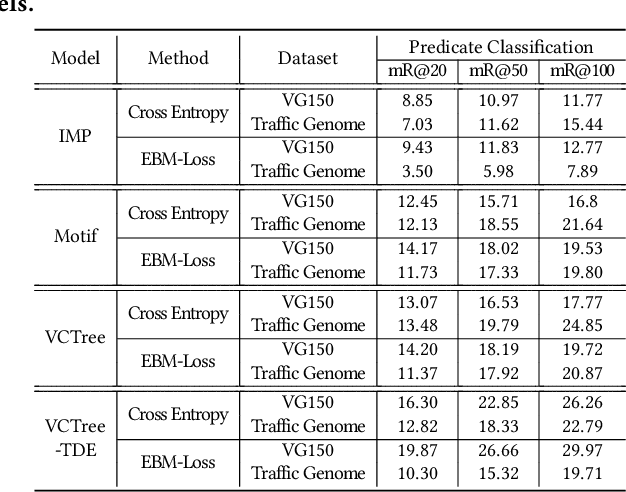
In this manuscript, we introduce a semi-automatic scene graph annotation tool for images, the GeneAnnotator. This software allows human annotators to describe the existing relationships between participators in the visual scene in the form of directed graphs, hence enabling the learning and reasoning on visual relationships, e.g., image captioning, VQA and scene graph generation, etc. The annotations for certain image datasets could either be merged in a single VG150 data-format file to support most existing models for scene graph learning or transformed into a separated annotation file for each single image to build customized datasets. Moreover, GeneAnnotator provides a rule-based relationship recommending algorithm to reduce the heavy annotation workload. With GeneAnnotator, we propose Traffic Genome, a comprehensive scene graph dataset with 1000 diverse traffic images, which in return validates the effectiveness of the proposed software for scene graph annotation. The project source code, with usage examples and sample data is available at https://github.com/Milomilo0320/A-Semi-automatic-Annotation-Software-for-Scene-Graph, under the Apache open-source license.
Unified Regularity Measures for Sample-wise Learning and Generalization
Aug 09, 2021

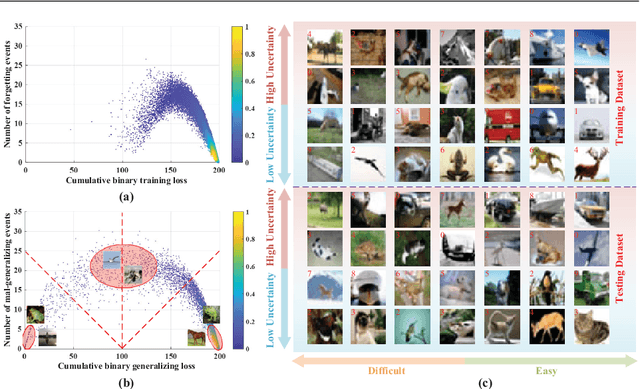
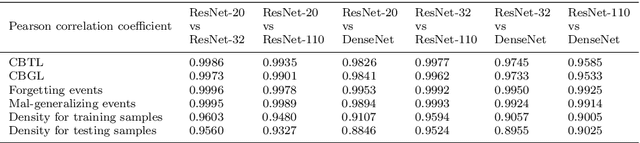
Fundamental machine learning theory shows that different samples contribute unequally both in learning and testing processes. Contemporary studies on DNN imply that such sample di?erence is rooted on the distribution of intrinsic pattern information, namely sample regularity. Motivated by the recent discovery on network memorization and generalization, we proposed a pair of sample regularity measures for both processes with a formulation-consistent representation. Specifically, cumulative binary training/generalizing loss (CBTL/CBGL), the cumulative number of correct classi?cations of the training/testing sample within training stage, is proposed to quantize the stability in memorization-generalization process; while forgetting/mal-generalizing events, i.e., the mis-classification of previously learned or generalized sample, are utilized to represent the uncertainty of sample regularity with respect to optimization dynamics. Experiments validated the effectiveness and robustness of the proposed approaches for mini-batch SGD optimization. Further applications on training/testing sample selection show the proposed measures sharing the uni?ed computing procedure could benefit for both tasks.
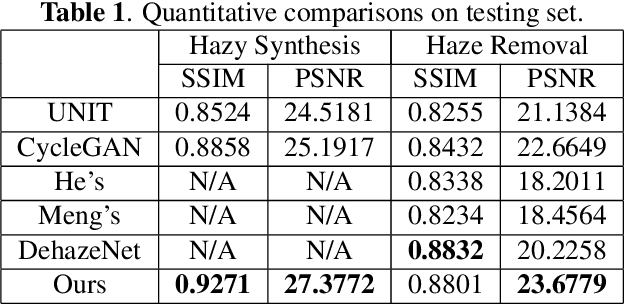
Level-aware Haze Image Synthesis by Self-Supervised Content-Style Disentanglement
Mar 11, 2021
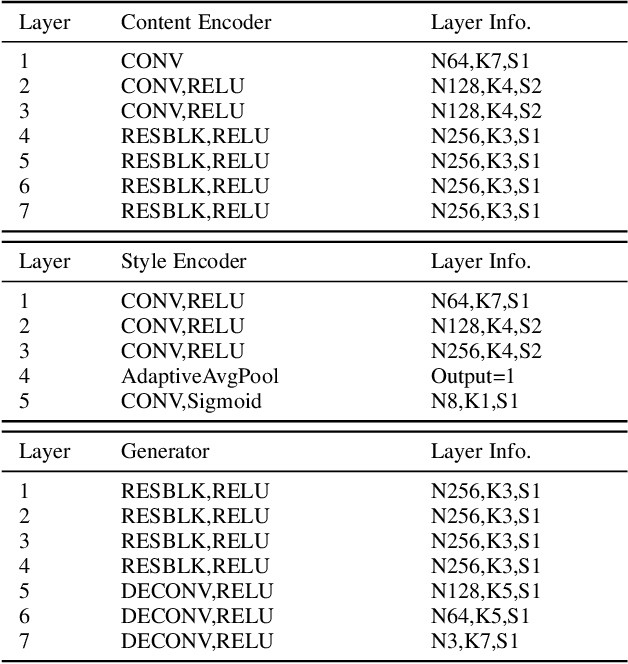
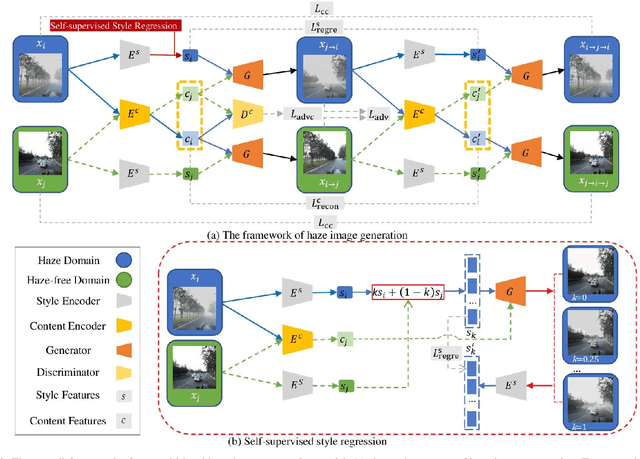
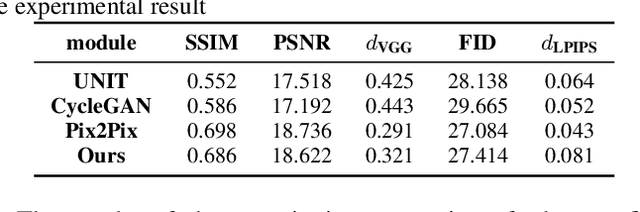
The key procedure of haze image translation through adversarial training lies in the disentanglement between the feature only involved in haze synthesis, i.e.style feature, and the feature representing the invariant semantic content, i.e. content feature. Previous methods separate content feature apart by utilizing it to classify haze image during the training process. However, in this paper we recognize the incompleteness of the content-style disentanglement in such technical routine. The flawed style feature entangled with content information inevitably leads the ill-rendering of the haze images. To address, we propose a self-supervised style regression via stochastic linear interpolation to reduce the content information in style feature. The ablative experiments demonstrate the disentangling completeness and its superiority in level-aware haze image synthesis. Moreover, the generated haze data are applied in the testing generalization of vehicle detectors. Further study between haze-level and detection performance shows that haze has obvious impact on the generalization of the vehicle detectors and such performance degrading level is linearly correlated to the haze-level, which, in turn, validates the effectiveness of the proposed method.
PyRetri: A PyTorch-based Library for Unsupervised Image Retrieval by Deep Convolutional Neural Networks
May 02, 2020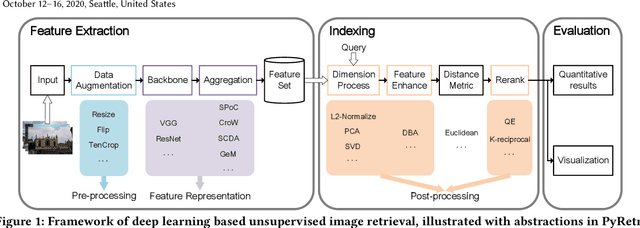
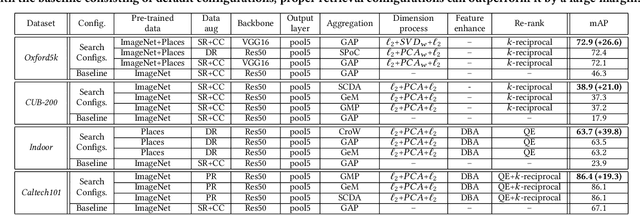

Despite significant progress of applying deep learning methods to the field of content-based image retrieval, there has not been a software library that covers these methods in a unified manner. In order to fill this gap, we introduce PyRetri, an open source library for deep learning based unsupervised image retrieval. The library encapsulates the retrieval process in several stages and provides functionality that covers various prominent methods for each stage. The idea underlying its design is to provide a unified platform for deep learning based image retrieval research, with high usability and extensibility. To the best of our knowledge, this is the first open-source library for unsupervised image retrieval by deep learning.
Bimodal Stereo: Joint Shape and Pose Estimation from Color-Depth Image Pair
May 16, 2019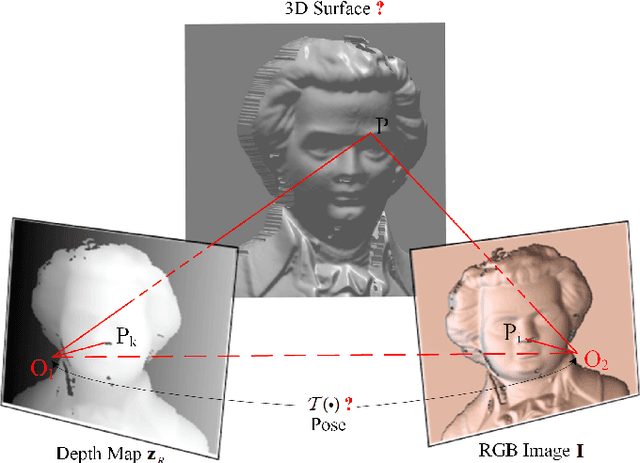
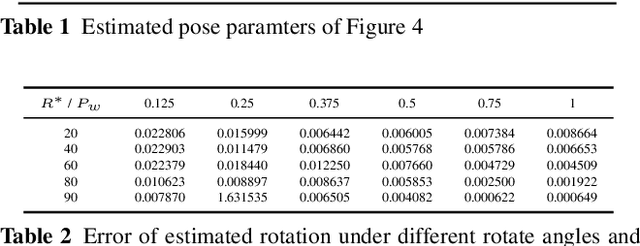
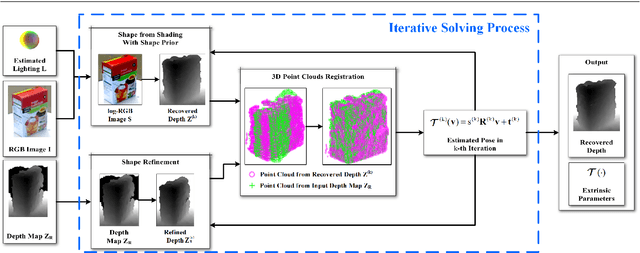
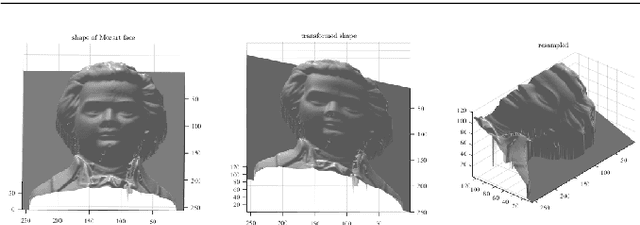
Mutual calibration between color and depth cameras is a challenging topic in multi-modal data registration. In this paper, we are confronted with a "Bimodal Stereo" problem, which aims to solve camera pose from a pair of an uncalibrated color image and a depth map from different views automatically. To address this problem, an iterative Shape-from-Shading (SfS) based framework is proposed to estimate shape and pose simultaneously. In the pipeline, the estimated shape is refined by the shape prior from the given depth map under the estimated pose. Meanwhile, the estimated pose is improved by the registration of estimated shape and shape from given depth map. We also introduce a shading based refinement in the pipeline to address noisy depth map with holes. Extensive experiments showed that through our method, both the depth map, the recovered shape as well as its pose can be desirably refined and recovered.
Joint haze image synthesis and dehazing with mmd-vae losses
May 15, 2019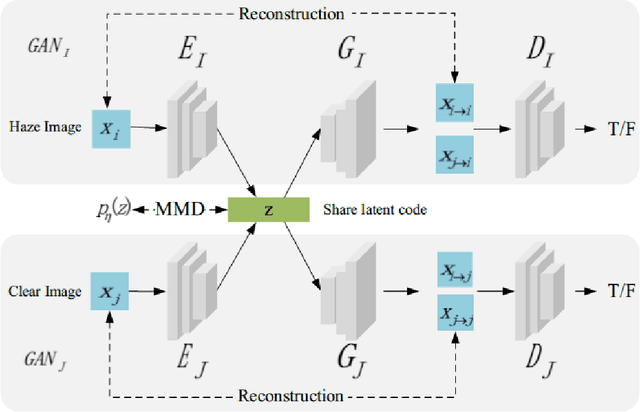


Fog and haze are weathers with low visibility which are adversarial to the driving safety of intelligent vehicles equipped with optical sensors like cameras and LiDARs. Therefore image dehazing for perception enhancement and haze image synthesis for testing perception abilities are equivalently important in the development of such autonomous driving systems. From the view of image translation, these two problems are essentially dual with each other, which have the potentiality to be solved jointly. In this paper, we propose an unsupervised Image-to-Image Translation framework based on Variational Autoencoders (VAE) and Generative Adversarial Nets (GAN) to handle haze image synthesis and haze removal simultaneously. Since the KL divergence in the VAE objectives could not guarantee the optimal mapping under imbalanced and unpaired training samples with limited size, Maximum mean discrepancy (MMD) based VAE is utilized to ensure the translating consistency in both directions. The comprehensive analysis on both synthesis and dehazing performance of our method demonstrate the feasibility and practicability of the proposed method.
Spatio-Temporal Road Scene Reconstruction using Superpixel MRF
Nov 27, 2018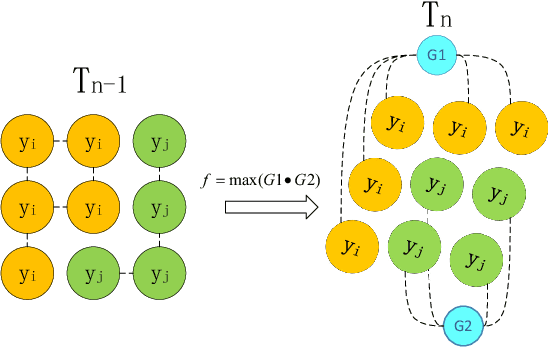
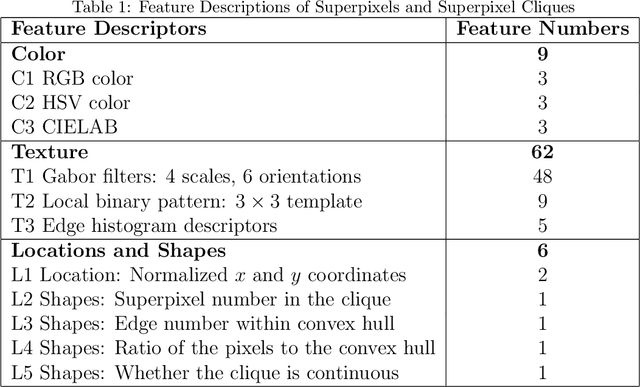
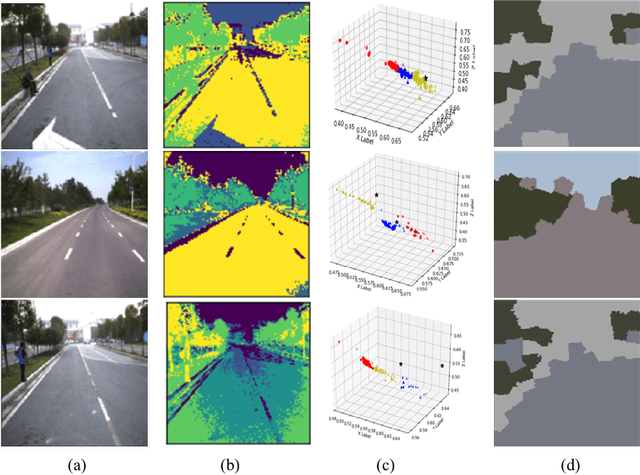

Scene models construction based on image rendering is a hot topic in the computer vision community. In this paper, we propose a framework to construct road scene models based on 3D corridor structures. The construction of scene models consists of two successive stages: road detection and scene construction. The road detection is implemented via a new superpixel Markov random field (MRF) algorithm. The data fidelity term of the energy function is jointly computed using the superpixel features of color, texture and location. The smoothness term is defined by the interaction of spatio-temporally adjacent superpixels. The control points of road boundaries are generated with the constraint of vanishing point. Subsequently, the road scene models are constructed, where the foreground and background regions are modeled independently. Numerous applications are developed based on the proposed framework, e.g., traffic scenes simulation. The experiments and comparisons are conducted for both the road detection and scene construction stages, which prove the effectiveness of the proposed method.