 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLevel-aware Haze Image Synthesis by Self-Supervised Content-Style Disentanglement
Mar 11, 2021
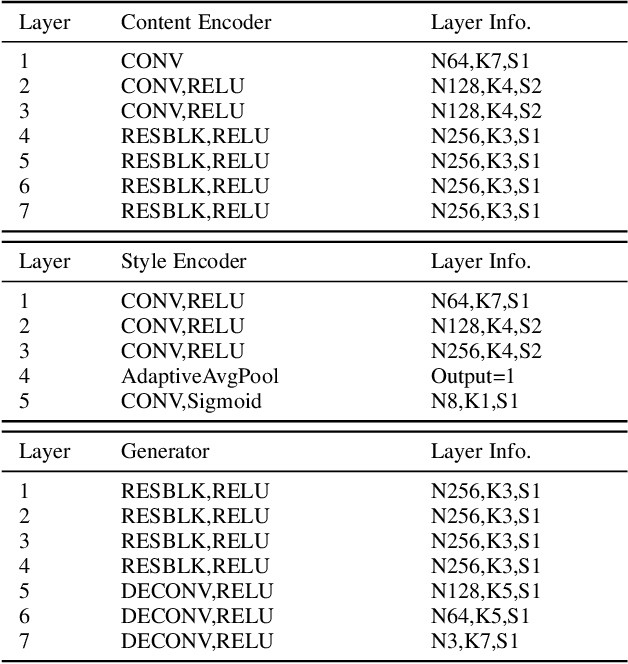
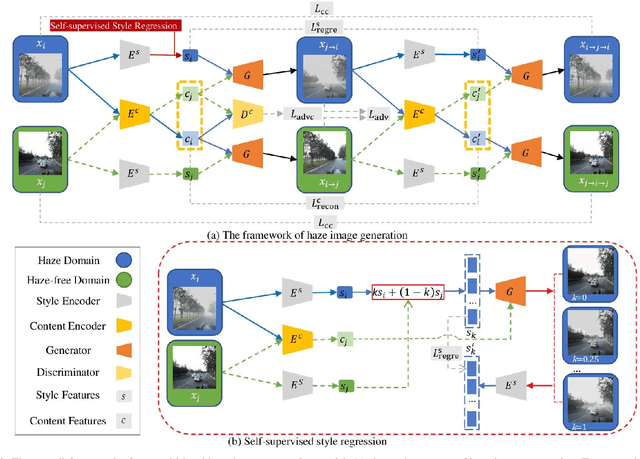
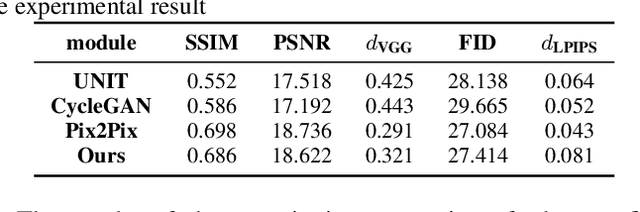
The key procedure of haze image translation through adversarial training lies in the disentanglement between the feature only involved in haze synthesis, i.e.style feature, and the feature representing the invariant semantic content, i.e. content feature. Previous methods separate content feature apart by utilizing it to classify haze image during the training process. However, in this paper we recognize the incompleteness of the content-style disentanglement in such technical routine. The flawed style feature entangled with content information inevitably leads the ill-rendering of the haze images. To address, we propose a self-supervised style regression via stochastic linear interpolation to reduce the content information in style feature. The ablative experiments demonstrate the disentangling completeness and its superiority in level-aware haze image synthesis. Moreover, the generated haze data are applied in the testing generalization of vehicle detectors. Further study between haze-level and detection performance shows that haze has obvious impact on the generalization of the vehicle detectors and such performance degrading level is linearly correlated to the haze-level, which, in turn, validates the effectiveness of the proposed method.
How to Generate a Good Word Embedding?
Jul 20, 2015
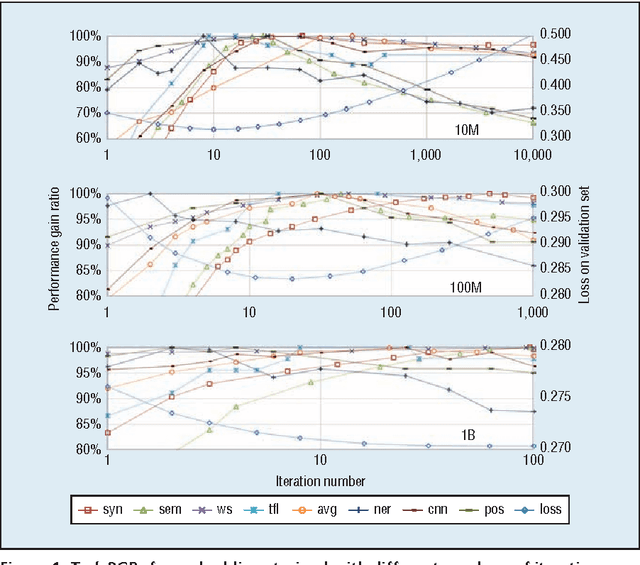

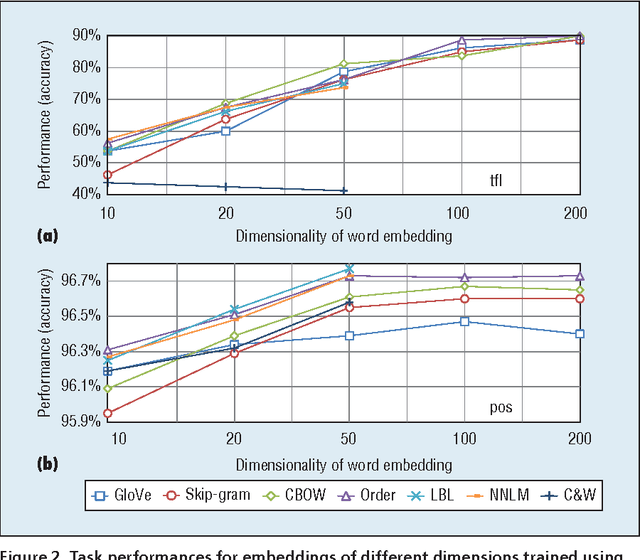
We analyze three critical components of word embedding training: the model, the corpus, and the training parameters. We systematize existing neural-network-based word embedding algorithms and compare them using the same corpus. We evaluate each word embedding in three ways: analyzing its semantic properties, using it as a feature for supervised tasks and using it to initialize neural networks. We also provide several simple guidelines for training word embeddings. First, we discover that corpus domain is more important than corpus size. We recommend choosing a corpus in a suitable domain for the desired task, after that, using a larger corpus yields better results. Second, we find that faster models provide sufficient performance in most cases, and more complex models can be used if the training corpus is sufficiently large. Third, the early stopping metric for iterating should rely on the development set of the desired task rather than the validation loss of training embedding.