 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWord and Document Embeddings based on Neural Network Approaches
Nov 18, 2016Data representation is a fundamental task in machine learning. The representation of data affects the performance of the whole machine learning system. In a long history, the representation of data is done by feature engineering, and researchers aim at designing better features for specific tasks. Recently, the rapid development of deep learning and representation learning has brought new inspiration to various domains. In natural language processing, the most widely used feature representation is the Bag-of-Words model. This model has the data sparsity problem and cannot keep the word order information. Other features such as part-of-speech tagging or more complex syntax features can only fit for specific tasks in most cases. This thesis focuses on word representation and document representation. We compare the existing systems and present our new model. First, for generating word embeddings, we make comprehensive comparisons among existing word embedding models. In terms of theory, we figure out the relationship between the two most important models, i.e., Skip-gram and GloVe. In our experiments, we analyze three key points in generating word embeddings, including the model construction, the training corpus and parameter design. We evaluate word embeddings with three types of tasks, and we argue that they cover the existing use of word embeddings. Through theory and practical experiments, we present some guidelines for how to generate a good word embedding. Second, in Chinese character or word representation. We introduce the joint training of Chinese character and word. ... Third, for document representation, we analyze the existing document representation models, including recursive NNs, recurrent NNs and convolutional NNs. We point out the drawbacks of these models and present our new model, the recurrent convolutional neural networks. ...
How to Generate a Good Word Embedding?
Jul 20, 2015
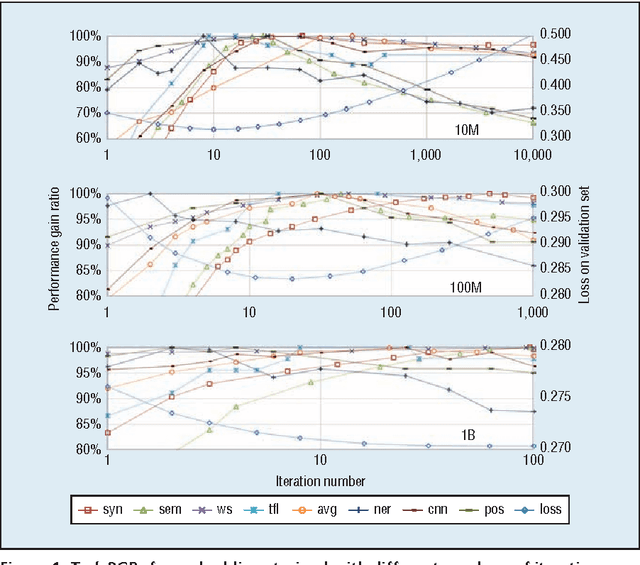

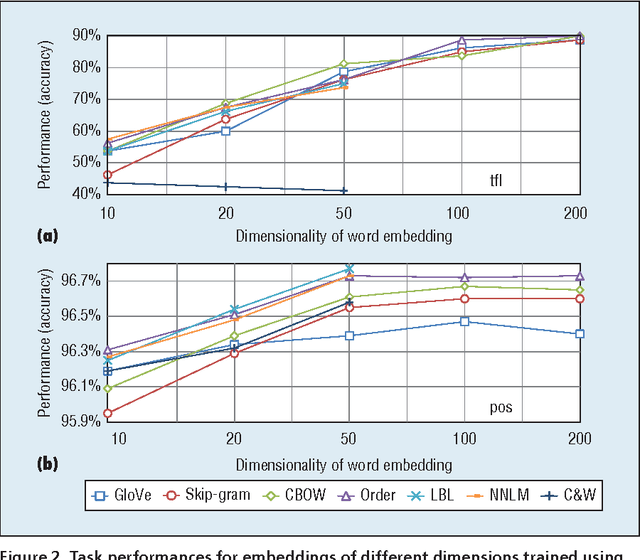
We analyze three critical components of word embedding training: the model, the corpus, and the training parameters. We systematize existing neural-network-based word embedding algorithms and compare them using the same corpus. We evaluate each word embedding in three ways: analyzing its semantic properties, using it as a feature for supervised tasks and using it to initialize neural networks. We also provide several simple guidelines for training word embeddings. First, we discover that corpus domain is more important than corpus size. We recommend choosing a corpus in a suitable domain for the desired task, after that, using a larger corpus yields better results. Second, we find that faster models provide sufficient performance in most cases, and more complex models can be used if the training corpus is sufficiently large. Third, the early stopping metric for iterating should rely on the development set of the desired task rather than the validation loss of training embedding.