 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePangu-ACE: Adaptive Cascaded Experts for Educational Response Generation on EduBench
Apr 16, 2026Educational assistants should spend more computation only when the task needs it. This paper rewrites our earlier draft around the system that was actually implemented and archived in the repository: a sample-level 1B to 7B cascade for the shared-8 EduBench benchmark. The final system, Pangu-ACE, uses a 1B tutor-router to produce a draft answer plus routing signals, then either accepts the draft or escalates the sample to a 7B specialist prompt. We also correct a major offline evaluation bug: earlier summaries over-credited some open-form outputs that only satisfied superficial format checks. After CPU-side rescoring from saved prediction JSONL, the full Chinese test archive (7013 samples) shows that cascade_final improves deterministic quality from 0.457 to 0.538 and format validity from 0.707 to 0.866 over the legacy rule_v2 system while accepting 19.7% of requests directly at 1B. Routing is strongly task dependent: IP is accepted by 1B 78.0% of the time, while QG and EC still escalate almost always. The current archived deployment does not yet show latency gains, so the defensible efficiency story is routing selectivity rather than wall-clock speedup. We also package a reproducible artifact-first paper workflow and clarify the remaining external-baseline gap: GPT-5.4 re-judging is implemented locally, but the configured provider endpoint and key are invalid, so final sampled-baseline alignment with GPT-5.4 remains pending infrastructure repair.
Spintronic Bayesian Hardware Driven by Stochastic Magnetic Domain Wall Dynamics
Jul 23, 2025As artificial intelligence (AI) advances into diverse applications, ensuring reliability of AI models is increasingly critical. Conventional neural networks offer strong predictive capabilities but produce deterministic outputs without inherent uncertainty estimation, limiting their reliability in safety-critical domains. Probabilistic neural networks (PNNs), which introduce randomness, have emerged as a powerful approach for enabling intrinsic uncertainty quantification. However, traditional CMOS architectures are inherently designed for deterministic operation and actively suppress intrinsic randomness. This poses a fundamental challenge for implementing PNNs, as probabilistic processing introduces significant computational overhead. To address this challenge, we introduce a Magnetic Probabilistic Computing (MPC) platform-an energy-efficient, scalable hardware accelerator that leverages intrinsic magnetic stochasticity for uncertainty-aware computing. This physics-driven strategy utilizes spintronic systems based on magnetic domain walls (DWs) and their dynamics to establish a new paradigm of physical probabilistic computing for AI. The MPC platform integrates three key mechanisms: thermally induced DW stochasticity, voltage controlled magnetic anisotropy (VCMA), and tunneling magnetoresistance (TMR), enabling fully electrical and tunable probabilistic functionality at the device level. As a representative demonstration, we implement a Bayesian Neural Network (BNN) inference structure and validate its functionality on CIFAR-10 classification tasks. Compared to standard 28nm CMOS implementations, our approach achieves a seven orders of magnitude improvement in the overall figure of merit, with substantial gains in area efficiency, energy consumption, and speed. These results underscore the MPC platform's potential to enable reliable and trustworthy physical AI systems.
SiamPolar: Semi-supervised Realtime Video Object Segmentation with Polar Representation
Oct 27, 2021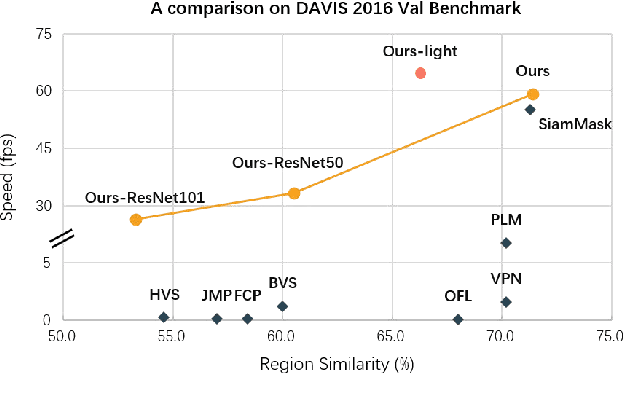
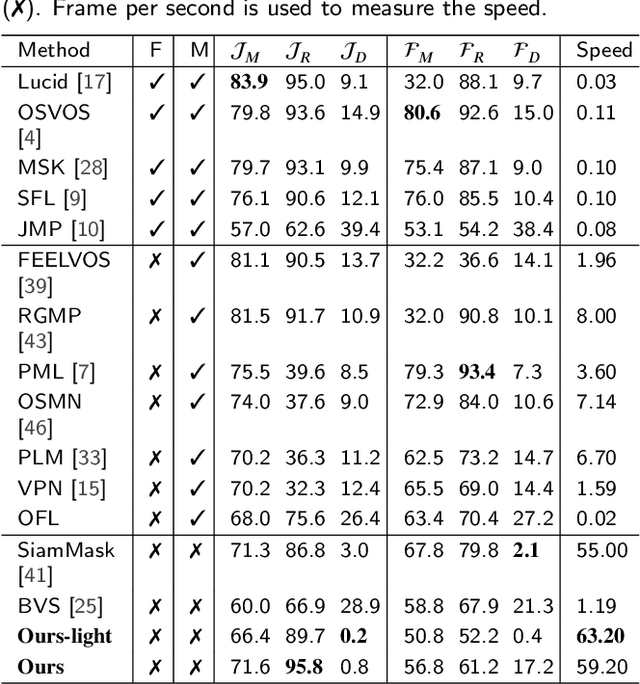
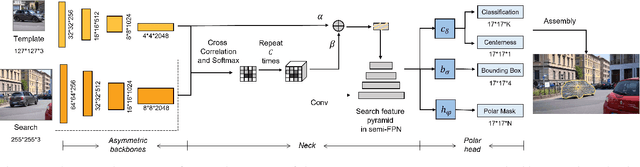
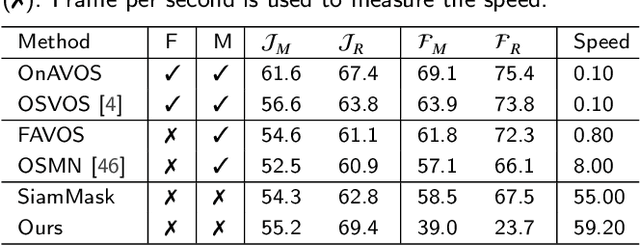
Video object segmentation (VOS) is an essential part of autonomous vehicle navigation. The real-time speed is very important for the autonomous vehicle algorithms along with the accuracy metric. In this paper, we propose a semi-supervised real-time method based on the Siamese network using a new polar representation. The input of bounding boxes is initialized rather than the object masks, which are applied to the video object detection tasks. The polar representation could reduce the parameters for encoding masks with subtle accuracy loss so that the algorithm speed can be improved significantly. An asymmetric siamese network is also developed to extract the features from different spatial scales. Moreover, the peeling convolution is proposed to reduce the antagonism among the branches of the polar head. The repeated cross-correlation and semi-FPN are designed based on this idea. The experimental results on the DAVIS-2016 dataset and other public datasets demonstrate the effectiveness of the proposed method.
* 11 pages, 11 figures, journal
Effective multi-view registration of point sets based on student's t mixture model
Dec 13, 2020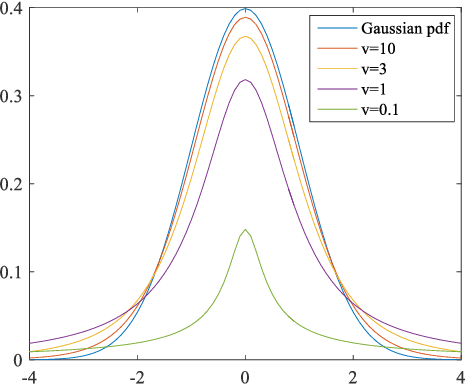
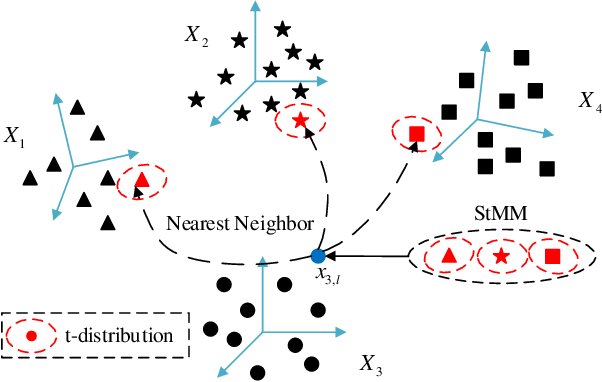


Recently, Expectation-maximization (EM) algorithm has been introduced as an effective means to solve multi-view registration problem. Most of the previous methods assume that each data point is drawn from the Gaussian Mixture Model (GMM), which is difficult to deal with the noise with heavy-tail or outliers. Accordingly, this paper proposed an effective registration method based on Student's t Mixture Model (StMM). More specially, we assume that each data point is drawn from one unique StMM, where its nearest neighbors (NNs) in other point sets are regarded as the t-distribution centroids with equal covariances, membership probabilities, and fixed degrees of freedom. Based on this assumption, the multi-view registration problem is formulated into the maximization of the likelihood function including all rigid transformations. Subsequently, the EM algorithm is utilized to optimize rigid transformations as well as the only t-distribution covariance for multi-view registration. Since only a few model parameters require to be optimized, the proposed method is more likely to obtain the desired registration results. Besides, all t-distribution centroids can be obtained by the NN search method, it is very efficient to achieve multi-view registration. What's more, the t-distribution takes the noise with heavy-tail into consideration, which makes the proposed method be inherently robust to noises and outliers. Experimental results tested on benchmark data sets illustrate its superior performance on robustness and accuracy over state-of-the-art methods.
Visual Space Optimization for Zero-shot Learning
Jun 30, 2019

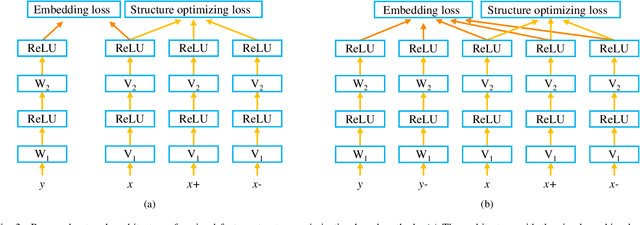
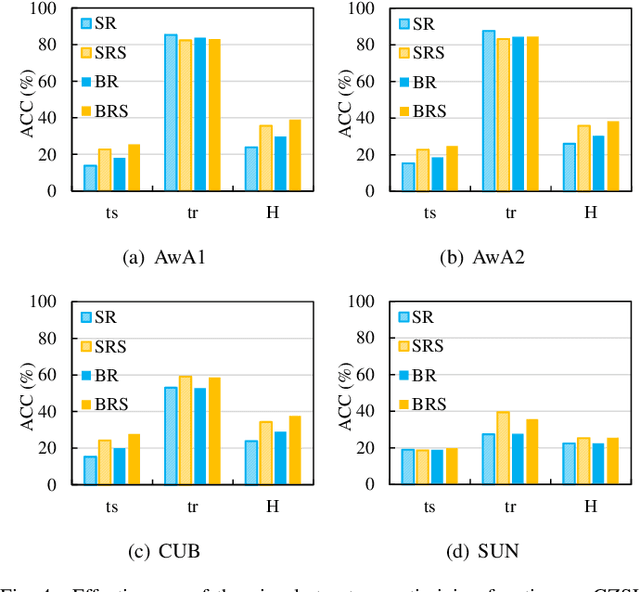
Zero-shot learning, which aims to recognize new categories that are not included in the training set, has gained popularity owing to its potential ability in the real-word applications. Zero-shot learning models rely on learning an embedding space, where both semantic descriptions of classes and visual features of instances can be embedded for nearest neighbor search. Recently, most of the existing works consider the visual space formulated by deep visual features as an ideal choice of the embedding space. However, the discrete distribution of instances in the visual space makes the data structure unremarkable. We argue that optimizing the visual space is crucial as it allows semantic vectors to be embedded into the visual space more effectively. In this work, we propose two strategies to accomplish this purpose. One is the visual prototype based method, which learns a visual prototype for each visual class, so that, in the visual space, a class can be represented by a prototype feature instead of a series of discrete visual features. The other is to optimize the visual feature structure in an intermediate embedding space, and in this method we successfully devise a multilayer perceptron framework based algorithm that is able to learn the common intermediate embedding space and meanwhile to make the visual data structure more distinctive. Through extensive experimental evaluation on four benchmark datasets, we demonstrate that optimizing visual space is beneficial for zero-shot learning. Besides, the proposed prototype based method achieves the new state-of-the-art performance.
Spatio-Temporal Road Scene Reconstruction using Superpixel MRF
Nov 27, 2018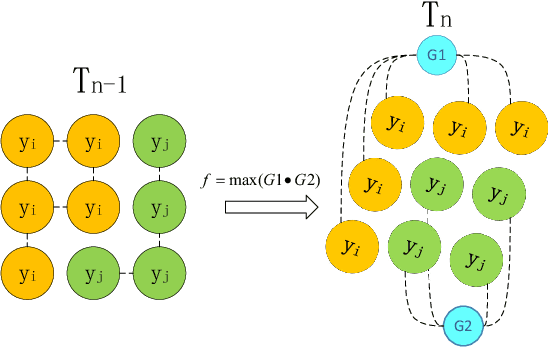
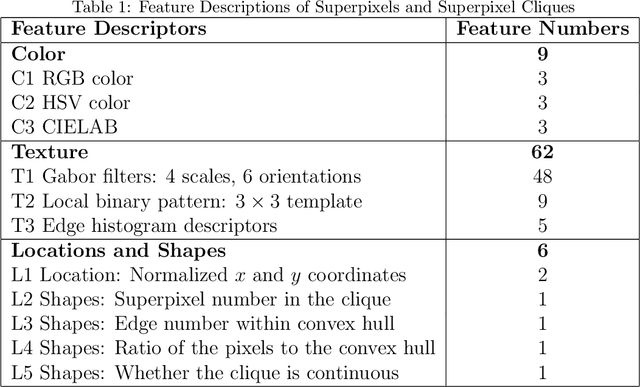
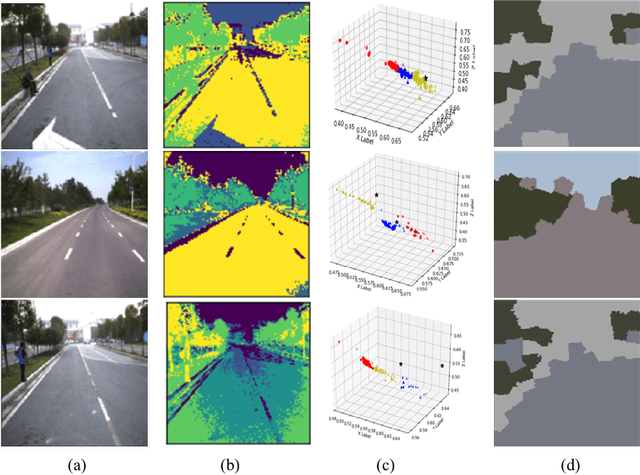

Scene models construction based on image rendering is a hot topic in the computer vision community. In this paper, we propose a framework to construct road scene models based on 3D corridor structures. The construction of scene models consists of two successive stages: road detection and scene construction. The road detection is implemented via a new superpixel Markov random field (MRF) algorithm. The data fidelity term of the energy function is jointly computed using the superpixel features of color, texture and location. The smoothness term is defined by the interaction of spatio-temporally adjacent superpixels. The control points of road boundaries are generated with the constraint of vanishing point. Subsequently, the road scene models are constructed, where the foreground and background regions are modeled independently. Numerous applications are developed based on the proposed framework, e.g., traffic scenes simulation. The experiments and comparisons are conducted for both the road detection and scene construction stages, which prove the effectiveness of the proposed method.
Multi-view Point Cloud Registration with Adaptive Convergence Threshold and its Application on 3D Model Retrieval
Nov 25, 2018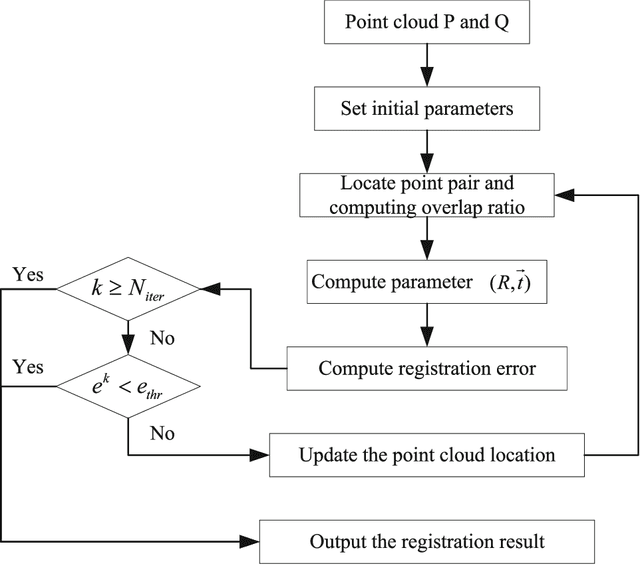
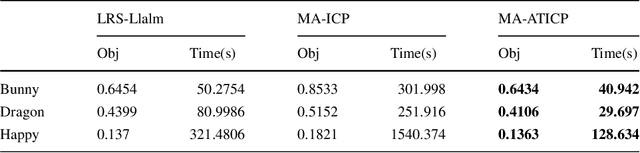

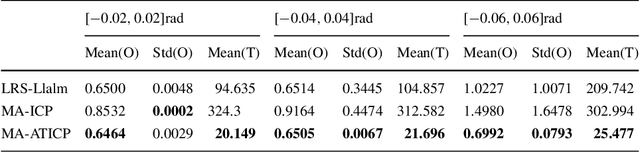
Multi-view point cloud registration is a hot topic in the communities of multimedia technology and artificial intelligence (AI). In this paper, we propose a framework to reconstruct the 3D models by the multi-view point cloud registration algorithm with adaptive convergence threshold, and subsequently apply it to 3D model retrieval. The iterative closest point (ICP) algorithm is implemented combining with the motion average algorithm for the registration of multi-view point clouds. After the registration process, we design applications for 3D model retrieval. The geometric saliency map is computed based on the vertex curvature. The test facial triangle is then generated based on the saliency map, which is applied to compare with the standard facial triangle. The face and non-face models are then discriminated. The experiments and comparisons prove the effectiveness of the proposed framework.
K-means clustering for efficient and robust registration of multi-view point sets
Apr 30, 2018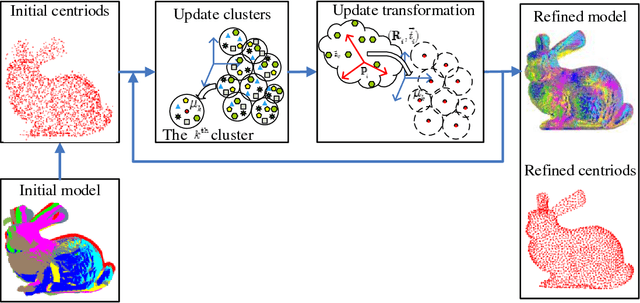
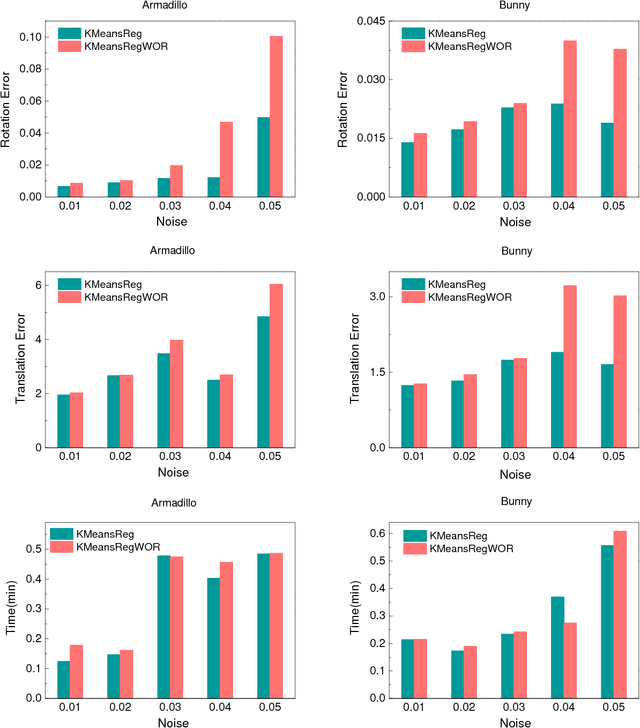
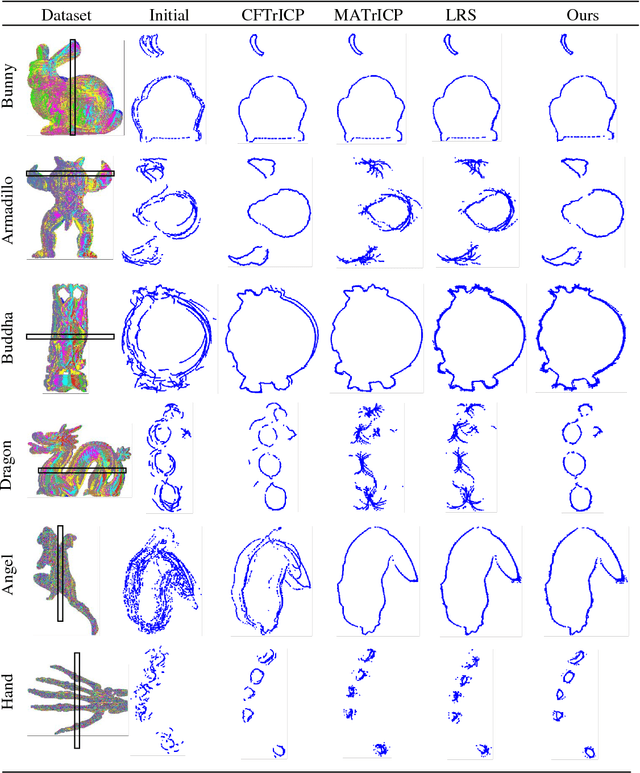
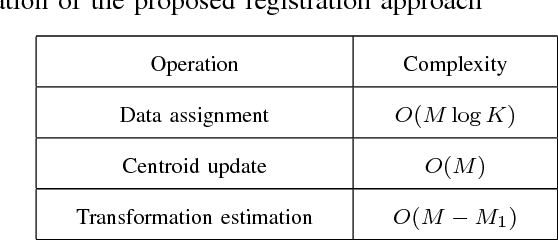
Generally, there are three main factors that determine the practical usability of registration, i.e., accuracy, robustness, and efficiency. In real-time applications, efficiency and robustness are more important. To promote these two abilities, we cast the multi-view registration into a clustering task. All the centroids are uniformly sampled from the initially aligned point sets involved in the multi-view registration, which makes it rather efficient and effective for the clustering. Then, each point is assigned to a single cluster and each cluster centroid is updated accordingly. Subsequently, the shape comprised by all cluster centroids is used to sequentially estimate the rigid transformation for each point set. For accuracy and stability, clustering and transformation estimation are alternately and iteratively applied to all point sets. We tested our proposed approach on several benchmark datasets and compared it with state-of-the-art approaches. Experimental results validate its efficiency and robustness for the registration of multi-view point sets.
Multi-view Registration Based on Weighted Low Rank and Sparse Matrix Decomposition of Motions
Apr 05, 2018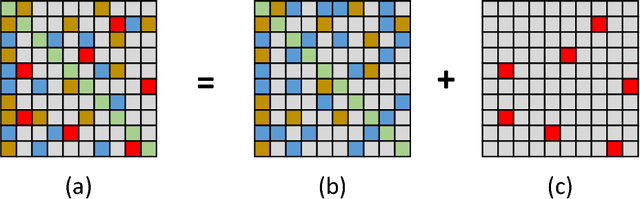
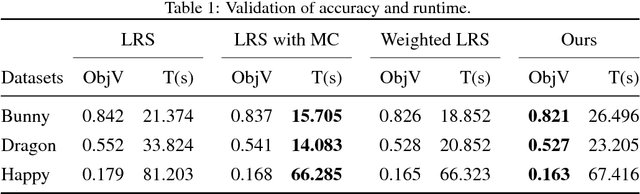


Recently, the low rank and sparse (LRS) matrix decomposition has been introduced as an effective mean to solve the multi-view registration. It views each available relative motion as a block element to reconstruct one matrix so as to approximate the low rank matrix, where global motions can be recovered for multi-view registration. However, this approach is sensitive to the sparsity of the reconstructed matrix and it treats all block elements equally in spite of their varied reliability. Therefore, this paper proposes an effective approach for multi-view registration by the weighted LRS decomposition. Based on the anti-symmetry property of relative motions, it firstly proposes a completion strategy to reduce the sparsity of the reconstructed matrix. The reduced sparsity of reconstructed matrix can improve the robustness of LRS decomposition. Then, it proposes the weighted LRS decomposition, where each block element is assigned with one estimated weight to denote its reliability. By introducing the weight, more accurate registration results can be recovered from the estimated low rank matrix with good efficiency. Experimental results tested on public data sets illustrate the superiority of the proposed approach over the state-of-the-art approaches on robustness, accuracy, and efficiency.
Adaptive Co-weighting Deep Convolutional Features For Object Retrieval
Mar 20, 2018


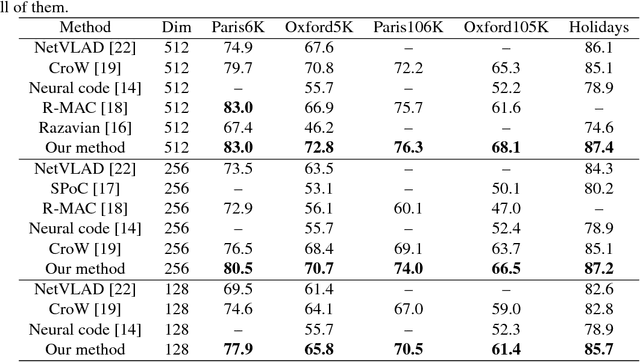
Aggregating deep convolutional features into a global image vector has attracted sustained attention in image retrieval. In this paper, we propose an efficient unsupervised aggregation method that uses an adaptive Gaussian filter and an elementvalue sensitive vector to co-weight deep features. Specifically, the Gaussian filter assigns large weights to features of region-of-interests (RoI) by adaptively determining the RoI's center, while the element-value sensitive channel vector suppresses burstiness phenomenon by assigning small weights to feature maps with large sum values of all locations. Experimental results on benchmark datasets validate the proposed two weighting schemes both effectively improve the discrimination power of image vectors. Furthermore, with the same experimental setting, our method outperforms other very recent aggregation approaches by a considerable margin.