 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEntropy Induced Pruning Framework for Convolutional Neural Networks
Aug 13, 2022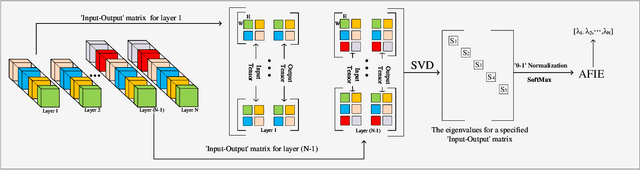
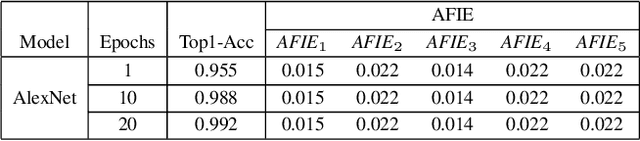
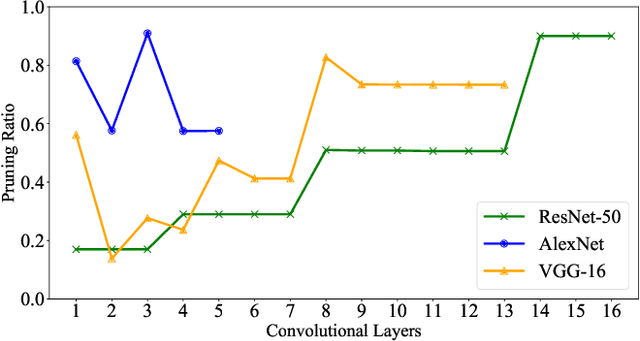

Structured pruning techniques have achieved great compression performance on convolutional neural networks for image classification task. However, the majority of existing methods are weight-oriented, and their pruning results may be unsatisfactory when the original model is trained poorly. That is, a fully-trained model is required to provide useful weight information. This may be time-consuming, and the pruning results are sensitive to the updating process of model parameters. In this paper, we propose a metric named Average Filter Information Entropy (AFIE) to measure the importance of each filter. It is calculated by three major steps, i.e., low-rank decomposition of the "input-output" matrix of each convolutional layer, normalization of the obtained eigenvalues, and calculation of filter importance based on information entropy. By leveraging the proposed AFIE, the proposed framework is able to yield a stable importance evaluation of each filter no matter whether the original model is trained fully. We implement our AFIE based on AlexNet, VGG-16, and ResNet-50, and test them on MNIST, CIFAR-10, and ImageNet, respectively. The experimental results are encouraging. We surprisingly observe that for our methods, even when the original model is only trained with one epoch, the importance evaluation of each filter keeps identical to the results when the model is fully-trained. This indicates that the proposed pruning strategy can perform effectively at the beginning stage of the training process for the original model.
SBPF: Sensitiveness Based Pruning Framework For Convolutional Neural Network On Image Classification
Aug 09, 2022



Pruning techniques are used comprehensively to compress convolutional neural networks (CNNs) on image classification. However, the majority of pruning methods require a well pre-trained model to provide useful supporting parameters, such as C1-norm, BatchNorm value and gradient information, which may lead to inconsistency of filter evaluation if the parameters of the pre-trained model are not well optimized. Therefore, we propose a sensitiveness based method to evaluate the importance of each layer from the perspective of inference accuracy by adding extra damage for the original model. Because the performance of the accuracy is determined by the distribution of parameters across all layers rather than individual parameter, the sensitiveness based method will be robust to update of parameters. Namely, we can obtain similar importance evaluation of each convolutional layer between the imperfect-trained and fully trained models. For VGG-16 on CIFAR-10, even when the original model is only trained with 50 epochs, we can get same evaluation of layer importance as the results when the model is trained fully. Then we will remove filters proportional from each layer by the quantified sensitiveness. Our sensitiveness based pruning framework is verified efficiently on VGG-16, a customized Conv-4 and ResNet-18 with CIFAR-10, MNIST and CIFAR-100, respectively.
CIM-PPO:Proximal Policy Optimization with Liu-Correntropy Induced Metric
Oct 20, 2021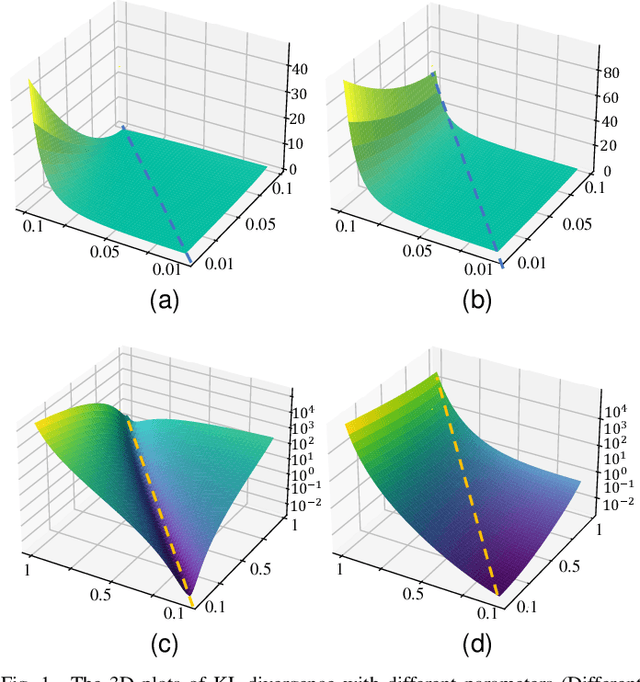
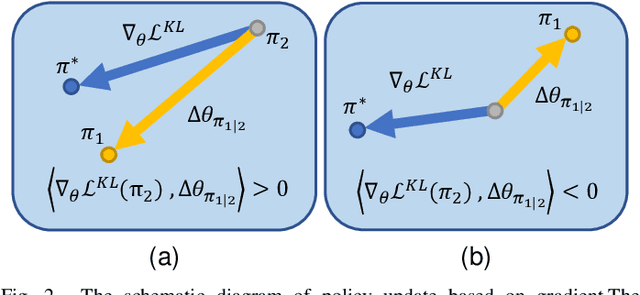
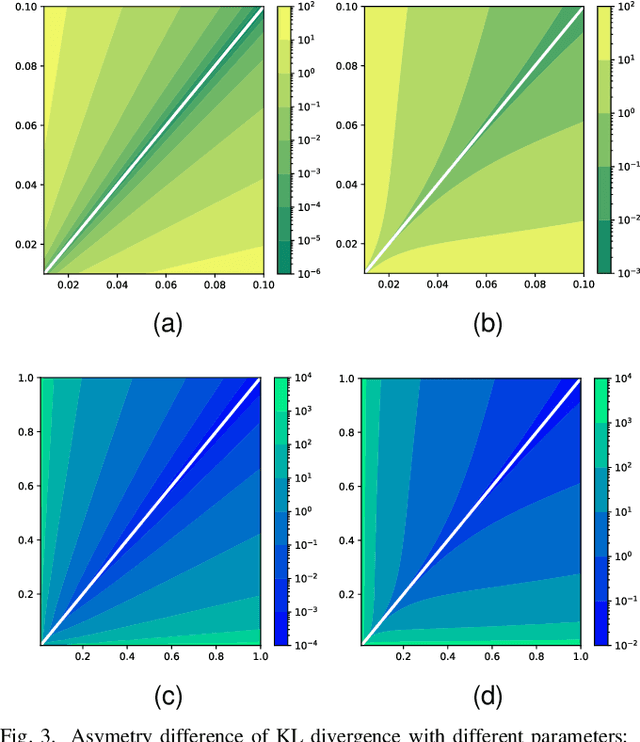
As an algorithm based on deep reinforcement learning, Proximal Policy Optimization (PPO) performs well in many complex tasks and has become one of the most popular RL algorithms in recent years. According to the mechanism of penalty in surrogate objective, PPO can be divided into PPO with KL Divergence (KL-PPO) and PPO with Clip function(Clip-PPO). Clip-PPO is widely used in a variety of practical scenarios and has attracted the attention of many researchers. Therefore, many variations have also been created, making the algorithm better and better. However, as a more theoretical algorithm, KL-PPO was neglected because its performance was not as good as CliP-PPO. In this article, we analyze the asymmetry effect of KL divergence on PPO's objective function , and give the inequality that can indicate when the asymmetry will affect the efficiency of KL-PPO. Proposed PPO with Correntropy Induced Metric algorithm(CIM-PPO) that use the theory of correntropy(a symmetry metric method that was widely used in M-estimation to evaluate two distributions' difference)and applied it in PPO. Then, we designed experiments based on OpenAIgym to test the effectiveness of the new algorithm and compare it with KL-PPO and CliP-PPO.