 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCIM-PPO:Proximal Policy Optimization with Liu-Correntropy Induced Metric
Oct 20, 2021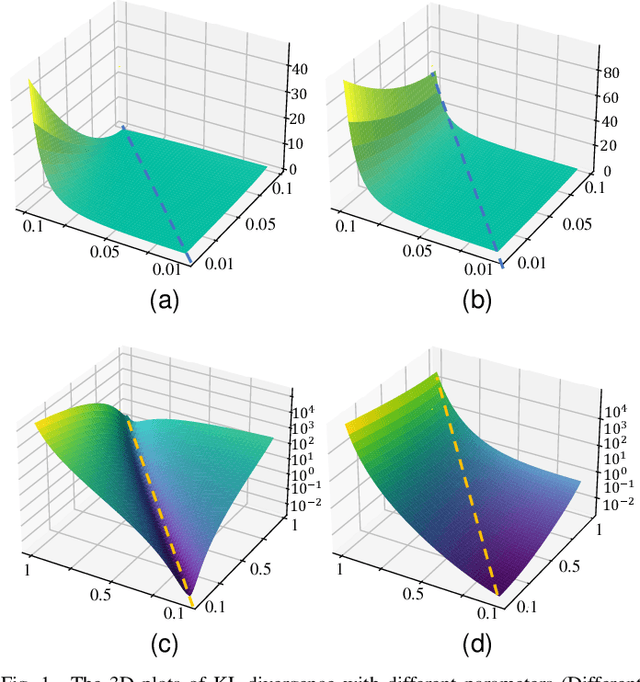
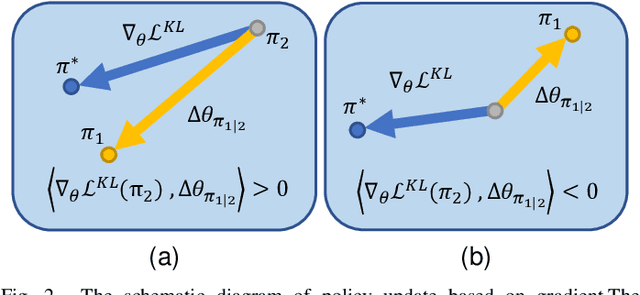
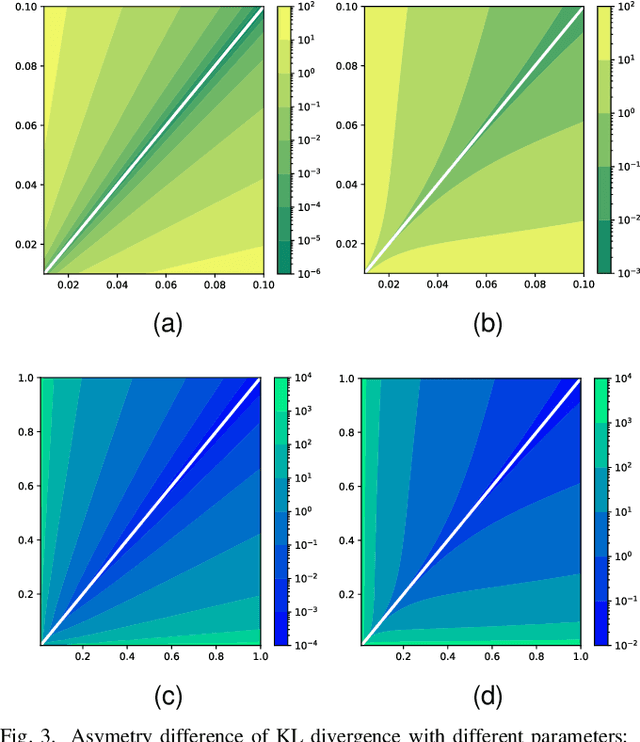
As an algorithm based on deep reinforcement learning, Proximal Policy Optimization (PPO) performs well in many complex tasks and has become one of the most popular RL algorithms in recent years. According to the mechanism of penalty in surrogate objective, PPO can be divided into PPO with KL Divergence (KL-PPO) and PPO with Clip function(Clip-PPO). Clip-PPO is widely used in a variety of practical scenarios and has attracted the attention of many researchers. Therefore, many variations have also been created, making the algorithm better and better. However, as a more theoretical algorithm, KL-PPO was neglected because its performance was not as good as CliP-PPO. In this article, we analyze the asymmetry effect of KL divergence on PPO's objective function , and give the inequality that can indicate when the asymmetry will affect the efficiency of KL-PPO. Proposed PPO with Correntropy Induced Metric algorithm(CIM-PPO) that use the theory of correntropy(a symmetry metric method that was widely used in M-estimation to evaluate two distributions' difference)and applied it in PPO. Then, we designed experiments based on OpenAIgym to test the effectiveness of the new algorithm and compare it with KL-PPO and CliP-PPO.