 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMachine-Created Universal Language for Cross-lingual Transfer
May 22, 2023There are two types of approaches to solving cross-lingual transfer: multilingual pre-training implicitly aligns the hidden representations of different languages, while the translate-test explicitly translates different languages to an intermediate language, such as English. Translate-test has better interpretability compared to multilingual pre-training. However, the translate-test has lower performance than multilingual pre-training(Conneau and Lample, 2019; Conneau et al, 2020) and can't solve word-level tasks because translation rearranges the word order. Therefore, we propose a new Machine-created Universal Language (MUL) as a new intermediate language. MUL consists of a set of discrete symbols as universal vocabulary and NL-MUL translator for translating from multiple natural languages to MUL. MUL unifies common concepts from different languages into the same universal word for better cross-language transfer. And MUL preserves the language-specific words as well as word order, so the model can be easily applied to word-level tasks. Our experiments show that translating into MUL achieves better performance compared to multilingual pre-training, and our analyses show that MUL has good interpretability.
POEM: 1-bit Point-wise Operations based on Expectation-Maximization for Efficient Point Cloud Processing
Nov 26, 2021
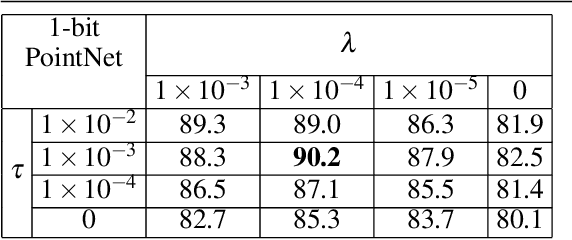


Real-time point cloud processing is fundamental for lots of computer vision tasks, while still challenged by the computational problem on resource-limited edge devices. To address this issue, we implement XNOR-Net-based binary neural networks (BNNs) for an efficient point cloud processing, but its performance is severely suffered due to two main drawbacks, Gaussian-distributed weights and non-learnable scale factor. In this paper, we introduce point-wise operations based on Expectation-Maximization (POEM) into BNNs for efficient point cloud processing. The EM algorithm can efficiently constrain weights for a robust bi-modal distribution. We lead a well-designed reconstruction loss to calculate learnable scale factors to enhance the representation capacity of 1-bit fully-connected (Bi-FC) layers. Extensive experiments demonstrate that our POEM surpasses existing the state-of-the-art binary point cloud networks by a significant margin, up to 6.7 %.
Bayesian Optimized 1-Bit CNNs
Aug 17, 2019

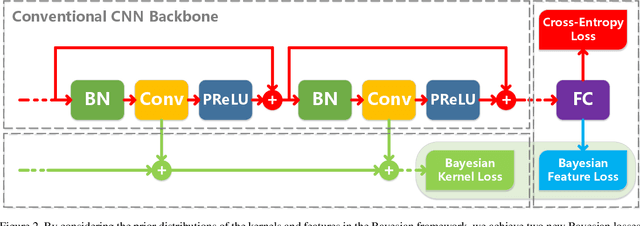

Deep convolutional neural networks (DCNNs) have dominated the recent developments in computer vision through making various record-breaking models. However, it is still a great challenge to achieve powerful DCNNs in resource-limited environments, such as on embedded devices and smart phones. Researchers have realized that 1-bit CNNs can be one feasible solution to resolve the issue; however, they are baffled by the inferior performance compared to the full-precision DCNNs. In this paper, we propose a novel approach, called Bayesian optimized 1-bit CNNs (denoted as BONNs), taking the advantage of Bayesian learning, a well-established strategy for hard problems, to significantly improve the performance of extreme 1-bit CNNs. We incorporate the prior distributions of full-precision kernels and features into the Bayesian framework to construct 1-bit CNNs in an end-to-end manner, which have not been considered in any previous related methods. The Bayesian losses are achieved with a theoretical support to optimize the network simultaneously in both continuous and discrete spaces, aggregating different losses jointly to improve the model capacity. Extensive experiments on the ImageNet and CIFAR datasets show that BONNs achieve the best classification performance compared to state-of-the-art 1-bit CNNs.