 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBalanced Data Sampling for Language Model Training with Clustering
Paper and Code
Feb 22, 2024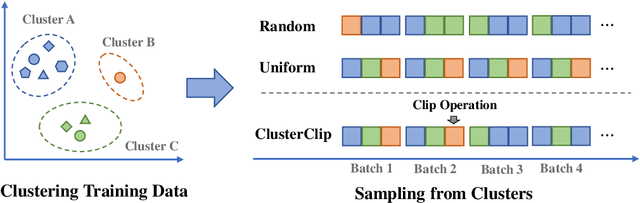
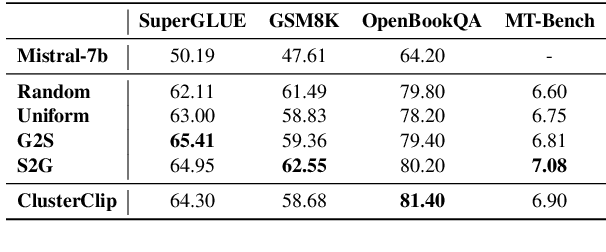
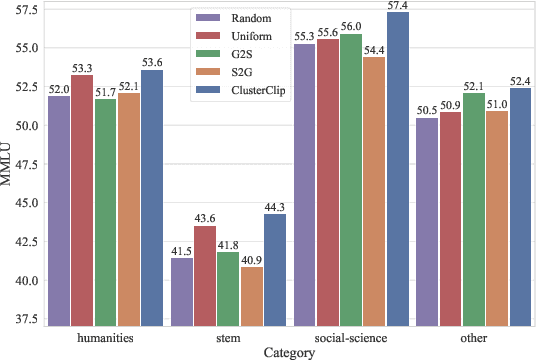
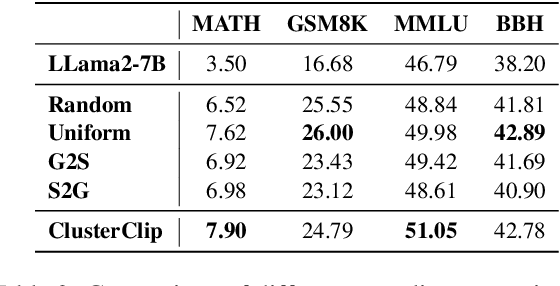
Data plays a fundamental role in the training of Large Language Models (LLMs). While attention has been paid to the collection and composition of datasets, determining the data sampling strategy in training remains an open question. Most LLMs are trained with a simple strategy, random sampling. However, this sampling strategy ignores the unbalanced nature of training data distribution, which can be sub-optimal. In this paper, we propose ClusterClip Sampling to balance the text distribution of training data for better model training. Specifically, ClusterClip Sampling utilizes data clustering to reflect the data distribution of the training set and balances the common samples and rare samples during training based on the cluster results. A repetition clip operation is introduced to mitigate the overfitting issue led by samples from certain clusters. Extensive experiments validate the effectiveness of ClusterClip Sampling, which outperforms random sampling and other cluster-based sampling variants under various training datasets and large language models.