 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCOLO: A Contrastive Learning based Re-ranking Framework for One-Stage Summarization
Paper and Code
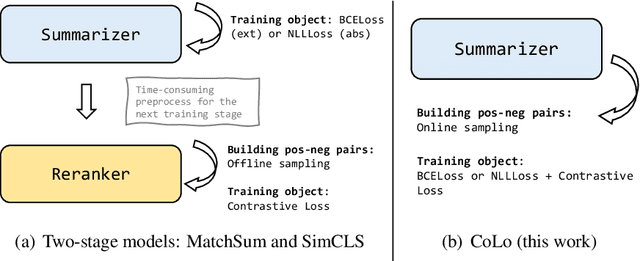

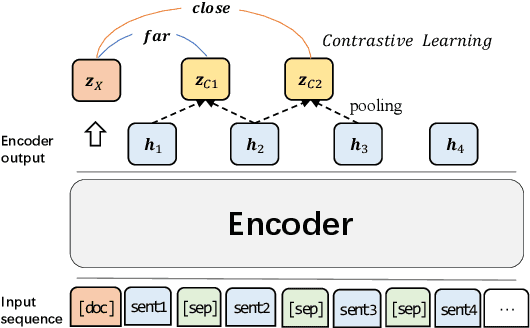
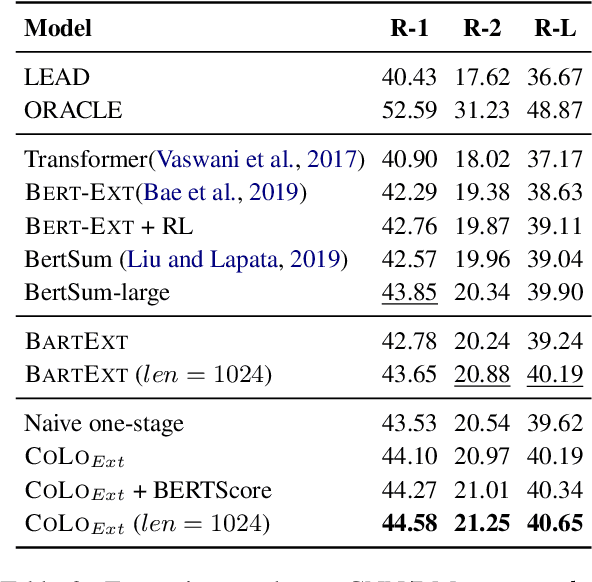
Traditional training paradigms for extractive and abstractive summarization systems always only use token-level or sentence-level training objectives. However, the output summary is always evaluated from summary-level which leads to the inconsistency in training and evaluation. In this paper, we propose a Contrastive Learning based re-ranking framework for one-stage summarization called COLO. By modeling a contrastive objective, we show that the summarization model is able to directly generate summaries according to the summary-level score without additional modules and parameters. Extensive experiments demonstrate that COLO boosts the extractive and abstractive results of one-stage systems on CNN/DailyMail benchmark to 44.58 and 46.33 ROUGE-1 score while preserving the parameter efficiency and inference efficiency. Compared with state-of-the-art multi-stage systems, we save more than 100 GPU training hours and obtaining 3~8 speed-up ratio during inference while maintaining comparable results.