 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInformation Retrieval and Classification of Real-Time Multi-Source Hurricane Evacuation Notices
Jan 07, 2024For an approaching disaster, the tracking of time-sensitive critical information such as hurricane evacuation notices is challenging in the United States. These notices are issued and distributed rapidly by numerous local authorities that may spread across multiple states. They often undergo frequent updates and are distributed through diverse online portals lacking standard formats. In this study, we developed an approach to timely detect and track the locally issued hurricane evacuation notices. The text data were collected mainly with a spatially targeted web scraping method. They were manually labeled and then classified using natural language processing techniques with deep learning models. The classification of mandatory evacuation notices achieved a high accuracy (recall = 96%). We used Hurricane Ian (2022) to illustrate how real-time evacuation notices extracted from local government sources could be redistributed with a Web GIS system. Our method applied to future hurricanes provides live data for situation awareness to higher-level government agencies and news media. The archived data helps scholars to study government responses toward weather warnings and individual behaviors influenced by evacuation history. The framework may be applied to other types of disasters for rapid and targeted retrieval, classification, redistribution, and archiving of real-time government orders and notifications.
Multi-label classification for biomedical literature: an overview of the BioCreative VII LitCovid Track for COVID-19 literature topic annotations
Apr 20, 2022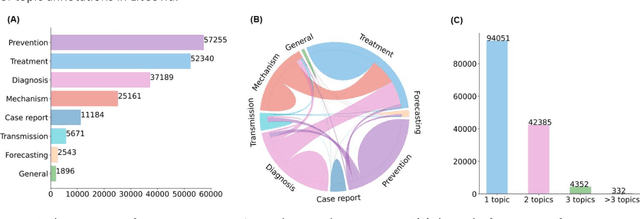
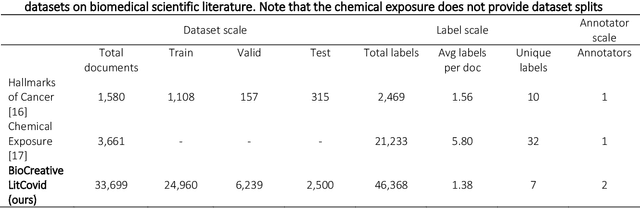
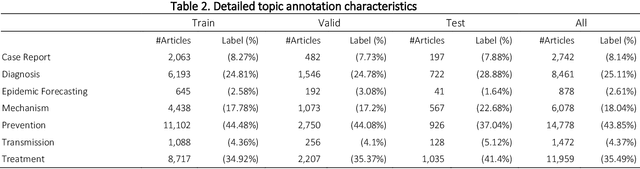
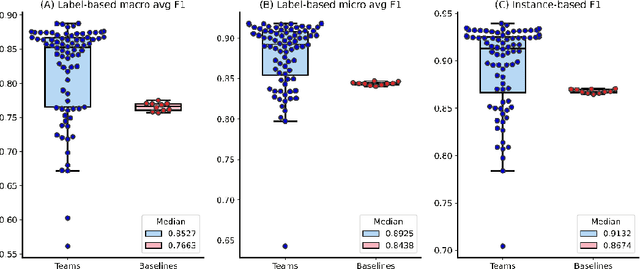
The COVID-19 pandemic has been severely impacting global society since December 2019. Massive research has been undertaken to understand the characteristics of the virus and design vaccines and drugs. The related findings have been reported in biomedical literature at a rate of about 10,000 articles on COVID-19 per month. Such rapid growth significantly challenges manual curation and interpretation. For instance, LitCovid is a literature database of COVID-19-related articles in PubMed, which has accumulated more than 200,000 articles with millions of accesses each month by users worldwide. One primary curation task is to assign up to eight topics (e.g., Diagnosis and Treatment) to the articles in LitCovid. Despite the continuing advances in biomedical text mining methods, few have been dedicated to topic annotations in COVID-19 literature. To close the gap, we organized the BioCreative LitCovid track to call for a community effort to tackle automated topic annotation for COVID-19 literature. The BioCreative LitCovid dataset, consisting of over 30,000 articles with manually reviewed topics, was created for training and testing. It is one of the largest multilabel classification datasets in biomedical scientific literature. 19 teams worldwide participated and made 80 submissions in total. Most teams used hybrid systems based on transformers. The highest performing submissions achieved 0.8875, 0.9181, and 0.9394 for macro F1-score, micro F1-score, and instance-based F1-score, respectively. The level of participation and results demonstrate a successful track and help close the gap between dataset curation and method development. The dataset is publicly available via https://ftp.ncbi.nlm.nih.gov/pub/lu/LitCovid/biocreative/ for benchmarking and further development.
Multi-Granularity Self-Attention for Neural Machine Translation
Sep 05, 2019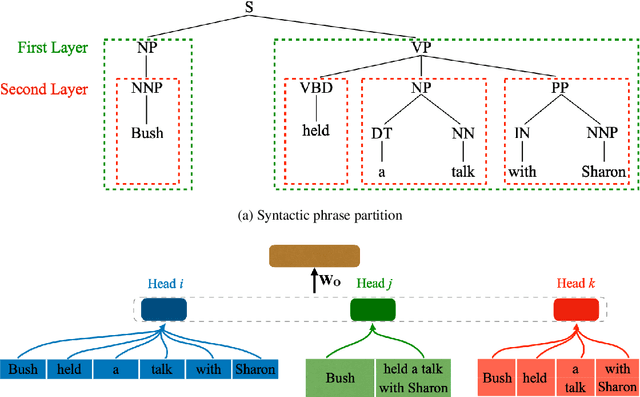
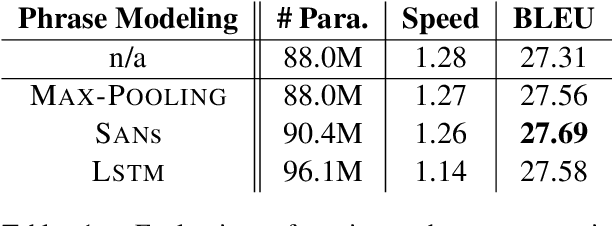
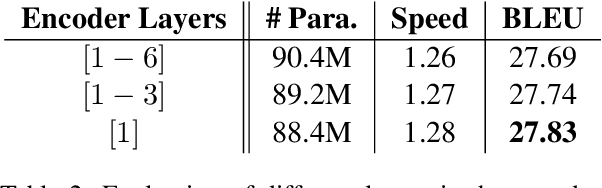

Current state-of-the-art neural machine translation (NMT) uses a deep multi-head self-attention network with no explicit phrase information. However, prior work on statistical machine translation has shown that extending the basic translation unit from words to phrases has produced substantial improvements, suggesting the possibility of improving NMT performance from explicit modeling of phrases. In this work, we present multi-granularity self-attention (Mg-Sa): a neural network that combines multi-head self-attention and phrase modeling. Specifically, we train several attention heads to attend to phrases in either n-gram or syntactic formalism. Moreover, we exploit interactions among phrases to enhance the strength of structure modeling - a commonly-cited weakness of self-attention. Experimental results on WMT14 English-to-German and NIST Chinese-to-English translation tasks show the proposed approach consistently improves performance. Targeted linguistic analysis reveals that Mg-Sa indeed captures useful phrase information at various levels of granularities.
Towards Better Modeling Hierarchical Structure for Self-Attention with Ordered Neurons
Sep 04, 2019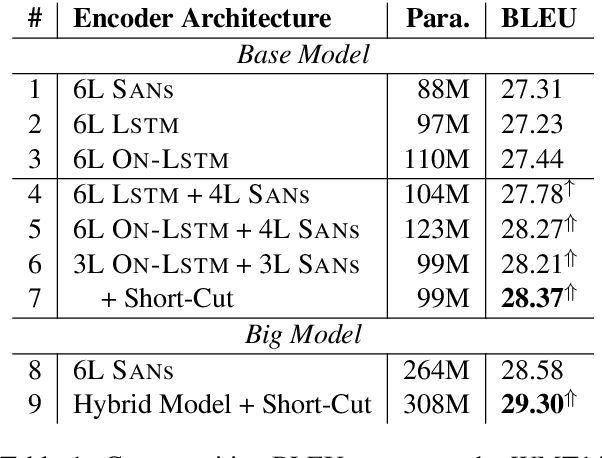
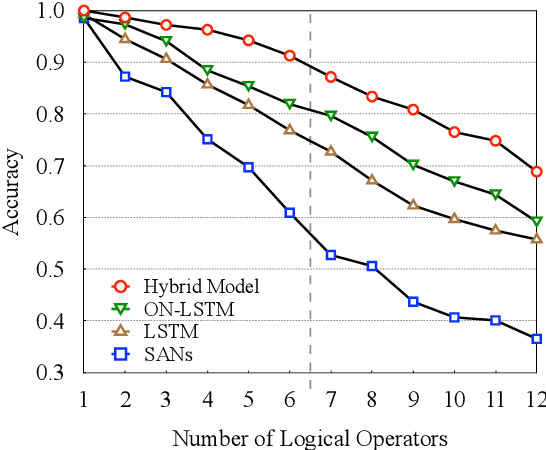

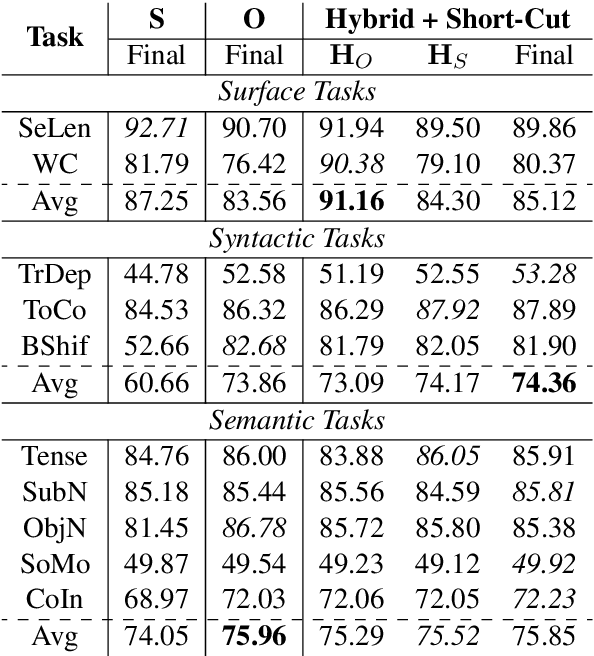
Recent studies have shown that a hybrid of self-attention networks (SANs) and recurrent neural networks (RNNs) outperforms both individual architectures, while not much is known about why the hybrid models work. With the belief that modeling hierarchical structure is an essential complementary between SANs and RNNs, we propose to further enhance the strength of hybrid models with an advanced variant of RNNs - Ordered Neurons LSTM (ON-LSTM), which introduces a syntax-oriented inductive bias to perform tree-like composition. Experimental results on the benchmark machine translation task show that the proposed approach outperforms both individual architectures and a standard hybrid model. Further analyses on targeted linguistic evaluation and logical inference tasks demonstrate that the proposed approach indeed benefits from a better modeling of hierarchical structure.
Modeling Recurrence for Transformer
Apr 05, 2019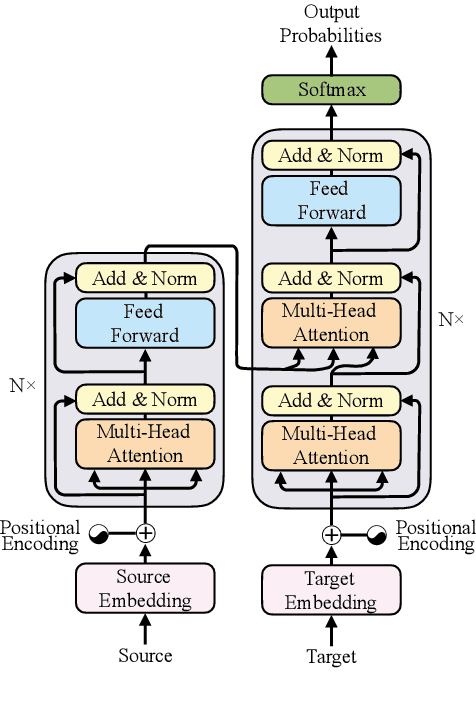

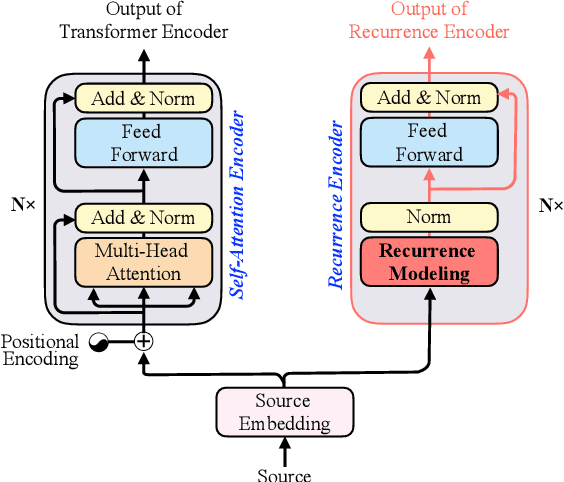
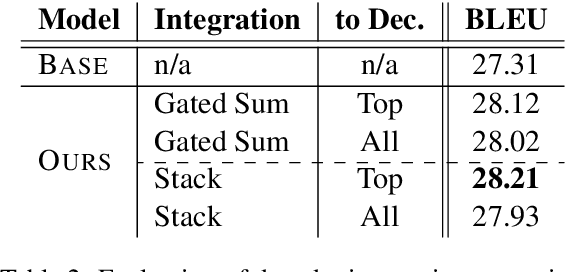
Recently, the Transformer model that is based solely on attention mechanisms, has advanced the state-of-the-art on various machine translation tasks. However, recent studies reveal that the lack of recurrence hinders its further improvement of translation capacity. In response to this problem, we propose to directly model recurrence for Transformer with an additional recurrence encoder. In addition to the standard recurrent neural network, we introduce a novel attentive recurrent network to leverage the strengths of both attention and recurrent networks. Experimental results on the widely-used WMT14 English-German and WMT17 Chinese-English translation tasks demonstrate the effectiveness of the proposed approach. Our studies also reveal that the proposed model benefits from a short-cut that bridges the source and target sequences with a single recurrent layer, which outperforms its deep counterpart.
Simulation Study on a New Peer Review Approach
Jun 11, 2018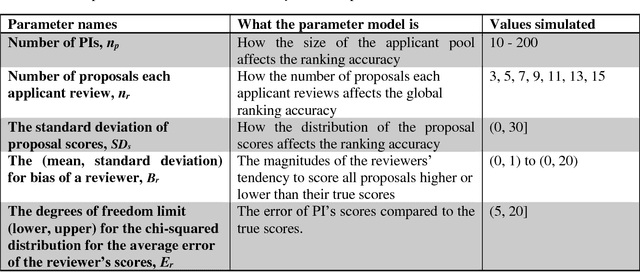
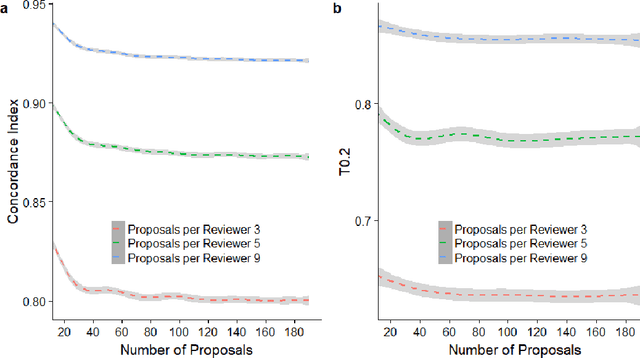
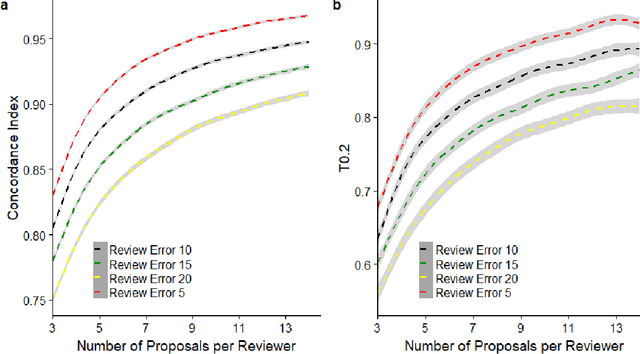
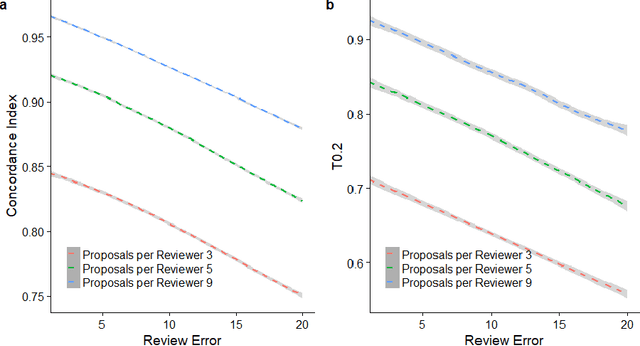
The increasing volume of scientific publications and grant proposals has generated an unprecedentedly high workload to scientific communities. Consequently, review quality has been decreasing and review outcomes have become less correlated with the real merits of the papers and proposals. A novel distributed peer review (DPR) approach has recently been proposed to address these issues. The new approach assigns principal investigators (PIs) who submitted proposals (or papers) to the same program as reviewers. Each PI reviews and ranks a small number (such as seven) of other PIs' proposals. The individual rankings are then used to estimate a global ranking of all proposals using the Modified Borda Count (MBC). In this study, we perform simulation studies to investigate several parameters important for the decision making when adopting this new approach. We also propose a new method called Concordance Index-based Global Ranking (CIGR) to estimate global ranking from individual rankings. An efficient simulated annealing algorithm is designed to search the optimal Concordance Index (CI). Moreover, we design a new balanced review assignment procedure, which can result in significantly better performance for both MBC and CIGR methods. We found that CIGR performs better than MBC when the review quality is relatively high. As review quality and review difficulty are tightly correlated, we constructed a boundary in the space of review quality vs review difficulty that separates the CIGR-superior and MBC-superior regions. Finally, we propose a multi-stage DPR strategy based on CIGR, which has the potential to substantially improve the overall review performance while reducing the review workload.