 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploiting Dynamic and Fine-grained Semantic Scope for Extreme Multi-label Text Classification
Paper and Code
May 24, 2022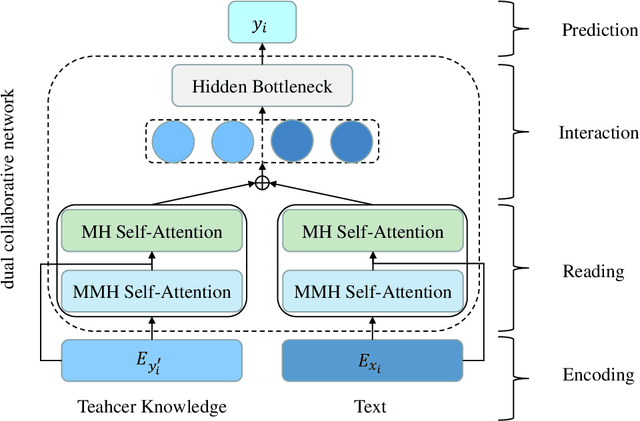

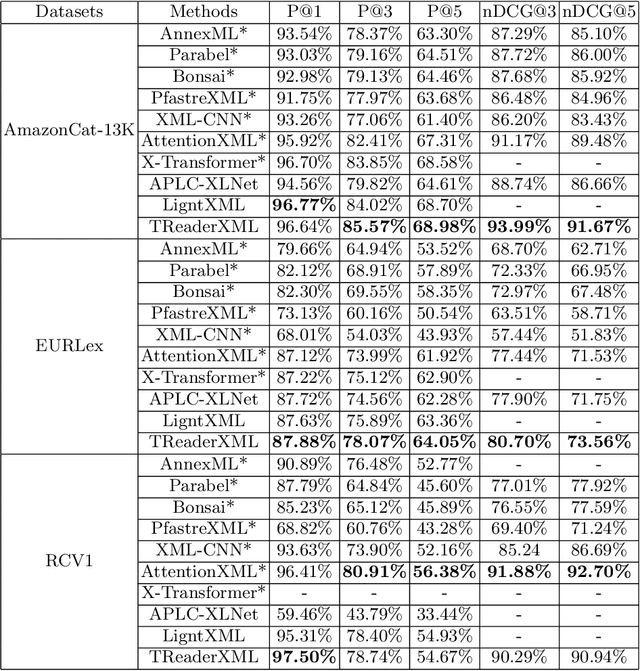
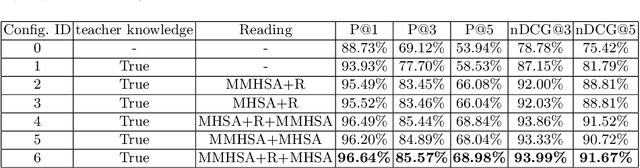
Extreme multi-label text classification (XMTC) refers to the problem of tagging a given text with the most relevant subset of labels from a large label set. A majority of labels only have a few training instances due to large label dimensionality in XMTC. To solve this data sparsity issue, most existing XMTC methods take advantage of fixed label clusters obtained in early stage to balance performance on tail labels and head labels. However, such label clusters provide static and coarse-grained semantic scope for every text, which ignores distinct characteristics of different texts and has difficulties modelling accurate semantics scope for texts with tail labels. In this paper, we propose a novel framework TReaderXML for XMTC, which adopts dynamic and fine-grained semantic scope from teacher knowledge for individual text to optimize text conditional prior category semantic ranges. TReaderXML dynamically obtains teacher knowledge for each text by similar texts and hierarchical label information in training sets to release the ability of distinctly fine-grained label-oriented semantic scope. Then, TReaderXML benefits from a novel dual cooperative network that firstly learns features of a text and its corresponding label-oriented semantic scope by parallel Encoding Module and Reading Module, secondly embeds two parts by Interaction Module to regularize the text's representation by dynamic and fine-grained label-oriented semantic scope, and finally find target labels by Prediction Module. Experimental results on three XMTC benchmark datasets show that our method achieves new state-of-the-art results and especially performs well for severely imbalanced and sparse datasets.