 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMaximum a Posteriori Inference for Factor Graphs via Benders' Decomposition
Oct 24, 2024



Many Bayesian statistical inference problems come down to computing a maximum a-posteriori (MAP) assignment of latent variables. Yet, standard methods for estimating the MAP assignment do not have a finite time guarantee that the algorithm has converged to a fixed point. Previous research has found that MAP inference can be represented in dual form as a linear programming problem with a non-polynomial number of constraints. A Lagrangian relaxation of the dual yields a statistical inference algorithm as a linear programming problem. However, the decision as to which constraints to remove in the relaxation is often heuristic. We present a method for maximum a-posteriori inference in general Bayesian factor models that sequentially adds constraints to the fully relaxed dual problem using Benders' decomposition. Our method enables the incorporation of expressive integer and logical constraints in clustering problems such as must-link, cannot-link, and a minimum number of whole samples allocated to each cluster. Using this approach, we derive MAP estimation algorithms for the Bayesian Gaussian mixture model and latent Dirichlet allocation. Empirical results show that our method produces a higher optimal posterior value compared to Gibbs sampling and variational Bayes methods for standard data sets and provides certificate of convergence.
Cost-aware Generalized $α$-investing for Multiple Hypothesis Testing
Oct 31, 2022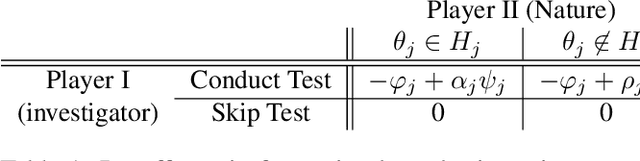
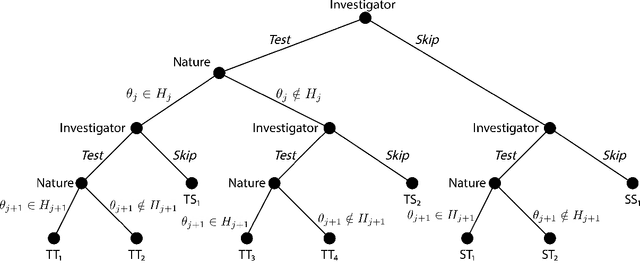
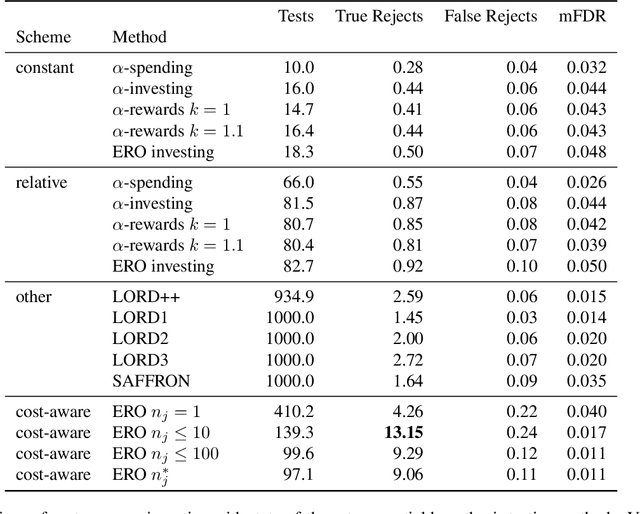
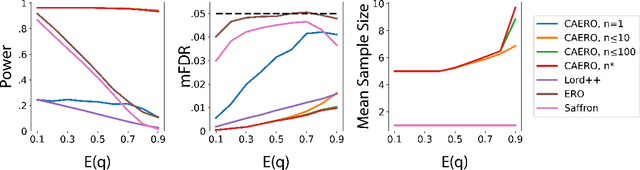
We consider the problem of sequential multiple hypothesis testing with nontrivial data collection cost. This problem appears, for example, when conducting biological experiments to identify differentially expressed genes in a disease process. This work builds on the generalized $\alpha$-investing framework that enables control of the false discovery rate in a sequential testing setting. We make a theoretical analysis of the long term asymptotic behavior of $\alpha$-wealth which motivates a consideration of sample size in the $\alpha$-investing decision rule. Using the game theoretic principle of indifference, we construct a decision rule that optimizes the expected return (ERO) of $\alpha$-wealth and provides an optimal sample size for the test. We show empirical results that a cost-aware ERO decision rule correctly rejects more false null hypotheses than other methods. We extend cost-aware ERO investing to finite-horizon testing which enables the decision rule to hedge against the risk of unproductive tests. Finally, empirical tests on a real data set from a biological experiment show that cost-aware ERO produces actionable decisions as to which tests to conduct and if so at what sample size.