 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQ-YOLOP: Quantization-aware You Only Look Once for Panoptic Driving Perception
Paper and Code

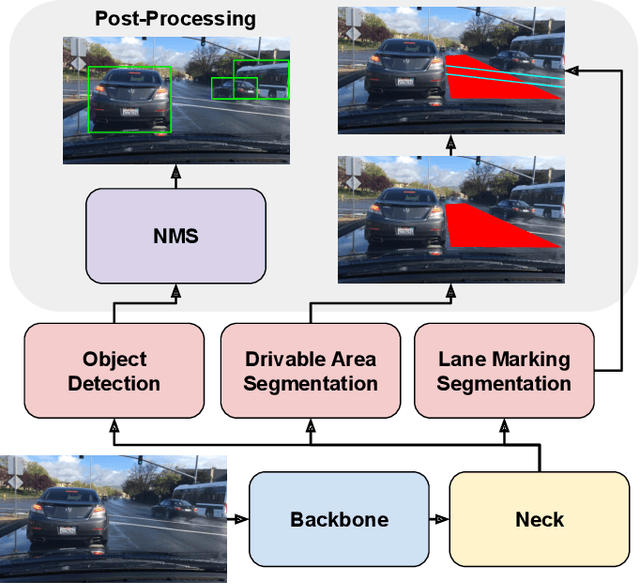

In this work, we present an efficient and quantization-aware panoptic driving perception model (Q- YOLOP) for object detection, drivable area segmentation, and lane line segmentation, in the context of autonomous driving. Our model employs the Efficient Layer Aggregation Network (ELAN) as its backbone and task-specific heads for each task. We employ a four-stage training process that includes pretraining on the BDD100K dataset, finetuning on both the BDD100K and iVS datasets, and quantization-aware training (QAT) on BDD100K. During the training process, we use powerful data augmentation techniques, such as random perspective and mosaic, and train the model on a combination of the BDD100K and iVS datasets. Both strategies enhance the model's generalization capabilities. The proposed model achieves state-of-the-art performance with an mAP@0.5 of 0.622 for object detection and an mIoU of 0.612 for segmentation, while maintaining low computational and memory requirements.