 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBenchmarking Robustness of Text-Image Composed Retrieval
Paper and Code

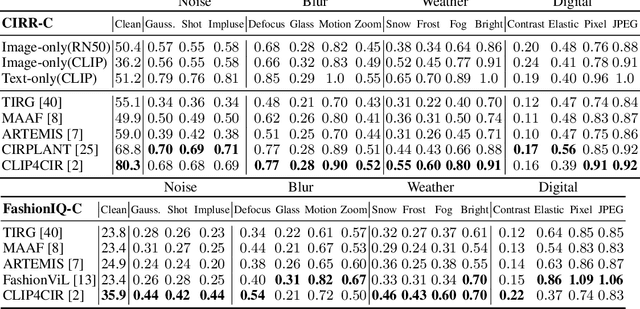


Text-image composed retrieval aims to retrieve the target image through the composed query, which is specified in the form of an image plus some text that describes desired modifications to the input image. It has recently attracted attention due to its ability to leverage both information-rich images and concise language to precisely express the requirements for target images. However, the robustness of these approaches against real-world corruptions or further text understanding has never been studied. In this paper, we perform the first robustness study and establish three new diversified benchmarks for systematic analysis of text-image composed retrieval against natural corruptions in both vision and text and further probe textural understanding. For natural corruption analysis, we introduce two new large-scale benchmark datasets, CIRR-C and FashionIQ-C for testing in open domain and fashion domain respectively, both of which apply 15 visual corruptions and 7 textural corruptions. For textural understanding analysis, we introduce a new diagnostic dataset CIRR-D by expanding the original raw data with synthetic data, which contains modified text to better probe textual understanding ability including numerical variation, attribute variation, object removal, background variation, and fine-grained evaluation. The code and benchmark datasets are available at https://github.com/SunTongtongtong/Benchmark-Robustness-Text-Image-Compose-Retrieval.