 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLine Flow based SLAM
Sep 21, 2020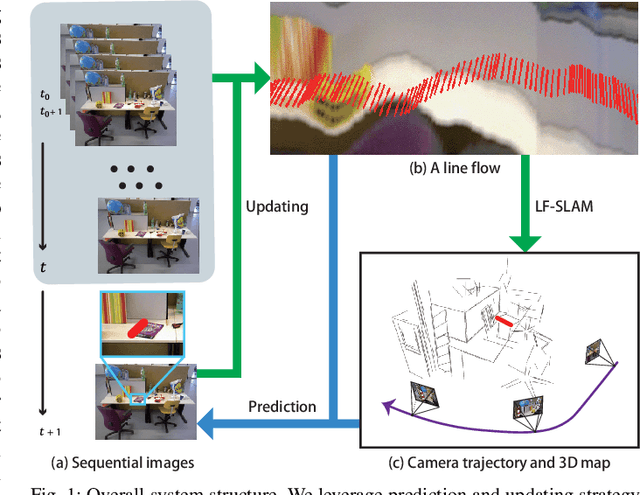
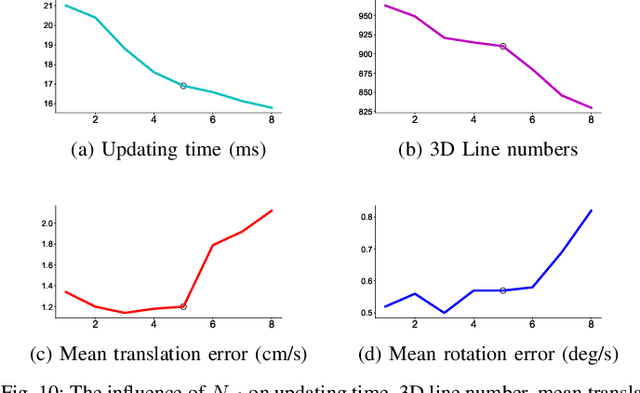

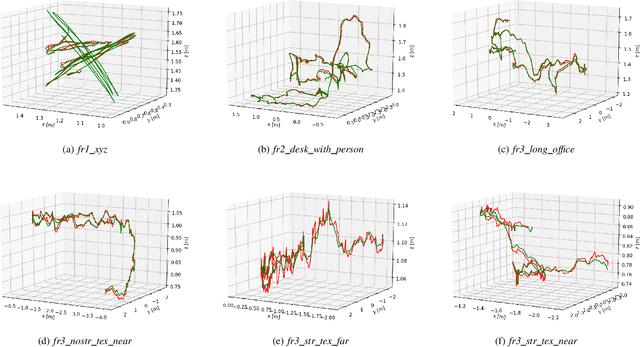
We propose a method of visual SLAM by predicting and updating line flows that represent sequential 2D projections of 3D line segments. While indirect SLAM methods using points and line segments have achieved excellent results, they still face problems in challenging scenarios such as occlusions, image blur, and repetitive textures. To deal with these problems, we leverage line flows which encode the coherence of 2D and 3D line segments in spatial and temporal domains as the sequence of all the 2D line segments corresponding to a specific 3D line segment. Thanks to the line flow representation, the corresponding 2D line segment in a new frame can be predicted based on 2D and 3D line segment motions. We create, update, merge, and discard line flows on-the-fly. We model our Line Flow-based SLAM (LF-SLAM) using a Bayesian network. We perform short-term optimization in front-end, and long-term optimization in back-end. The constraints introduced in line flows improve the performance of our LF-SLAM. Extensive experimental results demonstrate that our method achieves better performance than state-of-the-art direct and indirect SLAM approaches. Specifically, it obtains good localization and mapping results in challenging scenes with occlusions, image blur, and repetitive textures.
Local Supports Global: Deep Camera Relocalization with Sequence Enhancement
Aug 06, 2019


We propose to leverage the local information in image sequences to support global camera relocalization. In contrast to previous methods that regress global poses from single images, we exploit the spatial-temporal consistency in sequential images to alleviate uncertainty due to visual ambiguities by incorporating a visual odometry (VO) component. Specifically, we introduce two effective steps called content-augmented pose estimation and motion-based refinement. The content-augmentation step focuses on alleviating the uncertainty of pose estimation by augmenting the observation based on the co-visibility in local maps built by the VO stream. Besides, the motion-based refinement is formulated as a pose graph, where the camera poses are further optimized by adopting relative poses provided by the VO component as additional motion constraints. Thus, the global consistency can be guaranteed. Experiments on the public indoor 7-Scenes and outdoor Oxford RobotCar benchmark datasets demonstrate that benefited from local information inherent in the sequence, our approach outperforms state-of-the-art methods, especially in some challenging cases, e.g., insufficient texture, highly repetitive textures, similar appearances, and over-exposure.
Beyond Tracking: Selecting Memory and Refining Poses for Deep Visual Odometry
Apr 05, 2019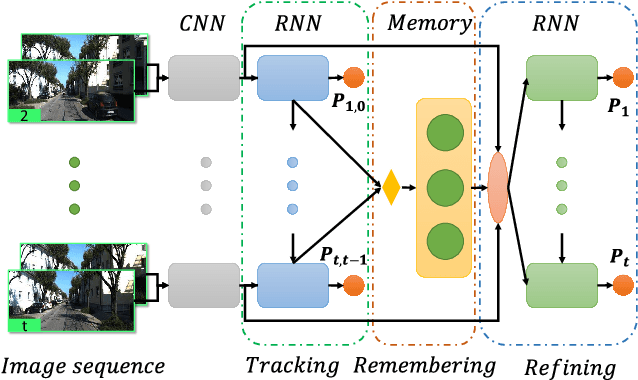
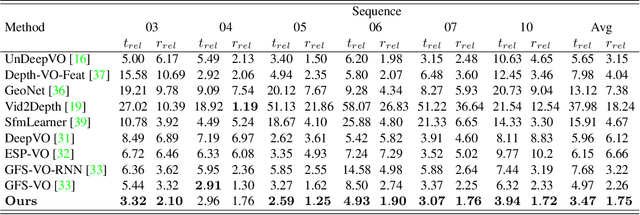

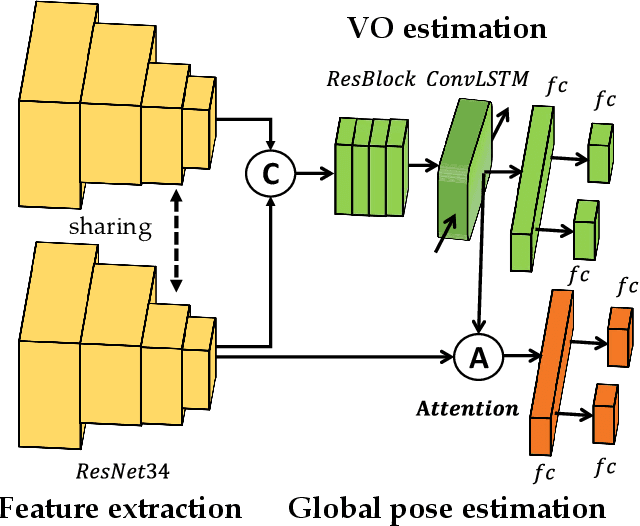
Most previous learning-based visual odometry (VO) methods take VO as a pure tracking problem. In contrast, we present a VO framework by incorporating two additional components called Memory and Refining. The Memory component preserves global information by employing an adaptive and efficient selection strategy. The Refining component ameliorates previous results with the contexts stored in the Memory by adopting a spatial-temporal attention mechanism for feature distilling. Experiments on the KITTI and TUM-RGBD benchmark datasets demonstrate that our method outperforms state-of-the-art learning-based methods by a large margin and produces competitive results against classic monocular VO approaches. Especially, our model achieves outstanding performance in challenging scenarios such as texture-less regions and abrupt motions, where classic VO algorithms tend to fail.
Guided Feature Selection for Deep Visual Odometry
Nov 25, 2018
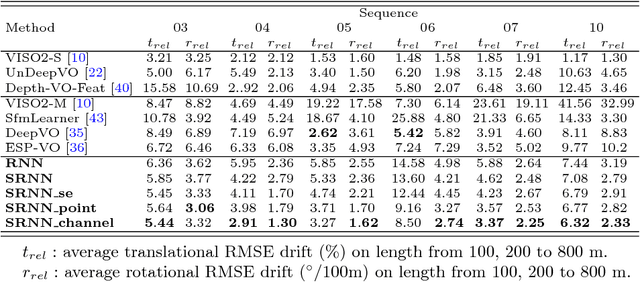
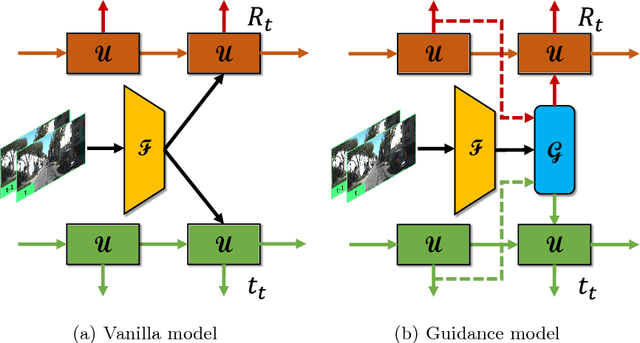

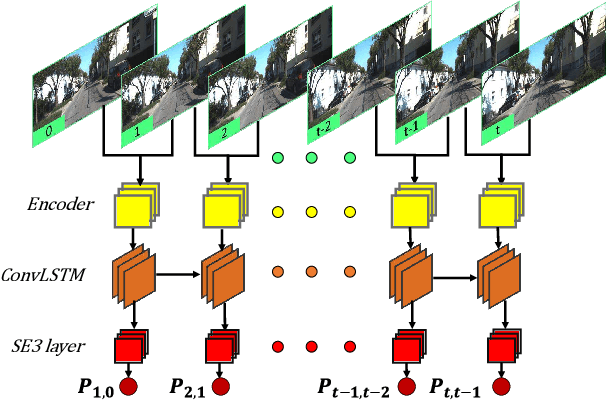
We present a novel end-to-end visual odometry architecture with guided feature selection based on deep convolutional recurrent neural networks. Different from current monocular visual odometry methods, our approach is established on the intuition that features contribute discriminately to different motion patterns. Specifically, we propose a dual-branch recurrent network to learn the rotation and translation separately by leveraging current Convolutional Neural Network (CNN) for feature representation and Recurrent Neural Network (RNN) for image sequence reasoning. To enhance the ability of feature selection, we further introduce an effective context-aware guidance mechanism to force each branch to distill related information for specific motion pattern explicitly. Experiments demonstrate that on the prevalent KITTI and ICL_NUIM benchmarks, our method outperforms current state-of-the-art model- and learning-based methods for both decoupled and joint camera pose recovery.
PSDF Fusion: Probabilistic Signed Distance Function for On-the-fly 3D Data Fusion and Scene Reconstruction
Jul 29, 2018


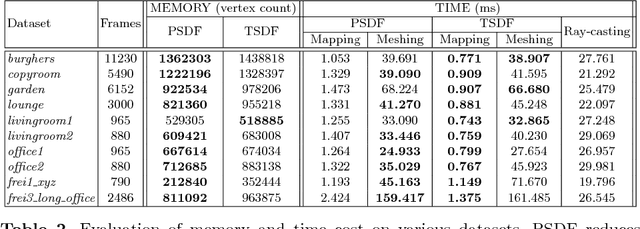
We propose a novel 3D spatial representation for data fusion and scene reconstruction. Probabilistic Signed Distance Function (Probabilistic SDF, PSDF) is proposed to depict uncertainties in the 3D space. It is modeled by a joint distribution describing SDF value and its inlier probability, reflecting input data quality and surface geometry. A hybrid data structure involving voxel, surfel, and mesh is designed to fully exploit the advantages of various prevalent 3D representations. Connected by PSDF, these components reasonably cooperate in a consistent frame- work. Given sequential depth measurements, PSDF can be incrementally refined with less ad hoc parametric Bayesian updating. Supported by PSDF and the efficient 3D data representation, high-quality surfaces can be extracted on-the-fly, and in return contribute to reliable data fu- sion using the geometry information. Experiments demonstrate that our system reconstructs scenes with higher model quality and lower redundancy, and runs faster than existing online mesh generation systems.
Efficient Traffic-Sign Recognition with Scale-aware CNN
May 31, 2018



The paper presents a Traffic Sign Recognition (TSR) system, which can fast and accurately recognize traffic signs of different sizes in images. The system consists of two well-designed Convolutional Neural Networks (CNNs), one for region proposals of traffic signs and one for classification of each region. In the proposal CNN, a Fully Convolutional Network (FCN) with a dual multi-scale architecture is proposed to achieve scale invariant detection. In training the proposal network, a modified "Online Hard Example Mining" (OHEM) scheme is adopted to suppress false positives. The classification network fuses multi-scale features as representation and adopts an "Inception" module for efficiency. We evaluate the proposed TSR system and its components with extensive experiments. Our method obtains $99.88\%$ precision and $96.61\%$ recall on the Swedish Traffic Signs Dataset (STSD), higher than state-of-the-art methods. Besides, our system is faster and more lightweight than state-of-the-art deep learning networks for traffic sign recognition.