 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFusionBERT: Multi-View Image-3D Retrieval via Cross-Attention Visual Fusion and Normal-Aware 3D Encoder
Apr 02, 2026We propose FusionBERT, a novel multi-view visual fusion framework for image-3D multimodal retrieval. Existing image-3D representation learning methods predominantly focus on feature alignment of a single object image and its 3D model, limiting their applicability in realistic scenarios where an object is typically observed and captured from multiple viewpoints. Although multi-view observations naturally provide complementary geometric and appearance cues, existing multimodal large models rarely explore how to effectively fuse such multi-view visual information for better cross-modal retrieval. To address this limitation, we introduce a multi-view image-3D retrieval framework named FusionBERT, which innovatively utilizes a cross-attention-based multi-view visual aggregator to adaptively integrate features from multi-view images of an object. The proposed multi-view visual encoder fuses inter-view complementary relationships and selectively emphasizes informative visual cues across multiple views to get a more robustly fused visual feature for better 3D model matching. Furthermore, FusionBERT proposes a normal-aware 3D model encoder that can further enhance the 3D geometric feature of an object model by jointly encoding point normals and 3D positions, enabling a more robust representation learning for textureless or color-degraded 3D models. Extensive image-3D retrieval experiments demonstrate that FusionBERT achieves significantly higher retrieval accuracy than SOTA multimodal large models under both single-view and multi-view settings, establishing a strong baseline for multi-view multimodal retrieval.
GeoTexDensifier: Geometry-Texture-Aware Densification for High-Quality Photorealistic 3D Gaussian Splatting
Dec 22, 2024



3D Gaussian Splatting (3DGS) has recently attracted wide attentions in various areas such as 3D navigation, Virtual Reality (VR) and 3D simulation, due to its photorealistic and efficient rendering performance. High-quality reconstrution of 3DGS relies on sufficient splats and a reasonable distribution of these splats to fit real geometric surface and texture details, which turns out to be a challenging problem. We present GeoTexDensifier, a novel geometry-texture-aware densification strategy to reconstruct high-quality Gaussian splats which better comply with the geometric structure and texture richness of the scene. Specifically, our GeoTexDensifier framework carries out an auxiliary texture-aware densification method to produce a denser distribution of splats in fully textured areas, while keeping sparsity in low-texture regions to maintain the quality of Gaussian point cloud. Meanwhile, a geometry-aware splitting strategy takes depth and normal priors to guide the splitting sampling and filter out the noisy splats whose initial positions are far from the actual geometric surfaces they aim to fit, under a Validation of Depth Ratio Change checking. With the help of relative monocular depth prior, such geometry-aware validation can effectively reduce the influence of scattered Gaussians to the final rendering quality, especially in regions with weak textures or without sufficient training views. The texture-aware densification and geometry-aware splitting strategies are fully combined to obtain a set of high-quality Gaussian splats. We experiment our GeoTexDensifier framework on various datasets and compare our Novel View Synthesis results to other state-of-the-art 3DGS approaches, with detailed quantitative and qualitative evaluations to demonstrate the effectiveness of our method in producing more photorealistic 3DGS models.
Quadratic Gaussian Splatting for Efficient and Detailed Surface Reconstruction
Nov 25, 2024



Recently, 3D Gaussian Splatting (3DGS) has attracted attention for its superior rendering quality and speed over Neural Radiance Fields (NeRF). To address 3DGS's limitations in surface representation, 2D Gaussian Splatting (2DGS) introduced disks as scene primitives to model and reconstruct geometries from multi-view images, offering view-consistent geometry. However, the disk's first-order linear approximation often leads to over-smoothed results. We propose Quadratic Gaussian Splatting (QGS), a novel method that replaces disks with quadric surfaces, enhancing geometric fitting, whose code will be open-sourced. QGS defines Gaussian distributions in non-Euclidean space, allowing primitives to capture more complex textures. As a second-order surface approximation, QGS also renders spatial curvature to guide the normal consistency term, to effectively reduce over-smoothing. Moreover, QGS is a generalized version of 2DGS that achieves more accurate and detailed reconstructions, as verified by experiments on DTU and TNT, demonstrating its effectiveness in surpassing current state-of-the-art methods in geometry reconstruction. Our code willbe released as open source.
LiVisSfM: Accurate and Robust Structure-from-Motion with LiDAR and Visual Cues
Oct 29, 2024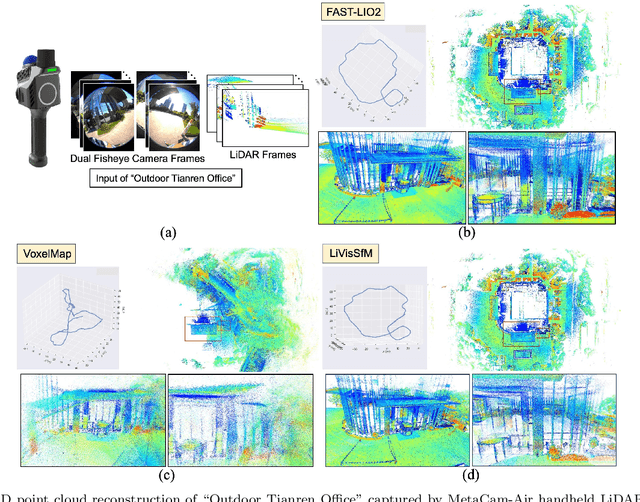

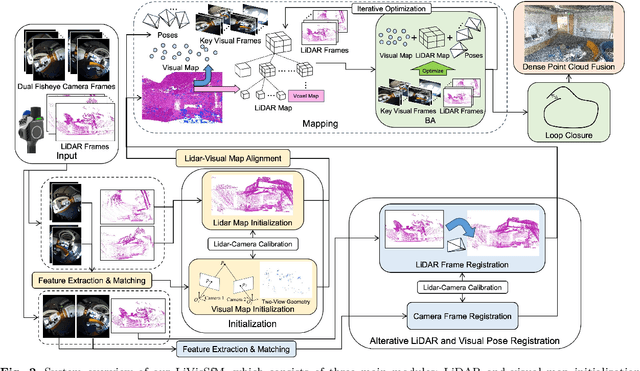

This paper presents an accurate and robust Structure-from-Motion (SfM) pipeline named LiVisSfM, which is an SfM-based reconstruction system that fully combines LiDAR and visual cues. Unlike most existing LiDAR-inertial odometry (LIO) and LiDAR-inertial-visual odometry (LIVO) methods relying heavily on LiDAR registration coupled with Inertial Measurement Unit (IMU), we propose a LiDAR-visual SfM method which innovatively carries out LiDAR frame registration to LiDAR voxel map in a Point-to-Gaussian residual metrics, combined with a LiDAR-visual BA and explicit loop closure in a bundle optimization way to achieve accurate and robust LiDAR pose estimation without dependence on IMU incorporation. Besides, we propose an incremental voxel updating strategy for efficient voxel map updating during the process of LiDAR frame registration and LiDAR-visual BA optimization. Experiments demonstrate the superior effectiveness of our LiVisSfM framework over state-of-the-art LIO and LIVO works on more accurate and robust LiDAR pose recovery and dense point cloud reconstruction of both public KITTI benchmark and a variety of self-captured dataset.
Quasi-Medial Distance Field (Q-MDF): A Robust Method for Approximating and Discretizing Neural Medial Axis
Oct 23, 2024The medial axis, a lower-dimensional shape descriptor, plays an important role in the field of digital geometry processing. Despite its importance, robust computation of the medial axis transform from diverse inputs, especially point clouds with defects, remains a significant challenge. In this paper, we tackle the challenge by proposing a new implicit method that diverges from mainstream explicit medial axis computation techniques. Our key technical insight is the difference between the signed distance field (SDF) and the medial field (MF) of a solid shape is the unsigned distance field (UDF) of the shape's medial axis. This allows for formulating medial axis computation as an implicit reconstruction problem. Utilizing a modified double covering method, we extract the medial axis as the zero level-set of the UDF. Extensive experiments show that our method has enhanced accuracy and robustness in learning compact medial axis transform from thorny meshes and point clouds compared to existing methods.
Learn to Memorize and to Forget: A Continual Learning Perspective of Dynamic SLAM
Jul 18, 2024
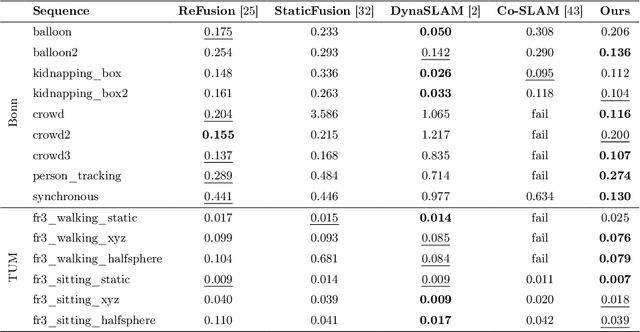

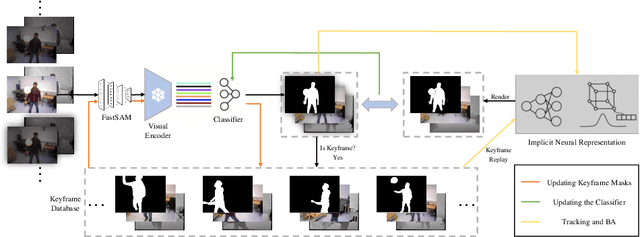
Simultaneous localization and mapping (SLAM) with implicit neural representations has received extensive attention due to the expressive representation power and the innovative paradigm of continual learning. However, deploying such a system within a dynamic environment has not been well-studied. Such challenges are intractable even for conventional algorithms since observations from different views with dynamic objects involved break the geometric and photometric consistency, whereas the consistency lays the foundation for joint optimizing the camera pose and the map parameters. In this paper, we best exploit the characteristics of continual learning and propose a novel SLAM framework for dynamic environments. While past efforts have been made to avoid catastrophic forgetting by exploiting an experience replay strategy, we view forgetting as a desirable characteristic. By adaptively controlling the replayed buffer, the ambiguity caused by moving objects can be easily alleviated through forgetting. We restrain the replay of the dynamic objects by introducing a continually-learned classifier for dynamic object identification. The iterative optimization of the neural map and the classifier notably improves the robustness of the SLAM system under a dynamic environment. Experiments on challenging datasets verify the effectiveness of the proposed framework.
Deep Fundamental Matrix Estimation without Correspondences
Oct 03, 2018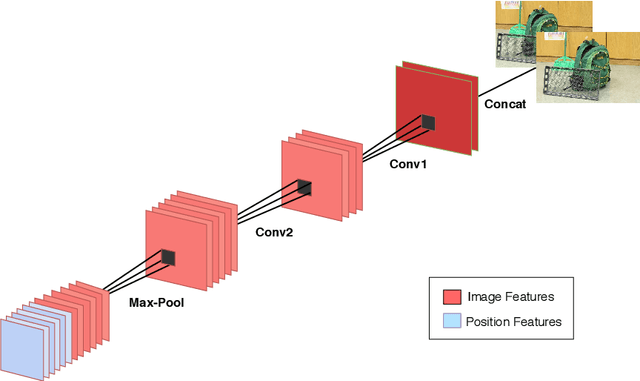
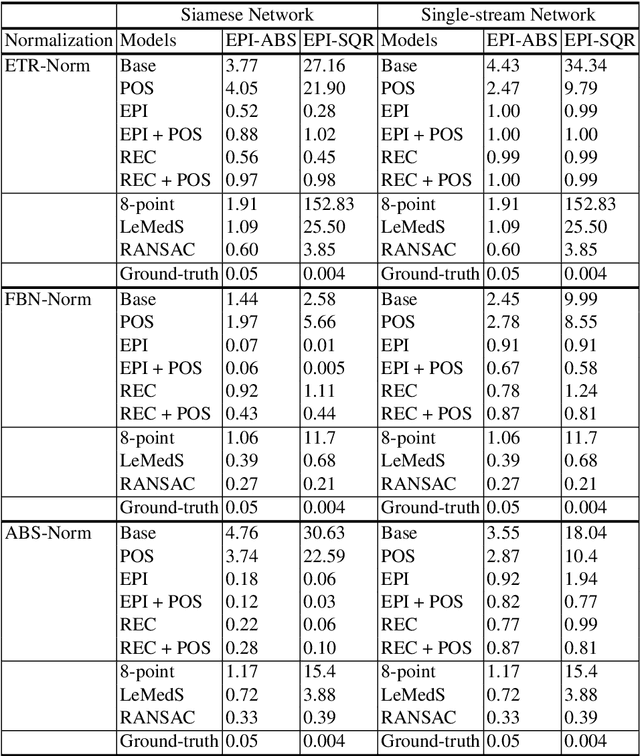
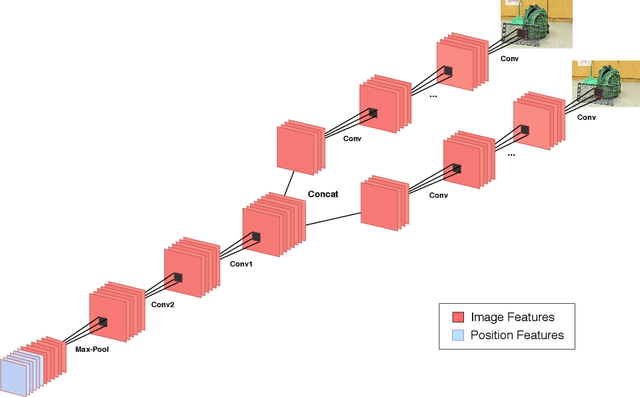
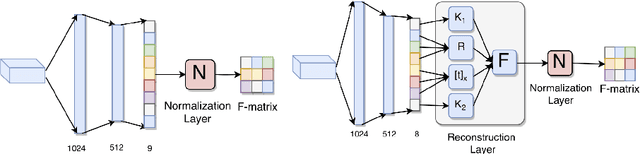
Estimating fundamental matrices is a classic problem in computer vision. Traditional methods rely heavily on the correctness of estimated key-point correspondences, which can be noisy and unreliable. As a result, it is difficult for these methods to handle image pairs with large occlusion or significantly different camera poses. In this paper, we propose novel neural network architectures to estimate fundamental matrices in an end-to-end manner without relying on point correspondences. New modules and layers are introduced in order to preserve mathematical properties of the fundamental matrix as a homogeneous rank-2 matrix with seven degrees of freedom. We analyze performance of the proposed models using various metrics on the KITTI dataset, and show that they achieve competitive performance with traditional methods without the need for extracting correspondences.