 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMVBIND: Self-Supervised Music Recommendation For Videos Via Embedding Space Binding
Paper and Code
May 15, 2024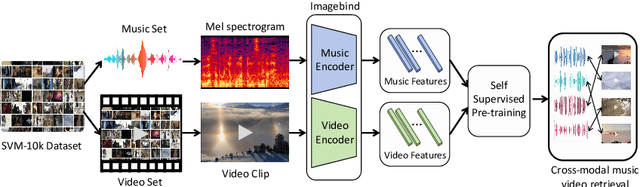
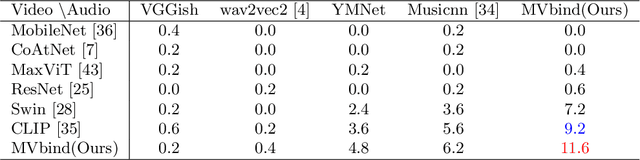

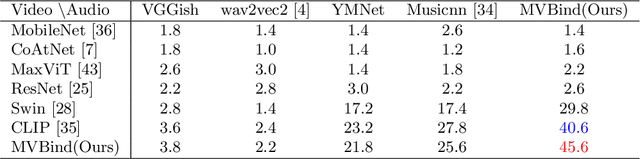
Recent years have witnessed the rapid development of short videos, which usually contain both visual and audio modalities. Background music is important to the short videos, which can significantly influence the emotions of the viewers. However, at present, the background music of short videos is generally chosen by the video producer, and there is a lack of automatic music recommendation methods for short videos. This paper introduces MVBind, an innovative Music-Video embedding space Binding model for cross-modal retrieval. MVBind operates as a self-supervised approach, acquiring inherent knowledge of intermodal relationships directly from data, without the need of manual annotations. Additionally, to compensate the lack of a corresponding musical-visual pair dataset for short videos, we construct a dataset, SVM-10K(Short Video with Music-10K), which mainly consists of meticulously selected short videos. On this dataset, MVBind manifests significantly improved performance compared to other baseline methods. The constructed dataset and code will be released to facilitate future research.