 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdversarial Attack for Explanation Robustness of Rationalization Models
Aug 20, 2024



Rationalization models, which select a subset of input text as rationale-crucial for humans to understand and trust predictions-have recently emerged as a prominent research area in eXplainable Artificial Intelligence. However, most of previous studies mainly focus on improving the quality of the rationale, ignoring its robustness to malicious attack. Specifically, whether the rationalization models can still generate high-quality rationale under the adversarial attack remains unknown. To explore this, this paper proposes UAT2E, which aims to undermine the explainability of rationalization models without altering their predictions, thereby eliciting distrust in these models from human users. UAT2E employs the gradient-based search on triggers and then inserts them into the original input to conduct both the non-target and target attack. Experimental results on five datasets reveal the vulnerability of rationalization models in terms of explanation, where they tend to select more meaningless tokens under attacks. Based on this, we make a series of recommendations for improving rationalization models in terms of explanation.
MGR: Multi-generator based Rationalization
May 23, 2023



Rationalization is to employ a generator and a predictor to construct a self-explaining NLP model in which the generator selects a subset of human-intelligible pieces of the input text to the following predictor. However, rationalization suffers from two key challenges, i.e., spurious correlation and degeneration, where the predictor overfits the spurious or meaningless pieces solely selected by the not-yet well-trained generator and in turn deteriorates the generator. Although many studies have been proposed to address the two challenges, they are usually designed separately and do not take both of them into account. In this paper, we propose a simple yet effective method named MGR to simultaneously solve the two problems. The key idea of MGR is to employ multiple generators such that the occurrence stability of real pieces is improved and more meaningful pieces are delivered to the predictor. Empirically, we show that MGR improves the F1 score by up to 20.9% as compared to state-of-the-art methods. Codes are available at https://github.com/jugechengzi/Rationalization-MGR .
FR: Folded Rationalization with a Unified Encoder
Sep 20, 2022

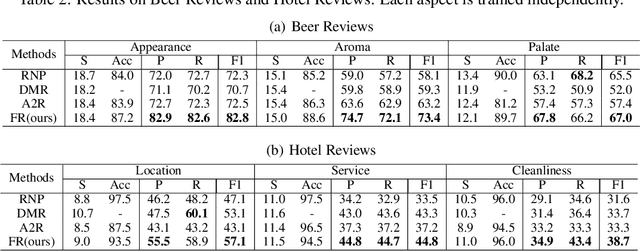
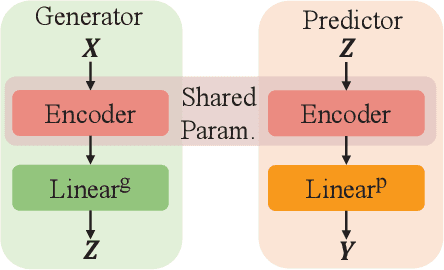
Conventional works generally employ a two-phase model in which a generator selects the most important pieces, followed by a predictor that makes predictions based on the selected pieces. However, such a two-phase model may incur the degeneration problem where the predictor overfits to the noise generated by a not yet well-trained generator and in turn, leads the generator to converge to a sub-optimal model that tends to select senseless pieces. To tackle this challenge, we propose Folded Rationalization (FR) that folds the two phases of the rationale model into one from the perspective of text semantic extraction. The key idea of FR is to employ a unified encoder between the generator and predictor, based on which FR can facilitate a better predictor by access to valuable information blocked by the generator in the traditional two-phase model and thus bring a better generator. Empirically, we show that FR improves the F1 score by up to 10.3% as compared to state-of-the-art methods.