 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSafeguarding System Prompts for LLMs
Dec 18, 2024



Large language models (LLMs) are increasingly utilized in applications where system prompts, which guide model outputs, play a crucial role. These prompts often contain business logic and sensitive information, making their protection essential. However, adversarial and even regular user queries can exploit LLM vulnerabilities to expose these hidden prompts. To address this issue, we present PromptKeeper, a novel defense mechanism for system prompt privacy. By reliably detecting worst-case leakage and regenerating outputs without the system prompt when necessary, PromptKeeper ensures robust protection against prompt extraction attacks via either adversarial or regular queries, while preserving conversational capability and runtime efficiency during benign user interactions.
Feature Reconstruction Attacks and Countermeasures of DNN training in Vertical Federated Learning
Oct 13, 2022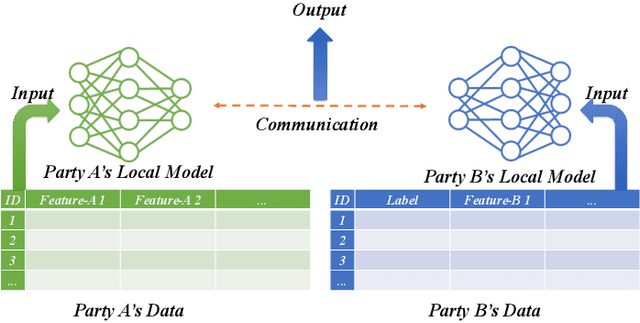
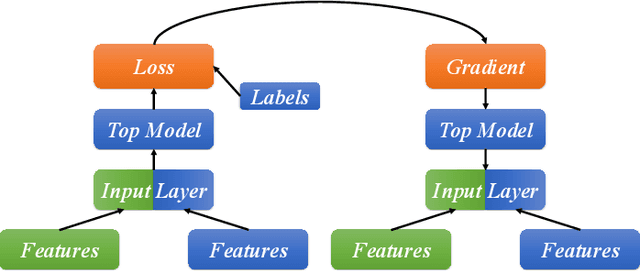
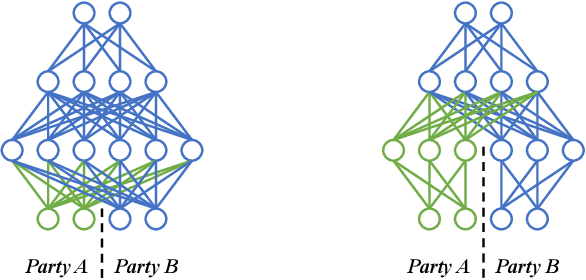
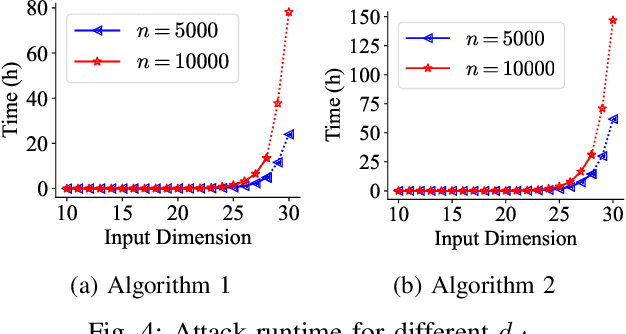
Federated learning (FL) has increasingly been deployed, in its vertical form, among organizations to facilitate secure collaborative training over siloed data. In vertical FL (VFL), participants hold disjoint features of the same set of sample instances. Among them, only one has labels. This participant, known as the active party, initiates the training and interacts with the other participants, known as the passive parties. Despite the increasing adoption of VFL, it remains largely unknown if and how the active party can extract feature data from the passive party, especially when training deep neural network (DNN) models. This paper makes the first attempt to study the feature security problem of DNN training in VFL. We consider a DNN model partitioned between active and passive parties, where the latter only holds a subset of the input layer and exhibits some categorical features of binary values. Using a reduction from the Exact Cover problem, we prove that reconstructing those binary features is NP-hard. Through analysis, we demonstrate that, unless the feature dimension is exceedingly large, it remains feasible, both theoretically and practically, to launch a reconstruction attack with an efficient search-based algorithm that prevails over current feature protection techniques. To address this problem, we develop a novel feature protection scheme against the reconstruction attack that effectively misleads the search to some pre-specified random values. With an extensive set of experiments, we show that our protection scheme sustains the feature reconstruction attack in various VFL applications at no expense of accuracy loss.
Pisces: Efficient Federated Learning via Guided Asynchronous Training
Jun 18, 2022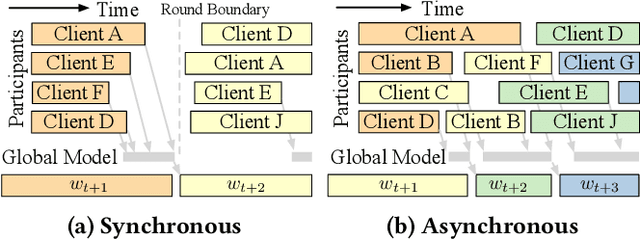
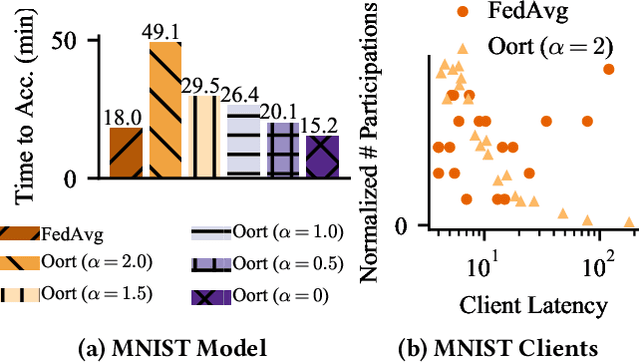

Federated learning (FL) is typically performed in a synchronous parallel manner, where the involvement of a slow client delays a training iteration. Current FL systems employ a participant selection strategy to select fast clients with quality data in each iteration. However, this is not always possible in practice, and the selection strategy often has to navigate an unpleasant trade-off between the speed and the data quality of clients. In this paper, we present Pisces, an asynchronous FL system with intelligent participant selection and model aggregation for accelerated training. To avoid incurring excessive resource cost and stale training computation, Pisces uses a novel scoring mechanism to identify suitable clients to participate in a training iteration. It also adapts the pace of model aggregation to dynamically bound the progress gap between the selected clients and the server, with a provable convergence guarantee in a smooth non-convex setting. We have implemented Pisces in an open-source FL platform called Plato, and evaluated its performance in large-scale experiments with popular vision and language models. Pisces outperforms the state-of-the-art synchronous and asynchronous schemes, accelerating the time-to-accuracy by up to 2.0x and 1.9x, respectively.
FLASHE: Additively Symmetric Homomorphic Encryption for Cross-Silo Federated Learning
Sep 29, 2021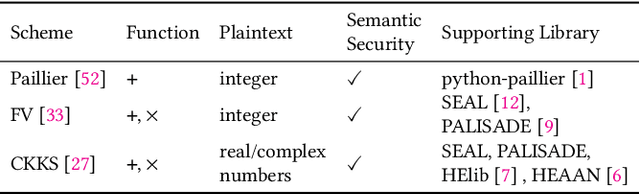
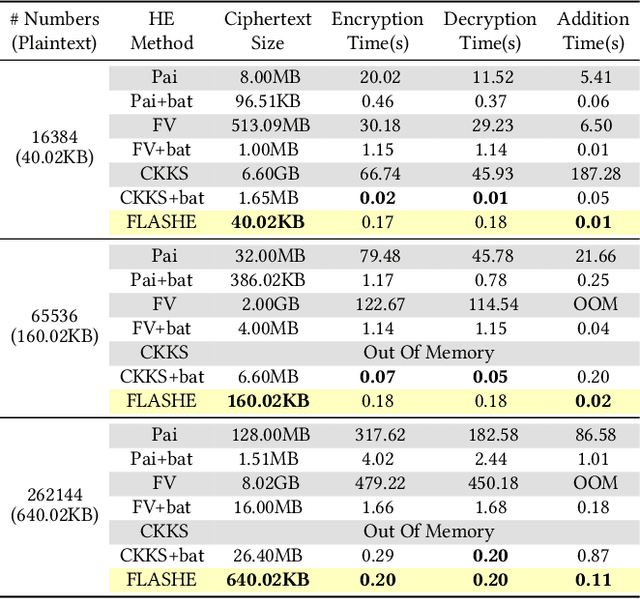
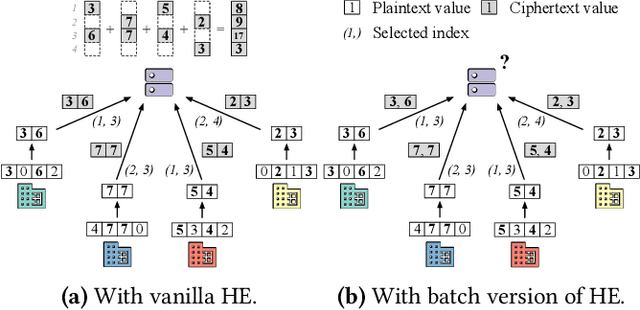
Homomorphic encryption (HE) is a promising privacy-preserving technique for cross-silo federated learning (FL), where organizations perform collaborative model training on decentralized data. Despite the strong privacy guarantee, general HE schemes result in significant computation and communication overhead. Prior works employ batch encryption to address this problem, but it is still suboptimal in mitigating communication overhead and is incompatible with sparsification techniques. In this paper, we propose FLASHE, an HE scheme tailored for cross-silo FL. To capture the minimum requirements of security and functionality, FLASHE drops the asymmetric-key design and only involves modular addition operations with random numbers. Depending on whether to accommodate sparsification techniques, FLASHE is optimized in computation efficiency with different approaches. We have implemented FLASHE as a pluggable module atop FATE, an industrial platform for cross-silo FL. Compared to plaintext training, FLASHE slightly increases the training time by $\leq6\%$, with no communication overhead.
System Optimization in Synchronous Federated Training: A Survey
Sep 12, 2021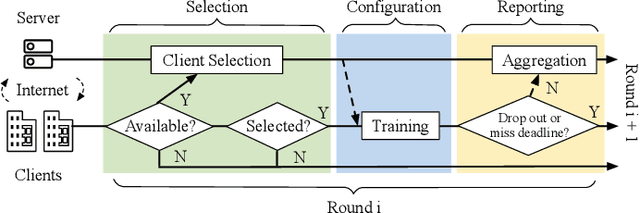
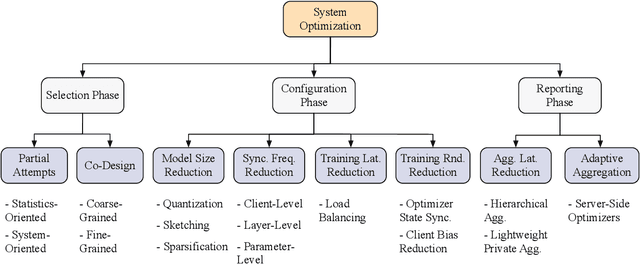
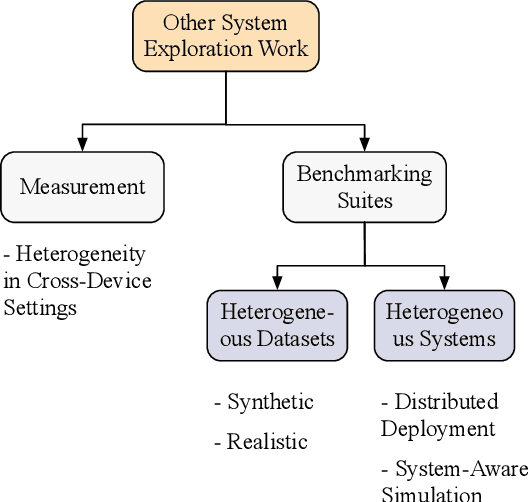
The unprecedented demand for collaborative machine learning in a privacy-preserving manner gives rise to a novel machine learning paradigm called federated learning (FL). Given a sufficient level of privacy guarantees, the practicality of an FL system mainly depends on its time-to-accuracy performance during the training process. Despite bearing some resemblance with traditional distributed training, FL has four distinct challenges that complicate the optimization towards shorter time-to-accuracy: information deficiency, coupling for contrasting factors, client heterogeneity, and huge configuration space. Motivated by the need for inspiring related research, in this paper we survey highly relevant attempts in the FL literature and organize them by the related training phases in the standard workflow: selection, configuration, and reporting. We also review exploratory work including measurement studies and benchmarking tools to friendly support FL developers. Although a few survey articles on FL already exist, our work differs from them in terms of the focus, classification, and implications.