 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNoise-Injected Spiking Graph Convolution for Energy-Efficient 3D Point Cloud Denoising
Feb 27, 2025



Spiking neural networks (SNNs), inspired by the spiking computation paradigm of the biological neural systems, have exhibited superior energy efficiency in 2D classification tasks over traditional artificial neural networks (ANNs). However, the regression potential of SNNs has not been well explored, especially in 3D point cloud processing.In this paper, we propose noise-injected spiking graph convolutional networks to leverage the full regression potential of SNNs in 3D point cloud denoising. Specifically, we first emulate the noise-injected neuronal dynamics to build noise-injected spiking neurons. On this basis, we design noise-injected spiking graph convolution for promoting disturbance-aware spiking representation learning on 3D points. Starting from the spiking graph convolution, we build two SNN-based denoising networks. One is a purely spiking graph convolutional network, which achieves low accuracy loss compared with some ANN-based alternatives, while resulting in significantly reduced energy consumption on two benchmark datasets, PU-Net and PC-Net. The other is a hybrid architecture that combines ANN-based learning with a high performance-efficiency trade-off in just a few time steps. Our work lights up SNN's potential for 3D point cloud denoising, injecting new perspectives of exploring the deployment on neuromorphic chips while paving the way for developing energy-efficient 3D data acquisition devices.
Hierarchical Image-Goal Navigation in Real Crowded Scenarios
Aug 13, 2021

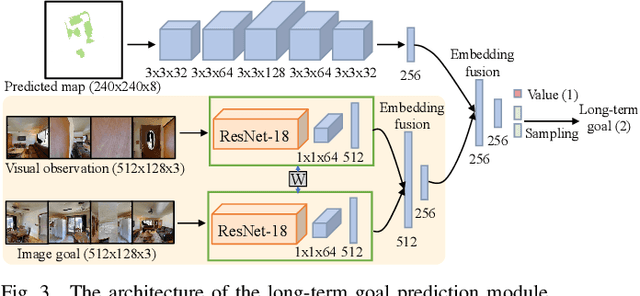

This work studies the problem of image-goal navigation, which entails guiding robots with noisy sensors and controls through real crowded environments. Recent fruitful approaches rely on deep reinforcement learning and learn navigation policies in simulation environments that are much simpler in complexity than real environments. Directly transferring these trained policies to real environments can be extremely challenging or even dangerous. We tackle this problem with a hierarchical navigation method composed of four decoupled modules. The first module maintains an obstacle map during robot navigation. The second one predicts a long-term goal on the real-time map periodically. The third one plans collision-free command sets for navigating to long-term goals, while the final module stops the robot properly near the goal image. The four modules are developed separately to suit the image-goal navigation in real crowded scenarios. In addition, the hierarchical decomposition decouples the learning of navigation goal planning, collision avoidance and navigation ending prediction, which cuts down the search space during navigation training and helps improve the generalization to previously unseen real scenes. We evaluate the method in both a simulator and the real world with a mobile robot. The results show that our method outperforms several navigation baselines and can successfully achieve navigation tasks in these scenarios.
Towards Target-Driven Visual Navigation in Indoor Scenes via Generative Imitation Learning
Sep 30, 2020

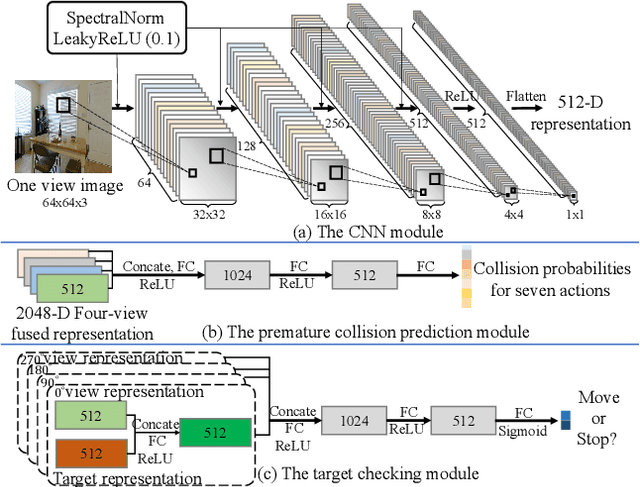

We present a target-driven navigation system to improve mapless visual navigation in indoor scenes. Our method takes a multi-view observation of a robot and a target as inputs at each time step to provide a sequence of actions that move the robot to the target without relying on odometry or GPS at runtime. The system is learned by optimizing a combinational objective encompassing three key designs. First, we propose that an agent conceives the next observation before making an action decision. This is achieved by learning a variational generative module from expert demonstrations. We then propose predicting static collision in advance, as an auxiliary task to improve safety during navigation. Moreover, to alleviate the training data imbalance problem of termination action prediction, we also introduce a target checking module to differentiate from augmenting navigation policy with a termination action. The three proposed designs all contribute to the improved training data efficiency, static collision avoidance, and navigation generalization performance, resulting in a novel target-driven mapless navigation system. Through experiments on a TurtleBot, we provide evidence that our model can be integrated into a robotic system and navigate in the real world. Videos and models can be found in the supplementary material.
Reinforcement Learning based Visual Navigation with Information-Theoretic Regularization
Dec 09, 2019
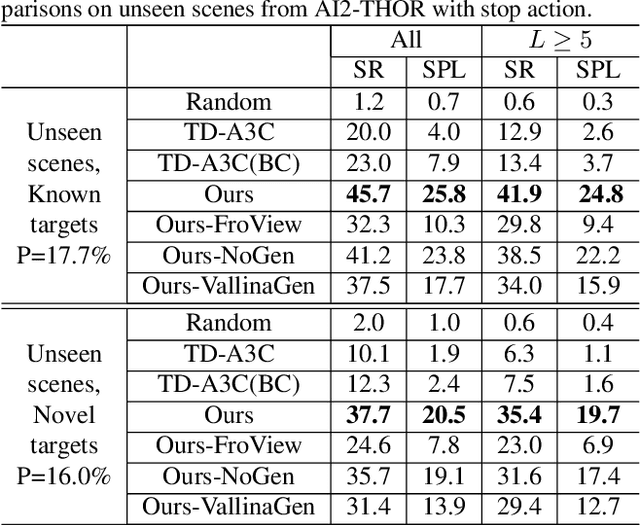
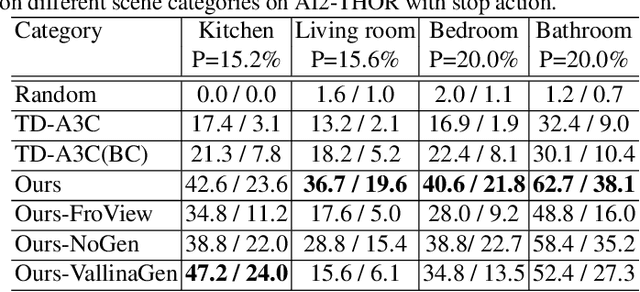

We present a target-driven navigation approach for improving the cross-target and cross-scene generalization for visual navigation. Our approach incorporates an information-theoretic regularization into a deep reinforcement learning (RL) framework. First, we present a supervised generative model to constrain the intermediate process of the RL policy, which is used to generate a future observation from a current observation and a target. Next, we predict a navigation action by analyzing the difference between the generated future and the current. Our approach takes into account the connection between current observations and targets, and the interrelation between actions and visual transformations. This results in a compact and generalizable navigation model. We perform experiments on the AI2-THOR framework and the Active Vision Dataset (AVD) and show at least 7.8% improvement in navigation success rate and 5.7% in SPL, compared to the supervised baseline, in unexplored environments.
Visual Navigation by Generating Next Expected Observations
Jun 17, 2019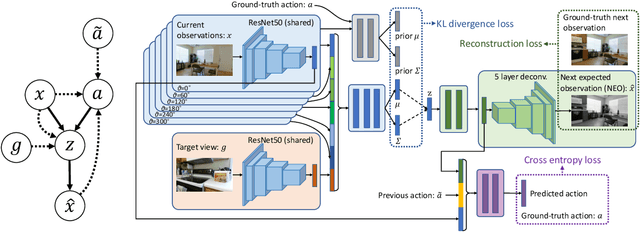
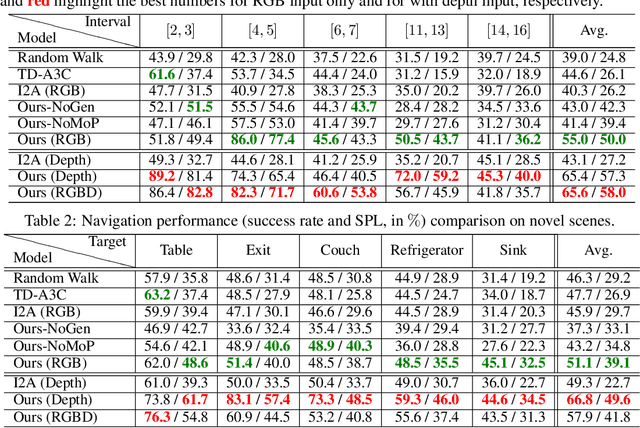
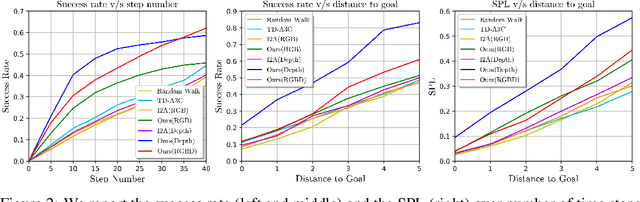
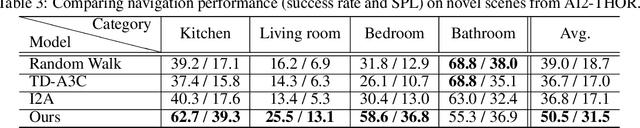
We propose a novel approach to visual navigation in unknown environments where the agent is guided by conceiving the next observations it expects to see after taking the next best action. This is achieved by learning a variational Bayesian model that generates the next expected observations (NEO) conditioned on the current observations of the agent and the target view. Our approach predicts the next best action based on the current observation and NEO. Our generative model is learned through optimizing a variational objective encompassing two key designs. First, the latent distribution is conditioned on current observations and target view, supporting model-based, target-driven navigation. Second, the latent space is modeled with a Mixture of Gaussians conditioned on the current observation and next best action. Our use of mixture-of-posteriors prior effectively alleviates the issue of over-regularized latent space, thus facilitating model generalization in novel scenes. Moreover, the NEO generation models the forward dynamics of the agent-environment interaction, which improves the quality of approximate inference and hence benefits data efficiency. We have conducted extensive evaluations on both real-world and synthetic benchmarks, and show that our model outperforms the state-of-the-art RL-based methods significantly in terms of success rate, data efficiency, and cross-scene generalization.