 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVecQ: Minimal Loss DNN Model Compression With Vectorized Weight Quantization
Paper and Code
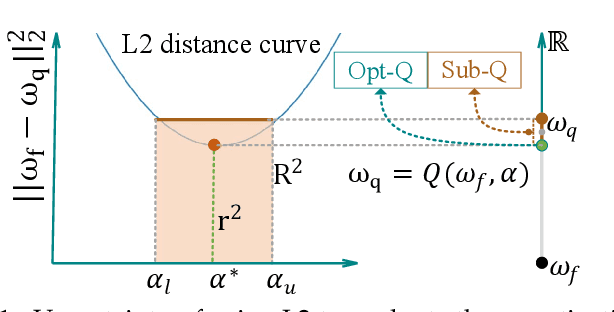
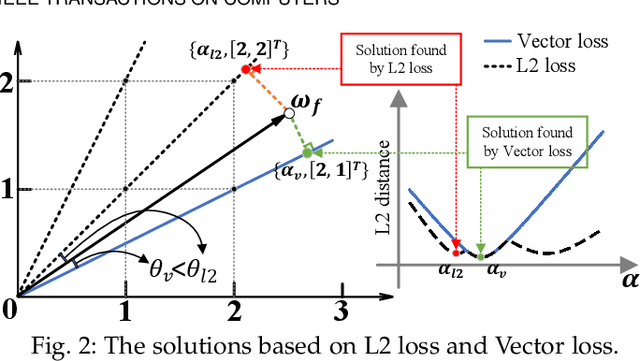
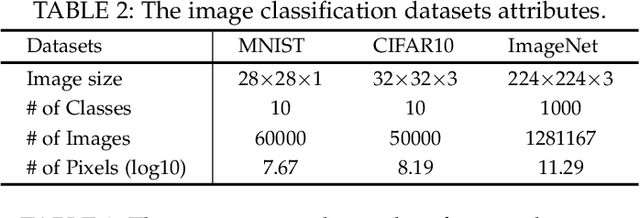
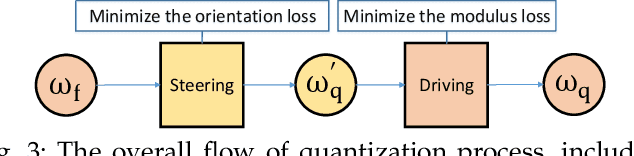
Quantization has been proven to be an effective method for reducing the computing and/or storage cost of DNNs. However, the trade-off between the quantization bitwidth and final accuracy is complex and non-convex, which makes it difficult to be optimized directly. Minimizing direct quantization loss (DQL) of the coefficient data is an effective local optimization method, but previous works often neglect the accurate control of the DQL, resulting in a higher loss of the final DNN model accuracy. In this paper, we propose a novel metric called Vector Loss. Based on this new metric, we develop a new quantization solution called VecQ, which can guarantee minimal direct quantization loss and better model accuracy. In addition, in order to speed up the proposed quantization process during model training, we accelerate the quantization process with a parameterized probability estimation method and template-based derivation calculation. We evaluate our proposed algorithm on MNIST, CIFAR, ImageNet, IMDB movie review and THUCNews text data sets with numerical DNN models. The results demonstrate that our proposed quantization solution is more accurate and effective than the state-of-the-art approaches yet with more flexible bitwidth support. Moreover, the evaluation of our quantized models on Saliency Object Detection (SOD) tasks maintains comparable feature extraction quality with up to 16$\times$ weight size reduction.