 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Joint-Dimensional Search with Solution Space Regularization for Real-Time Semantic Segmentation
Aug 10, 2022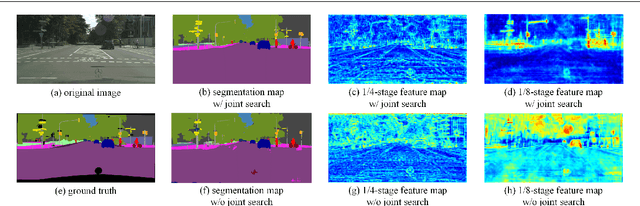
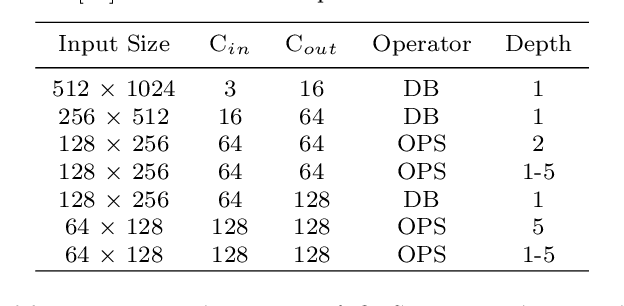
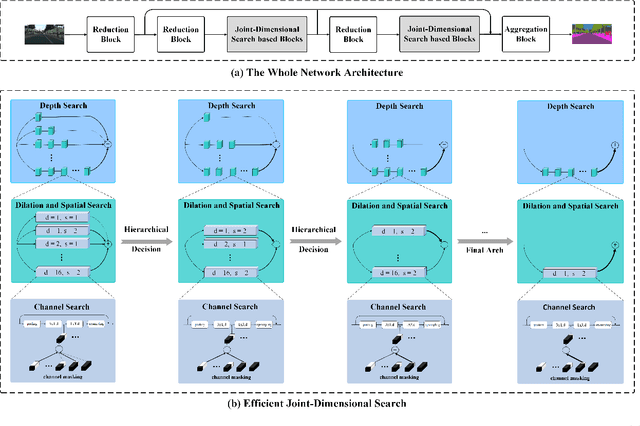
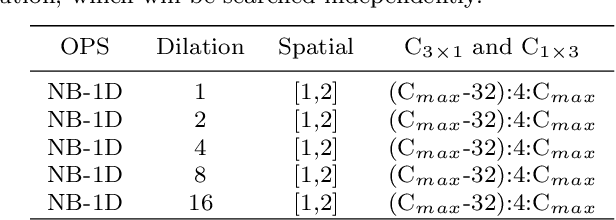
Semantic segmentation is a popular research topic in computer vision, and many efforts have been made on it with impressive results. In this paper, we intend to search an optimal network structure that can run in real-time for this problem. Towards this goal, we jointly search the depth, channel, dilation rate and feature spatial resolution, which results in a search space consisting of about 2.78*10^324 possible choices. To handle such a large search space, we leverage differential architecture search methods. However, the architecture parameters searched using existing differential methods need to be discretized, which causes the discretization gap between the architecture parameters found by the differential methods and their discretized version as the final solution for the architecture search. Hence, we relieve the problem of discretization gap from the innovative perspective of solution space regularization. Specifically, a novel Solution Space Regularization (SSR) loss is first proposed to effectively encourage the supernet to converge to its discrete one. Then, a new Hierarchical and Progressive Solution Space Shrinking method is presented to further achieve high efficiency of searching. In addition, we theoretically show that the optimization of SSR loss is equivalent to the L_0-norm regularization, which accounts for the improved search-evaluation gap. Comprehensive experiments show that the proposed search scheme can efficiently find an optimal network structure that yields an extremely fast speed (175 FPS) of segmentation with a small model size (1 M) while maintaining comparable accuracy.
EADNet: Efficient Asymmetric Dilated Network for Semantic Segmentation
Mar 16, 2021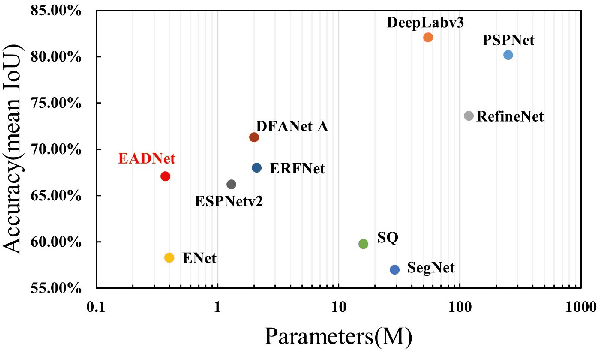
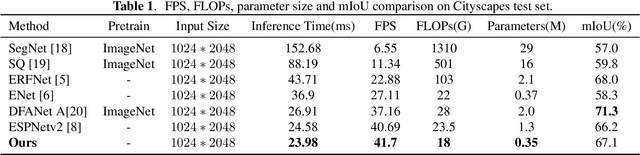
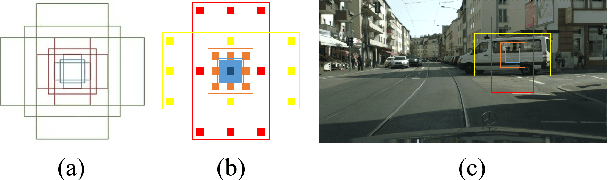
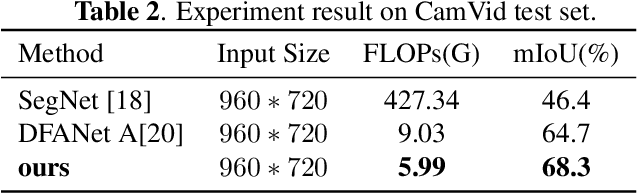
Due to real-time image semantic segmentation needs on power constrained edge devices, there has been an increasing desire to design lightweight semantic segmentation neural network, to simultaneously reduce computational cost and increase inference speed. In this paper, we propose an efficient asymmetric dilated semantic segmentation network, named EADNet, which consists of multiple developed asymmetric convolution branches with different dilation rates to capture the variable shapes and scales information of an image. Specially, a multi-scale multi-shape receptive field convolution (MMRFC) block with only a few parameters is designed to capture such information. Experimental results on the Cityscapes dataset demonstrate that our proposed EADNet achieves segmentation mIoU of 67.1 with smallest number of parameters (only 0.35M) among mainstream lightweight semantic segmentation networks.