 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCLIP-UP: CLIP-Based Unanswerable Problem Detection for Visual Question Answering
Jan 02, 2025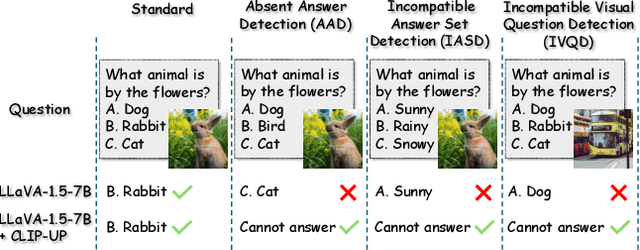
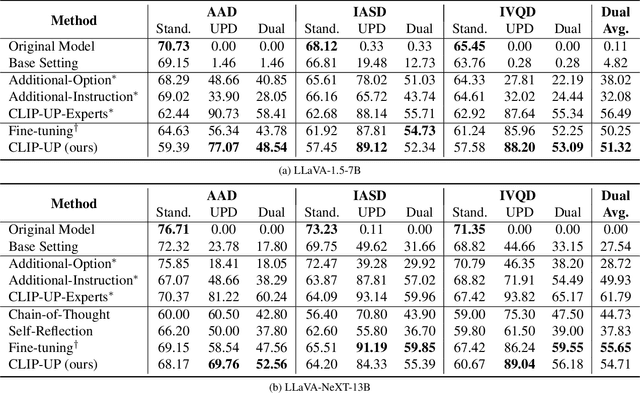
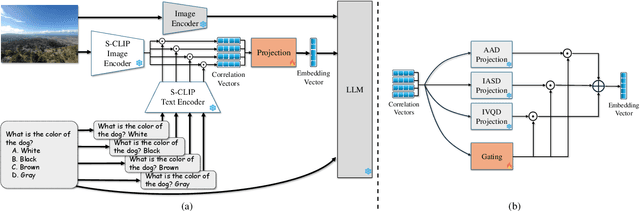
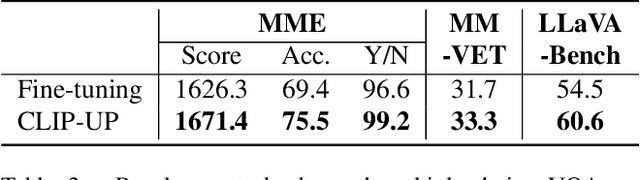
Recent Vision-Language Models (VLMs) have demonstrated remarkable capabilities in visual understanding and reasoning, and in particular on multiple-choice Visual Question Answering (VQA). Still, these models can make distinctly unnatural errors, for example, providing (wrong) answers to unanswerable VQA questions, such as questions asking about objects that do not appear in the image. To address this issue, we propose CLIP-UP: CLIP-based Unanswerable Problem detection, a novel lightweight method for equipping VLMs with the ability to withhold answers to unanswerable questions. By leveraging CLIP to extract question-image alignment information, CLIP-UP requires only efficient training of a few additional layers, while keeping the original VLMs' weights unchanged. Tested across LLaVA models, CLIP-UP achieves state-of-the-art results on the MM-UPD benchmark for assessing unanswerability in multiple-choice VQA, while preserving the original performance on other tasks.
Multi-Phase Relaxation Labeling for Square Jigsaw Puzzle Solving
Mar 26, 2023We present a novel method for solving square jigsaw puzzles based on global optimization. The method is fully automatic, assumes no prior information, and can handle puzzles with known or unknown piece orientation. At the core of the optimization process is nonlinear relaxation labeling, a well-founded approach for deducing global solutions from local constraints, but unlike the classical scheme here we propose a multi-phase approach that guarantees convergence to feasible puzzle solutions. Next to the algorithmic novelty, we also present a new compatibility function for the quantification of the affinity between adjacent puzzle pieces. Competitive results and the advantage of the multi-phase approach are demonstrated on standard datasets.
* 10 pages, 7 figures. Published in Proceedings of the 18th International Joint Conference on Computer Vision, Imaging and Computer Graphics Theory and Applications - Volume 4 VISAPP: VISAPP, 785-795, 2023