 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCLIP-UP: CLIP-Based Unanswerable Problem Detection for Visual Question Answering
Jan 02, 2025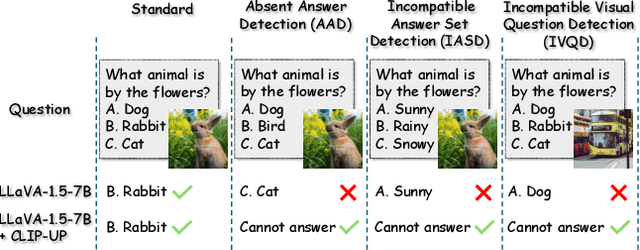
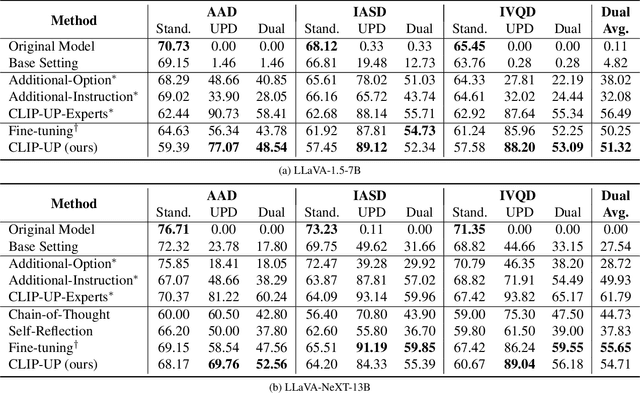
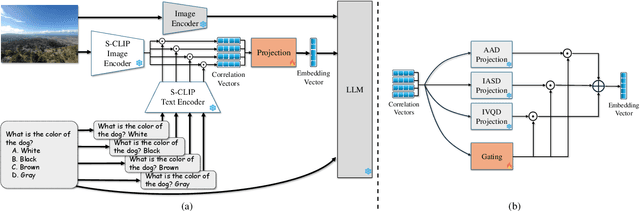
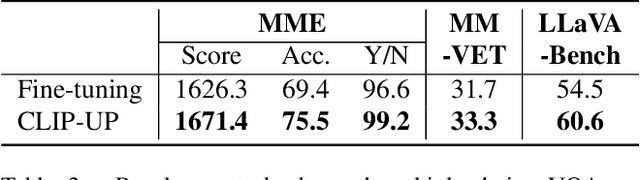
Recent Vision-Language Models (VLMs) have demonstrated remarkable capabilities in visual understanding and reasoning, and in particular on multiple-choice Visual Question Answering (VQA). Still, these models can make distinctly unnatural errors, for example, providing (wrong) answers to unanswerable VQA questions, such as questions asking about objects that do not appear in the image. To address this issue, we propose CLIP-UP: CLIP-based Unanswerable Problem detection, a novel lightweight method for equipping VLMs with the ability to withhold answers to unanswerable questions. By leveraging CLIP to extract question-image alignment information, CLIP-UP requires only efficient training of a few additional layers, while keeping the original VLMs' weights unchanged. Tested across LLaVA models, CLIP-UP achieves state-of-the-art results on the MM-UPD benchmark for assessing unanswerability in multiple-choice VQA, while preserving the original performance on other tasks.
Conditional Balance: Improving Multi-Conditioning Trade-Offs in Image Generation
Dec 25, 2024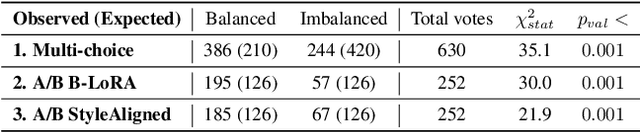
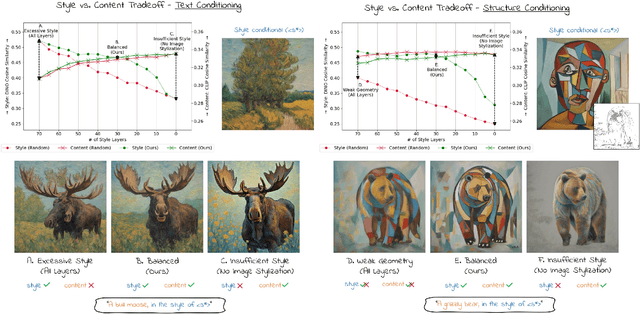
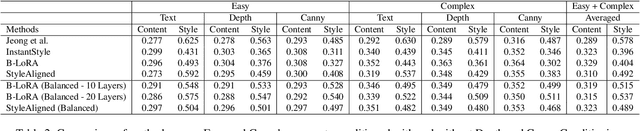
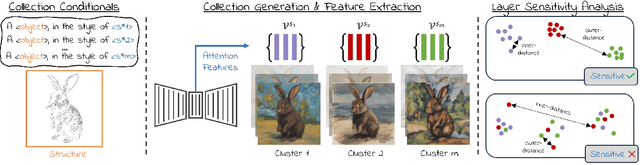
Balancing content fidelity and artistic style is a pivotal challenge in image generation. While traditional style transfer methods and modern Denoising Diffusion Probabilistic Models (DDPMs) strive to achieve this balance, they often struggle to do so without sacrificing either style, content, or sometimes both. This work addresses this challenge by analyzing the ability of DDPMs to maintain content and style equilibrium. We introduce a novel method to identify sensitivities within the DDPM attention layers, identifying specific layers that correspond to different stylistic aspects. By directing conditional inputs only to these sensitive layers, our approach enables fine-grained control over style and content, significantly reducing issues arising from over-constrained inputs. Our findings demonstrate that this method enhances recent stylization techniques by better aligning style and content, ultimately improving the quality of generated visual content.
VCR: Video representation for Contextual Retrieval
Feb 12, 2024



Streamlining content discovery within media archives requires integrating advanced data representations and effective visualization techniques for clear communication of video topics to users. The proposed system addresses the challenge of efficiently navigating large video collections by exploiting a fusion of visual, audio, and textual features to accurately index and categorize video content through a text-based method. Additionally, semantic embeddings are employed to provide contextually relevant information and recommendations to users, resulting in an intuitive and engaging exploratory experience over our topics ontology map using OpenAI GPT-4.
CAST: Character labeling in Animation using Self-supervision by Tracking
Jan 19, 2022Cartoons and animation domain videos have very different characteristics compared to real-life images and videos. In addition, this domain carries a large variability in styles. Current computer vision and deep-learning solutions often fail on animated content because they were trained on natural images. In this paper we present a method to refine a semantic representation suitable for specific animated content. We first train a neural network on a large-scale set of animation videos and use the mapping to deep features as an embedding space. Next, we use self-supervision to refine the representation for any specific animation style by gathering many examples of animated characters in this style, using a multi-object tracking. These examples are used to define triplets for contrastive loss training. The refined semantic space allows better clustering of animated characters even when they have diverse manifestations. Using this space we can build dictionaries of characters in an animation videos, and define specialized classifiers for specific stylistic content (e.g., characters in a specific animation series) with very little user effort. These classifiers are the basis for automatically labeling characters in animation videos. We present results on a collection of characters in a variety of animation styles.